 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sparse Graph-Structured Lasso Mixed Model for Genetic Association with Confounding Correction
Paper and Code
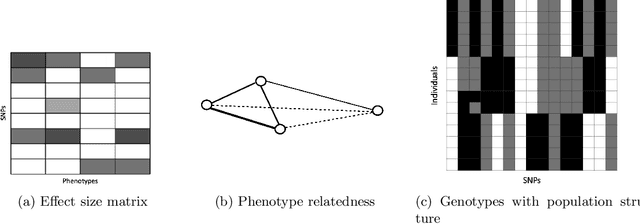

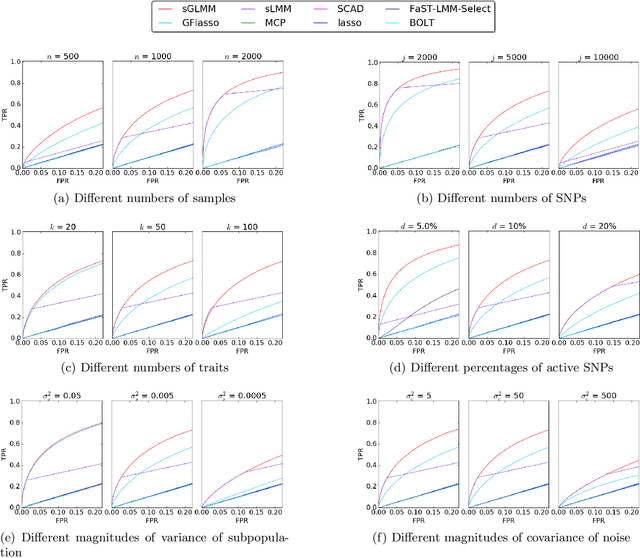
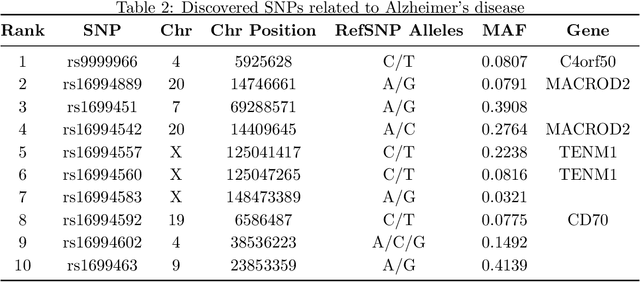
While linear mixed model (LMM) has shown a competitive performance in correcting spurious associations raised by population stratification, family structures, and cryptic relatedness, more challenges are still to be addressed regarding the complex structure of genotypic and phenotypic data. For example, geneticists have discovered that some clusters of phenotypes are more co-expressed than others. Hence, a joint analysis that can utilize such relatedness information in a heterogeneous data set is crucial for genetic modeling. We proposed the sparse graph-structured linear mixed model (sGLMM) that can incorporate the relatedness information from traits in a dataset with confounding correction. Our method is capable of uncovering the genetic associations of a large number of phenotypes together while considering the relatedness of these phenotypes. Through extensive simulation experiments, we show that the proposed model outperforms other existing approaches and can model correlation from both population structure and shared signals. Further, we validate the effectiveness of sGLMM in the real-world genomic dataset on two different species from plants and humans. In Arabidopsis thaliana data, sGLMM behaves better than all other baseline models for 63.4% traits. We also discuss the potential causal genetic variation of Human Alzheimer's disease discovered by our model and justify some of the most important genetic loci.