 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Primitives: Reusable Latent Building Blocks for Multi-Agent Systems
Feb 03, 2026While existing multi-agent systems (MAS) can handle complex problems by enabling collaboration among multiple agents, they are often highly task-specific, relying on manually crafted agent roles and interaction prompts, which leads to increased architectural complexity and limited reusability across tasks. Moreover, most MAS communicate primarily through natural language, making them vulnerable to error accumulation and instability in long-context, multi-stage interactions within internal agent histories. In this work, we propose \textbf{Agent Primitives}, a set of reusable latent building blocks for LLM-based MAS. Inspired by neural network design, where complex models are built from reusable components, we observe that many existing MAS architectures can be decomposed into a small number of recurring internal computation patterns. Based on this observation, we instantiate three primitives: Review, Voting and Selection, and Planning and Execution. All primitives communicate internally via key-value (KV) cache, which improves both robustness and efficiency by mitigating information degradation across multi-stage interactions. To enable automatic system construction, an Organizer agent selects and composes primitives for each query, guided by a lightweight knowledge pool of previously successful configurations, forming a primitive-based MAS. Experiments show that primitives-based MAS improve average accuracy by 12.0-16.5\% over single-agent baselines, reduce token usage and inference latency by approximately 3$\times$-4$\times$ compared to text-based MAS, while incurring only 1.3$\times$-1.6$\times$ overhead relative to single-agent inference and providing more stable performance across model backbones.
Controlling Output Rankings in Generative Engines for LLM-based Search
Feb 03, 2026The way customers search for and choose products is changing with the rise of large language models (LLMs). LLM-based search, or generative engines, provides direct product recommendations to users, rather than traditional online search results that require users to explore options themselves. However, these recommendations are strongly influenced by the initial retrieval order of LLMs, which disadvantages small businesses and independent creators by limiting their visibility. In this work, we propose CORE, an optimization method that \textbf{C}ontrols \textbf{O}utput \textbf{R}ankings in g\textbf{E}nerative Engines for LLM-based search. Since the LLM's interactions with the search engine are black-box, CORE targets the content returned by search engines as the primary means of influencing output rankings. Specifically, CORE optimizes retrieved content by appending strategically designed optimization content to steer the ranking of outputs. We introduce three types of optimization content: string-based, reasoning-based, and review-based, demonstrating their effectiveness in shaping output rankings. To evaluate CORE in realistic settings, we introduce ProductBench, a large-scale benchmark with 15 product categories and 200 products per category, where each product is associated with its top-10 recommendations collected from Amazon's search interface. Extensive experiments on four LLMs with search capabilities (GPT-4o, Gemini-2.5, Claude-4, and Grok-3) demonstrate that CORE achieves an average Promotion Success Rate of \textbf{91.4\% @Top-5}, \textbf{86.6\% @Top-3}, and \textbf{80.3\% @Top-1}, across 15 product categories, outperforming existing ranking manipulation methods while preserving the fluency of optimized content.
One Size, Many Fits: Aligning Diverse Group-Wise Click Preferences in Large-Scale Advertising Image Generation
Feb 02, 2026Advertising image generation has increasingly focused on online metrics like Click-Through Rate (CTR), yet existing approaches adopt a ``one-size-fits-all" strategy that optimizes for overall CTR while neglecting preference diversity among user groups. This leads to suboptimal performance for specific groups, limiting targeted marketing effectiveness. To bridge this gap, we present \textit{One Size, Many Fits} (OSMF), a unified framework that aligns diverse group-wise click preferences in large-scale advertising image generation. OSMF begins with product-aware adaptive grouping, which dynamically organizes users based on their attributes and product characteristics, representing each group with rich collective preference features. Building on these groups, preference-conditioned image generation employs a Group-aware Multimodal Large Language Model (G-MLLM) to generate tailored images for each group. The G-MLLM is pre-trained to simultaneously comprehend group features and generate advertising images. Subsequently, we fine-tune the G-MLLM using our proposed Group-DPO for group-wise preference alignment, which effectively enhances each group's CTR on the generated images. To further advance this field, we introduce the Grouped Advertising Image Preference Dataset (GAIP), the first large-scale public dataset of group-wise image preferences, including around 600K groups built from 40M users. Extensive experiments demonstrate that our framework achieves the state-of-the-art performance in both offline and online settings. Our code and datasets will be released at https://github.com/JD-GenX/OSMF.
Now You Hear Me: Audio Narrative Attacks Against Large Audio-Language Models
Jan 30, 2026Large audio-language models increasingly operate on raw speech inputs, enabling more seamless integration across domains such as voice assistants, education, and clinical triage. This transition, however, introduces a distinct class of vulnerabilities that remain largely uncharacterized. We examine the security implications of this modality shift by designing a text-to-audio jailbreak that embeds disallowed directives within a narrative-style audio stream. The attack leverages an advanced instruction-following text-to-speech (TTS) model to exploit structural and acoustic properties, thereby circumventing safety mechanisms primarily calibrated for text. When delivered through synthetic speech, the narrative format elicits restricted outputs from state-of-the-art models, including Gemini 2.0 Flash, achieving a 98.26% success rate that substantially exceeds text-only baselines. These results highlight the need for safety frameworks that jointly reason over linguistic and paralinguistic representations, particularly as speech-based interfaces become more prevalent.
Crafting Adversarial Inputs for Large Vision-Language Models Using Black-Box Optimization
Jan 08, 2026Recent advancements in Large Vision-Language Models (LVLMs) have shown groundbreaking capabilities across diverse multimodal tasks. However, these models remain vulnerable to adversarial jailbreak attacks, where adversaries craft subtle perturbations to bypass safety mechanisms and trigger harmful outputs. Existing white-box attacks methods require full model accessibility, suffer from computing costs and exhibit insufficient adversarial transferability, making them impractical for real-world, black-box settings. To address these limitations, we propose a black-box jailbreak attack on LVLMs via Zeroth-Order optimization using Simultaneous Perturbation Stochastic Approximation (ZO-SPSA). ZO-SPSA provides three key advantages: (i) gradient-free approximation by input-output interactions without requiring model knowledge, (ii) model-agnostic optimization without the surrogate model and (iii) lower resource requirements with reduced GPU memory consumption. We evaluate ZO-SPSA on three LVLMs, including InstructBLIP, LLaVA and MiniGPT-4, achieving the highest jailbreak success rate of 83.0% on InstructBLIP, while maintaining imperceptible perturbations comparable to white-box methods. Moreover, adversarial examples generated from MiniGPT-4 exhibit strong transferability to other LVLMs, with ASR reaching 64.18%. These findings underscore the real-world feasibility of black-box jailbreaks and expose critical weaknesses in the safety mechanisms of current LVLMs
Multi-Turn Jailbreaking of Aligned LLMs via Lexical Anchor Tree Search
Jan 06, 2026Most jailbreak methods achieve high attack success rates (ASR) but require attacker LLMs to craft adversarial queries and/or demand high query budgets. These resource limitations make jailbreaking expensive, and the queries generated by attacker LLMs often consist of non-interpretable random prefixes. This paper introduces Lexical Anchor Tree Search (), addressing these limitations through an attacker-LLM-free method that operates purely via lexical anchor injection. LATS reformulates jailbreaking as a breadth-first tree search over multi-turn dialogues, where each node incrementally injects missing content words from the attack goal into benign prompts. Evaluations on AdvBench and HarmBench demonstrate that LATS achieves 97-100% ASR on latest GPT, Claude, and Llama models with an average of only ~6.4 queries, compared to 20+ queries required by other methods. These results highlight conversational structure as a potent and under-protected attack surface, while demonstrating superior query efficiency in an era where high ASR is readily achievable. Our code will be released to support reproducibility.
Synthetic Data-Driven Prompt Tuning for Financial QA over Tables and Documents
Nov 14, 2025Financial documents like earning reports or balance sheets often involve long tables and multi-page reports. Large language models have become a new tool to help numerical reasoning and understanding these documents. However, prompt quality can have a major effect on how well LLMs perform these financial reasoning tasks. Most current methods tune prompts on fixed datasets of financial text or tabular data, which limits their ability to adapt to new question types or document structures, or they involve costly and manually labeled/curated dataset to help build the prompts. We introduce a self-improving prompt framework driven by data-augmented optimization. In this closed-loop process, we generate synthetic financial tables and document excerpts, verify their correctness and robustness, and then update the prompt based on the results. Specifically, our framework combines a synthetic data generator with verifiers and a prompt optimizer, where the generator produces new examples that exposes weaknesses in the current prompt, the verifiers check the validity and robustness of the produced examples, and the optimizer incrementally refines the prompt in response. By iterating these steps in a feedback cycle, our method steadily improves prompt accuracy on financial reasoning tasks without needing external labels. Evaluation on DocMath-Eval benchmark demonstrates that our system achieves higher performance in both accuracy and robustness than standard prompt methods, underscoring the value of incorporating synthetic data generation into prompt learning for financial applications.
GenoMAS: A Multi-Agent Framework for Scientific Discovery via Code-Driven Gene Expression Analysis
Jul 28, 2025Gene expression analysis holds the key to many biomedical discoveries, yet extracting insights from raw transcriptomic data remains formidable due to the complexity of multiple large, semi-structured files and the need for extensive domain expertise. Current automation approaches are often limited by either inflexible workflows that break down in edge cases or by fully autonomous agents that lack the necessary precision for rigorous scientific inquiry. GenoMAS charts a different course by presenting a team of LLM-based scientists that integrates the reliability of structured workflows with the adaptability of autonomous agents. GenoMAS orchestrates six specialized LLM agents through typed message-passing protocols, each contributing complementary strengths to a shared analytic canvas. At the heart of GenoMAS lies a guided-planning framework: programming agents unfold high-level task guidelines into Action Units and, at each juncture, elect to advance, revise, bypass, or backtrack, thereby maintaining logical coherence while bending gracefully to the idiosyncrasies of genomic data. On the GenoTEX benchmark, GenoMAS reaches a Composite Similarity Correlation of 89.13% for data preprocessing and an F$_1$ of 60.48% for gene identification, surpassing the best prior art by 10.61% and 16.85% respectively. Beyond metrics, GenoMAS surfaces biologically plausible gene-phenotype associations corroborated by the literature, all while adjusting for latent confounders. Code is available at https://github.com/Liu-Hy/GenoMAS.
GuardVal: Dynamic Large Language Model Jailbreak Evaluation for Comprehensive Safety Testing
Jul 10, 2025Jailbreak attacks reveal critical vulnerabilities in Large Language Models (LLMs) by causing them to generate harmful or unethical content. Evaluating these threats is particularly challenging due to the evolving nature of LLMs and the sophistication required in effectively probing their vulnerabilities. Current benchmarks and evaluation methods struggle to fully address these challenges, leaving gaps in the assessment of LLM vulnerabilities. In this paper, we review existing jailbreak evaluation practices and identify three assumed desiderata for an effective jailbreak evaluation protocol. To address these challenges, we introduce GuardVal, a new evaluation protocol that dynamically generates and refines jailbreak prompts based on the defender LLM's state, providing a more accurate assessment of defender LLMs' capacity to handle safety-critical situations. Moreover, we propose a new optimization method that prevents stagnation during prompt refinement, ensuring the generation of increasingly effective jailbreak prompts that expose deeper weaknesses in the defender LLMs. We apply this protocol to a diverse set of models, from Mistral-7b to GPT-4, across 10 safety domains. Our findings highlight distinct behavioral patterns among the models, offering a comprehensive view of their robustness. Furthermore, our evaluation process deepens the understanding of LLM behavior, leading to insights that can inform future research and drive the development of more secure models.
Tracing LLM Reasoning Processes with Strategic Games: A Framework for Planning, Revision, and Resource-Constrained Decision Making
Jun 13, 2025

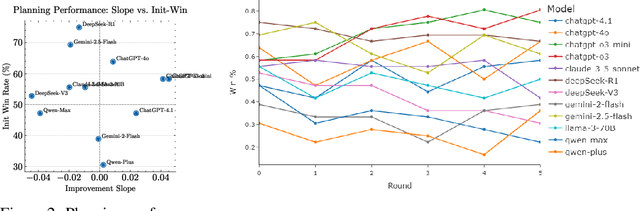
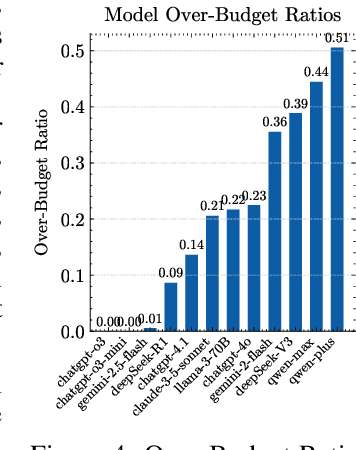
Large language models (LLMs) are increasingly used for tasks that require complex reasoning. Most benchmarks focus on final outcomes but overlook the intermediate reasoning steps - such as planning, revision, and decision making under resource constraints. We argue that measuring these internal processes is essential for understanding model behavior and improving reliability. We propose using strategic games as a natural evaluation environment: closed, rule-based systems with clear states, limited resources, and automatic feedback. We introduce a framework that evaluates LLMs along three core dimensions: planning, revision, and resource-constrained decision making. To operationalize this, we define metrics beyond win rate, including overcorrection risk rate, correction success rate, improvement slope, and over-budget ratio. In 4320 adversarial rounds across 12 leading models, ChatGPT-o3-mini achieves the top composite score, with a win rate of 74.7 percent, a correction success rate of 78.6 percent, and an improvement slope of 0.041. By contrast, Qwen-Plus, despite an overcorrection risk rate of 81.6 percent, wins only 25.6 percent of its matches - primarily due to excessive resource use. We also observe a negative correlation between overcorrection risk rate and correction success rate (Pearson r = -0.51, p = 0.093), suggesting that more frequent edits do not always improve outcomes. Our findings highlight the value of assessing not only what LLMs decide but how they arrive at those decisions