 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch And Implementation Of Drug Target Interaction Confidence Measurement Method Based On Causal Intervention
May 31, 2023The identification and discovery of drug-target Interaction (DTI) is an important step in the field of Drug research and development, which can help scientists discover new drugs and accelerate the development process. KnowledgeGraph and the related knowledge graph Embedding (KGE) model develop rapidly and show good performance in the field of drug discovery in recent years. In the task of drug target identification, the lack of authenticity and accuracy of the model will lead to the increase of misjudgment rate and the low efficiency of drug development. To solve the above problems, this study focused on the problem of drug target link prediction with knowledge mapping as the core technology, and adopted the confidence measurement method based on causal intervention to measure the triplet score, so as to improve the accuracy of drug target interaction prediction model. By comparing with the traditional Softmax and Sigmod confidence measurement methods on different KGE models, the results show that the confidence measurement method based on causal intervention can effectively improve the accuracy of DTI link prediction, especially for high-precision models. The predicted results are more conducive to guiding the design and development of followup experiments of drug development, so as to improve the efficiency of drug development.
A Transformer-Based Substitute Recommendation Model Incorporating Weakly Supervised Customer Behavior Data
Nov 04, 2022



The substitute-based recommendation is widely used in E-commerce to provide better alternatives to customers. However, existing research typically uses the customer behavior signals like co-view and view-but-purchase-another to capture the substitute relationship. Despite its intuitive soundness, we find that such an approach might ignore the functionality and characteristics of products. In this paper, we adapt substitute recommendation into language matching problem by taking product title description as model input to consider product functionality. We design a new transformation method to de-noise the signals derived from production data. In addition, we consider multilingual support from the engineering point of view. Our proposed end-to-end transformer-based model achieves both successes from offline and online experiments. The proposed model has been deployed in a large-scale E-commerce website for 11 marketplaces in 6 languages. Our proposed model is demonstrated to increase revenue by 19% based on an online A/B experiment.
A Sparse Graph-Structured Lasso Mixed Model for Genetic Association with Confounding Correction
Nov 11, 2017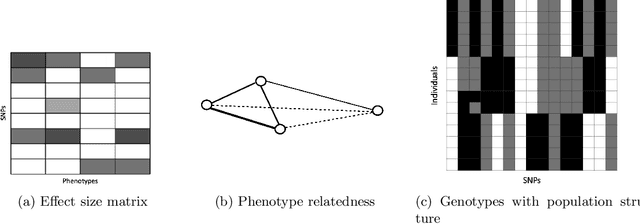

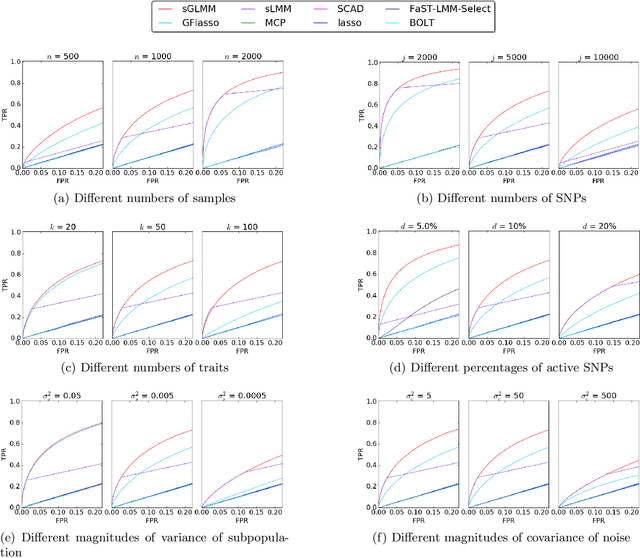
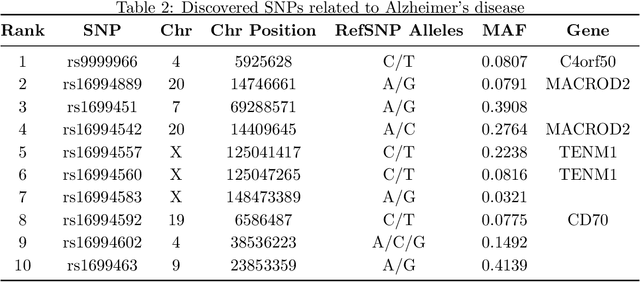
While linear mixed model (LMM) has shown a competitive performance in correcting spurious associations raised by population stratification, family structures, and cryptic relatedness, more challenges are still to be addressed regarding the complex structure of genotypic and phenotypic data. For example, geneticists have discovered that some clusters of phenotypes are more co-expressed than others. Hence, a joint analysis that can utilize such relatedness information in a heterogeneous data set is crucial for genetic modeling. We proposed the sparse graph-structured linear mixed model (sGLMM) that can incorporate the relatedness information from traits in a dataset with confounding correction. Our method is capable of uncovering the genetic associations of a large number of phenotypes together while considering the relatedness of these phenotypes. Through extensive simulation experiments, we show that the proposed model outperforms other existing approaches and can model correlation from both population structure and shared signals. Further, we validate the effectiveness of sGLMM in the real-world genomic dataset on two different species from plants and humans. In Arabidopsis thaliana data, sGLMM behaves better than all other baseline models for 63.4% traits. We also discuss the potential causal genetic variation of Human Alzheimer's disease discovered by our model and justify some of the most important genetic loci.