 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaToolAgent: Towards Generalizable Tool Usage in LLMs through Meta-Learning
Jan 19, 2026Tool learning is increasingly important for large language models (LLMs) to effectively coordinate and utilize a diverse set of tools in order to solve complex real-world tasks. By selecting and integrating appropriate tools, LLMs extend their capabilities beyond pure language understanding to perform specialized functions. However, existing methods for tool selection often focus on limited tool sets and struggle to generalize to novel tools encountered in practical deployments. To address these challenges, we introduce a comprehensive dataset spanning 7 domains, containing 155 tools and 9,377 question-answer pairs, which simulates realistic integration scenarios. Additionally, we propose MetaToolAgent (MTA), a meta-learning approach designed to improve cross-tool generalization. Experimental results show that MTA significantly outperforms baseline methods on unseen tools, demonstrating its promise for building flexible and scalable systems that require dynamic tool coordination.
XLinear: A Lightweight and Accurate MLP-Based Model for Long-Term Time Series Forecasting with Exogenous Inputs
Jan 14, 2026Despite the prevalent assumption of uniform variable importance in long-term time series forecasting models, real world applications often exhibit asymmetric causal relationships and varying data acquisition costs. Specifically, cost-effective exogenous data (e.g., local weather) can unilaterally influence dynamics of endogenous variables, such as lake surface temperature. Exploiting these links enables more effective forecasts when exogenous inputs are readily available. Transformer-based models capture long-range dependencies but incur high computation and suffer from permutation invariance. Patch-based variants improve efficiency yet can miss local temporal patterns. To efficiently exploit informative signals across both the temporal dimension and relevant exogenous variables, this study proposes XLinear, a lightweight time series forecasting model built upon MultiLayer Perceptrons (MLPs). XLinear uses a global token derived from an endogenous variable as a pivotal hub for interacting with exogenous variables, and employs MLPs with sigmoid activation to extract both temporal patterns and variate-wise dependencies. Its prediction head then integrates these signals to forecast the endogenous series. We evaluate XLinear on seven standard benchmarks and five real-world datasets with exogenous inputs. Compared with state-of-the-art models, XLinear delivers superior accuracy and efficiency for both multivariate forecasts and univariate forecasts influenced by exogenous inputs.
Unbiased Reasoning for Knowledge-Intensive Tasks in Large Language Models via Conditional Front-Door Adjustment
Aug 23, 2025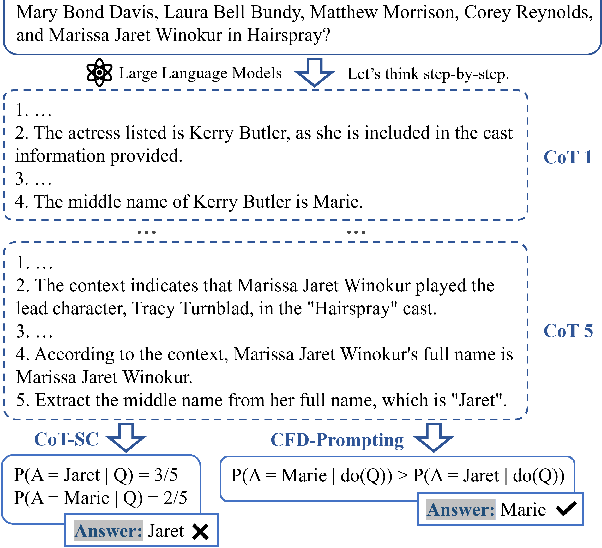
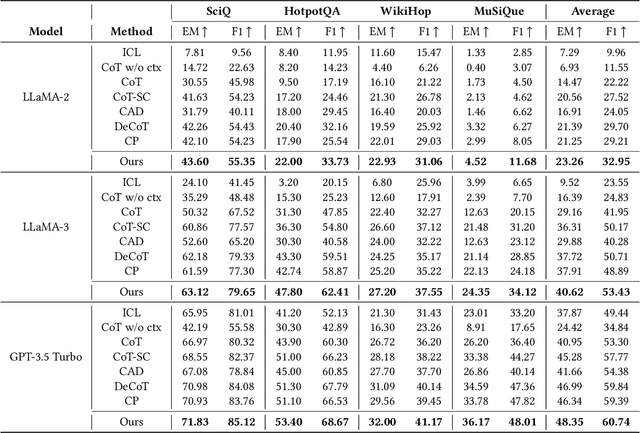
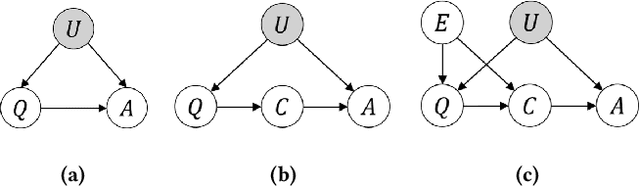
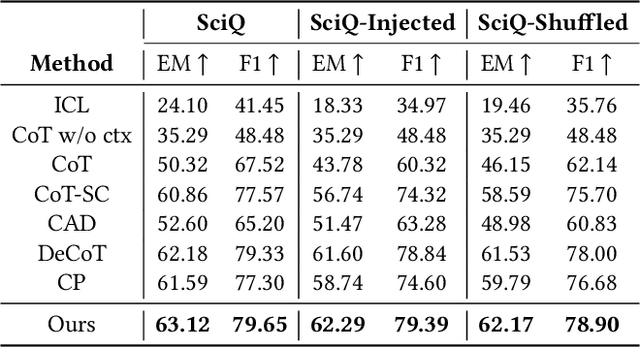
Large Language Models (LLMs) have shown impressive capabilities in natural language processing but still struggle to perform well on knowledge-intensive tasks that require deep reasoning and the integration of external knowledge. Although methods such as Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) have been proposed to enhance LLMs with external knowledge, they still suffer from internal bias in LLMs, which often leads to incorrect answers. In this paper, we propose a novel causal prompting framework, Conditional Front-Door Prompting (CFD-Prompting), which enables the unbiased estimation of the causal effect between the query and the answer, conditional on external knowledge, while mitigating internal bias. By constructing counterfactual external knowledge, our framework simulates how the query behaves under varying contexts, addressing the challenge that the query is fixed and is not amenable to direct causal intervention. Compared to the standard front-door adjustment, the conditional variant operates under weaker assumptions, enhancing both robustness and generalisability of the reasoning process. Extensive experiments across multiple LLMs and benchmark datasets demonstrate that CFD-Prompting significantly outperforms existing baselines in both accuracy and robustness.
Rule-Assisted Attribute Embedding
Jun 10, 2025Recommendation systems often overlook the rich attribute information embedded in property graphs, limiting their effectiveness. Existing graph convolutional network (GCN) models either ignore attributes or rely on simplistic <user, item, attribute> triples, failing to capture deeper semantic structures. We propose RAE (Rule- Assisted Approach for Attribute Embedding), a novel method that improves recommendations by mining semantic rules from property graphs to guide attribute embedding. RAE performs rule-based random walks to generate enriched attribute representations, which are integrated into GCNs. Experiments on real-world datasets (BlogCatalog, Flickr) show that RAE outperforms state-of-the-art baselines by 10.6% on average in Recall@20 and NDCG@20. RAE also demonstrates greater robustness to sparse data and missing attributes, highlighting the value of leveraging structured attribute information in recommendation tasks.
Knowledge prompt chaining for semantic modeling
Jan 15, 2025The task of building semantics for structured data such as CSV, JSON, and XML files is highly relevant in the knowledge representation field. Even though we have a vast of structured data on the internet, mapping them to domain ontologies to build semantics for them is still very challenging as it requires the construction model to understand and learn graph-structured knowledge. Otherwise, the task will require human beings' effort and cost. In this paper, we proposed a novel automatic semantic modeling framework: Knowledge Prompt Chaining. It can serialize the graph-structured knowledge and inject it into the LLMs properly in a Prompt Chaining architecture. Through this knowledge injection and prompting chaining, the model in our framework can learn the structure information and latent space of the graph and generate the semantic labels and semantic graphs following the chains' insturction naturally. Based on experimental results, our method achieves better performance than existing leading techniques, despite using reduced structured input data.
Counterfactual Samples Constructing and Training for Commonsense Statements Estimation
Dec 29, 2024



Plausibility Estimation (PE) plays a crucial role for enabling language models to objectively comprehend the real world. While large language models (LLMs) demonstrate remarkable capabilities in PE tasks but sometimes produce trivial commonsense errors due to the complexity of commonsense knowledge. They lack two key traits of an ideal PE model: a) Language-explainable: relying on critical word segments for decisions, and b) Commonsense-sensitive: detecting subtle linguistic variations in commonsense. To address these issues, we propose a novel model-agnostic method, referred to as Commonsense Counterfactual Samples Generating (CCSG). By training PE models with CCSG, we encourage them to focus on critical words, thereby enhancing both their language-explainable and commonsense-sensitive capabilities. Specifically, CCSG generates counterfactual samples by strategically replacing key words and introducing low-level dropout within sentences. These counterfactual samples are then incorporated into a sentence-level contrastive training framework to further enhance the model's learning process. Experimental results across nine diverse datasets demonstrate the effectiveness of CCSG in addressing commonsense reasoning challenges, with our CCSG method showing 3.07% improvement against the SOTA methods.
Causal Effect Estimation using identifiable Variational AutoEncoder with Latent Confounders and Post-Treatment Variables
Aug 13, 2024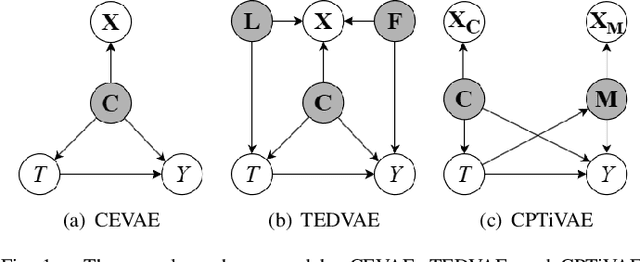
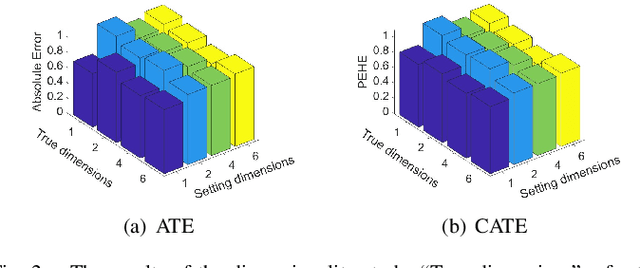
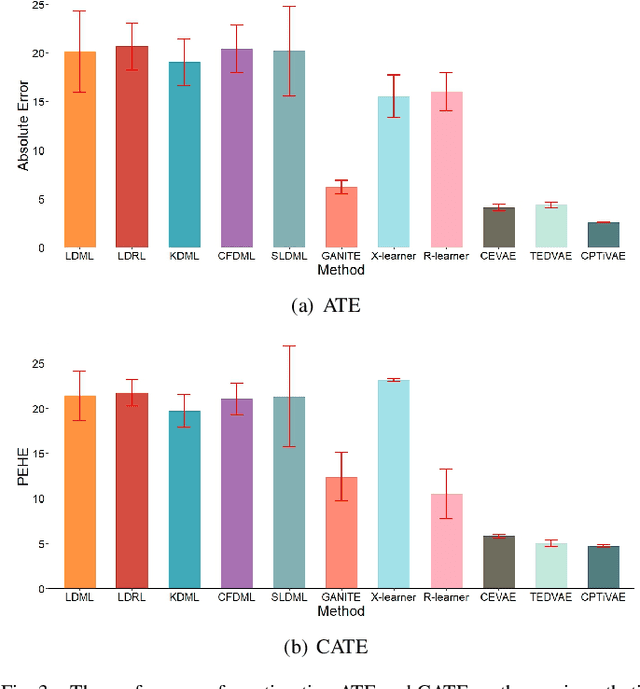
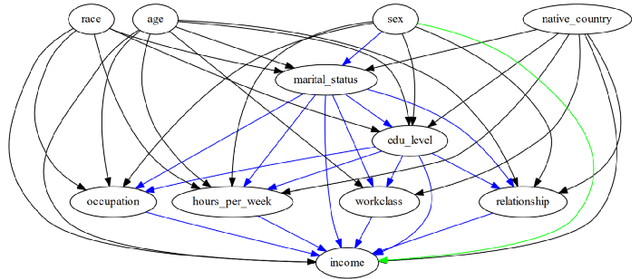
Estimating causal effects from observational data is challenging, especially in the presence of latent confounders. Much work has been done on addressing this challenge, but most of the existing research ignores the bias introduced by the post-treatment variables. In this paper, we propose a novel method of joint Variational AutoEncoder (VAE) and identifiable Variational AutoEncoder (iVAE) for learning the representations of latent confounders and latent post-treatment variables from their proxy variables, termed CPTiVAE, to achieve unbiased causal effect estimation from observational data. We further prove the identifiability in terms of the representation of latent post-treatment variables. Extensive experiments on synthetic and semi-synthetic datasets demonstrate that the CPTiVAE outperforms the state-of-the-art methods in the presence of latent confounders and post-treatment variables. We further apply CPTiVAE to a real-world dataset to show its potential application.
Disentangled Latent Representation Learning for Tackling the Confounding M-Bias Problem in Causal Inference
Dec 08, 2023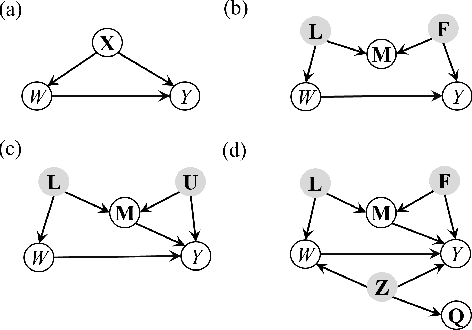
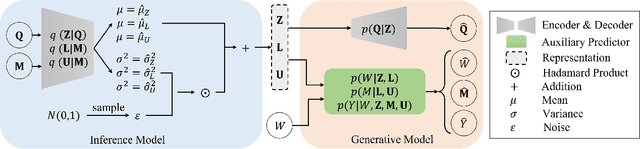

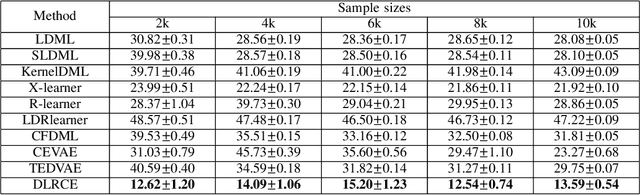
In causal inference, it is a fundamental task to estimate the causal effect from observational data. However, latent confounders pose major challenges in causal inference in observational data, for example, confounding bias and M-bias. Recent data-driven causal effect estimators tackle the confounding bias problem via balanced representation learning, but assume no M-bias in the system, thus they fail to handle the M-bias. In this paper, we identify a challenging and unsolved problem caused by a variable that leads to confounding bias and M-bias simultaneously. To address this problem with co-occurring M-bias and confounding bias, we propose a novel Disentangled Latent Representation learning framework for learning latent representations from proxy variables for unbiased Causal effect Estimation (DLRCE) from observational data. Specifically, DLRCE learns three sets of latent representations from the measured proxy variables to adjust for the confounding bias and M-bias. Extensive experiments on both synthetic and three real-world datasets demonstrate that DLRCE significantly outperforms the state-of-the-art estimators in the case of the presence of both confounding bias and M-bias.
Research And Implementation Of Drug Target Interaction Confidence Measurement Method Based On Causal Intervention
May 31, 2023The identification and discovery of drug-target Interaction (DTI) is an important step in the field of Drug research and development, which can help scientists discover new drugs and accelerate the development process. KnowledgeGraph and the related knowledge graph Embedding (KGE) model develop rapidly and show good performance in the field of drug discovery in recent years. In the task of drug target identification, the lack of authenticity and accuracy of the model will lead to the increase of misjudgment rate and the low efficiency of drug development. To solve the above problems, this study focused on the problem of drug target link prediction with knowledge mapping as the core technology, and adopted the confidence measurement method based on causal intervention to measure the triplet score, so as to improve the accuracy of drug target interaction prediction model. By comparing with the traditional Softmax and Sigmod confidence measurement methods on different KGE models, the results show that the confidence measurement method based on causal intervention can effectively improve the accuracy of DTI link prediction, especially for high-precision models. The predicted results are more conducive to guiding the design and development of followup experiments of drug development, so as to improve the efficiency of drug development.
Automatic Semantic Modeling for Structural Data Source with the Prior Knowledge from Knowledge Base
Dec 21, 2022

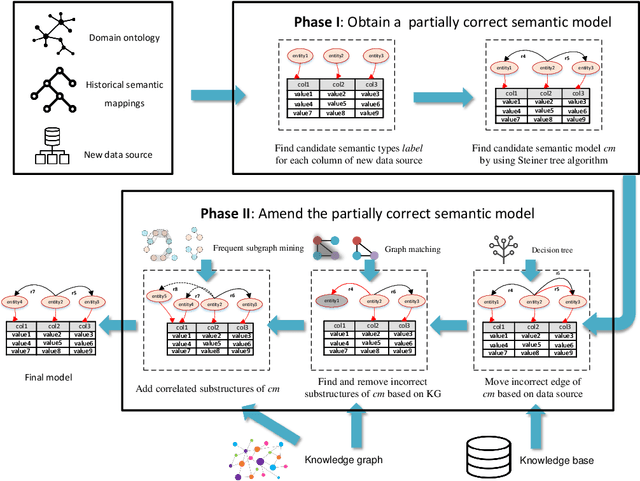

A critical step in sharing semantic content online is to map the structural data source to a public domain ontology. This problem is denoted as the Relational-To-Ontology Mapping Problem (Rel2Onto). A huge effort and expertise are required for manually modeling the semantics of data. Therefore, an automatic approach for learning the semantics of a data source is desirable. Most of the existing work studies the semantic annotation of source attributes. However, although critical, the research for automatically inferring the relationships between attributes is very limited. In this paper, we propose a novel method for semantically annotating structured data sources using machine learning, graph matching and modified frequent subgraph mining to amend the candidate model. In our work, Knowledge graph is used as prior knowledge. Our evaluation shows that our approach outperforms two state-of-the-art solutions in tricky cases where only a few semantic models are known.