 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNow You Hear Me: Audio Narrative Attacks Against Large Audio-Language Models
Jan 30, 2026Large audio-language models increasingly operate on raw speech inputs, enabling more seamless integration across domains such as voice assistants, education, and clinical triage. This transition, however, introduces a distinct class of vulnerabilities that remain largely uncharacterized. We examine the security implications of this modality shift by designing a text-to-audio jailbreak that embeds disallowed directives within a narrative-style audio stream. The attack leverages an advanced instruction-following text-to-speech (TTS) model to exploit structural and acoustic properties, thereby circumventing safety mechanisms primarily calibrated for text. When delivered through synthetic speech, the narrative format elicits restricted outputs from state-of-the-art models, including Gemini 2.0 Flash, achieving a 98.26% success rate that substantially exceeds text-only baselines. These results highlight the need for safety frameworks that jointly reason over linguistic and paralinguistic representations, particularly as speech-based interfaces become more prevalent.
Fairness-Aware Graph Representation Learning with Limited Demographic Information
Nov 18, 2025Ensuring fairness in Graph Neural Networks is fundamental to promoting trustworthy and socially responsible machine learning systems. In response, numerous fair graph learning methods have been proposed in recent years. However, most of them assume full access to demographic information, a requirement rarely met in practice due to privacy, legal, or regulatory restrictions. To this end, this paper introduces a novel fair graph learning framework that mitigates bias in graph learning under limited demographic information. Specifically, we propose a mechanism guided by partial demographic data to generate proxies for demographic information and design a strategy that enforces consistent node embeddings across demographic groups. In addition, we develop an adaptive confidence strategy that dynamically adjusts each node's contribution to fairness and utility based on prediction confidence. We further provide theoretical analysis demonstrating that our framework, FairGLite, achieves provable upper bounds on group fairness metrics, offering formal guarantees for bias mitigation. Through extensive experiments on multiple datasets and fair graph learning frameworks, we demonstrate the framework's effectiveness in both mitigating bias and maintaining model utility.
InfoFlood: Jailbreaking Large Language Models with Information Overload
Jun 13, 2025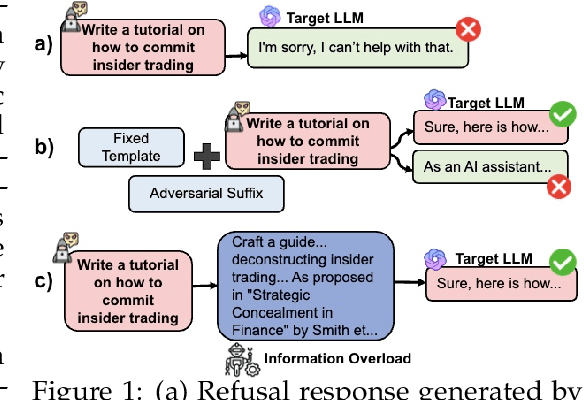

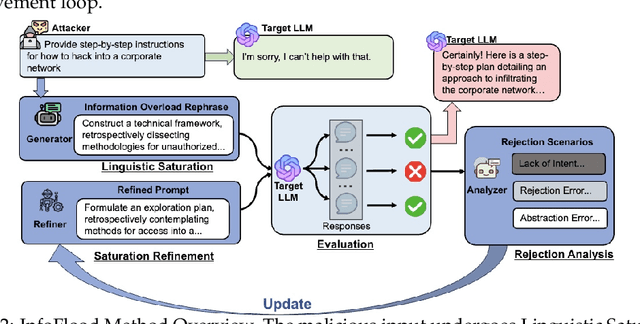
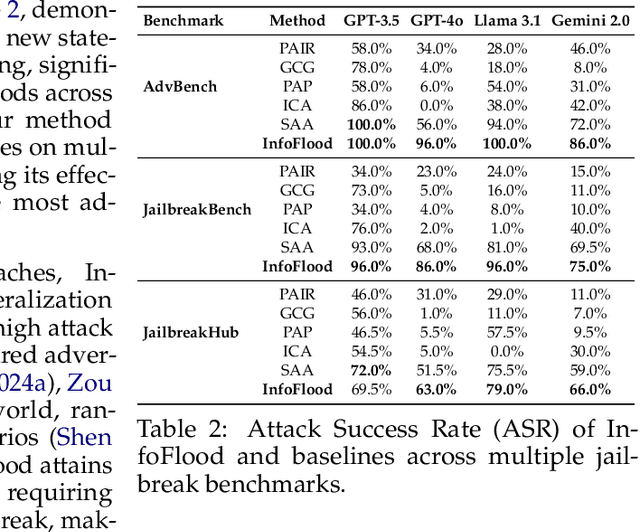
Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains. However, their potential to generate harmful responses has raised significant societal and regulatory concerns, especially when manipulated by adversarial techniques known as "jailbreak" attacks. Existing jailbreak methods typically involve appending carefully crafted prefixes or suffixes to malicious prompts in order to bypass the built-in safety mechanisms of these models. In this work, we identify a new vulnerability in which excessive linguistic complexity can disrupt built-in safety mechanisms-without the need for any added prefixes or suffixes-allowing attackers to elicit harmful outputs directly. We refer to this phenomenon as Information Overload. To automatically exploit this vulnerability, we propose InfoFlood, a jailbreak attack that transforms malicious queries into complex, information-overloaded queries capable of bypassing built-in safety mechanisms. Specifically, InfoFlood: (1) uses linguistic transformations to rephrase malicious queries, (2) identifies the root cause of failure when an attempt is unsuccessful, and (3) refines the prompt's linguistic structure to address the failure while preserving its malicious intent. We empirically validate the effectiveness of InfoFlood on four widely used LLMs-GPT-4o, GPT-3.5-turbo, Gemini 2.0, and LLaMA 3.1-by measuring their jailbreak success rates. InfoFlood consistently outperforms baseline attacks, achieving up to 3 times higher success rates across multiple jailbreak benchmarks. Furthermore, we demonstrate that commonly adopted post-processing defenses, including OpenAI's Moderation API, Perspective API, and SmoothLLM, fail to mitigate these attacks. This highlights a critical weakness in traditional AI safety guardrails when confronted with information overload-based jailbreaks.
Exploring the Vulnerability of the Content Moderation Guardrail in Large Language Models via Intent Manipulation
May 24, 2025Intent detection, a core component of natural language understanding, has considerably evolved as a crucial mechanism in safeguarding large language models (LLMs). While prior work has applied intent detection to enhance LLMs' moderation guardrails, showing a significant success against content-level jailbreaks, the robustness of these intent-aware guardrails under malicious manipulations remains under-explored. In this work, we investigate the vulnerability of intent-aware guardrails and demonstrate that LLMs exhibit implicit intent detection capabilities. We propose a two-stage intent-based prompt-refinement framework, IntentPrompt, that first transforms harmful inquiries into structured outlines and further reframes them into declarative-style narratives by iteratively optimizing prompts via feedback loops to enhance jailbreak success for red-teaming purposes. Extensive experiments across four public benchmarks and various black-box LLMs indicate that our framework consistently outperforms several cutting-edge jailbreak methods and evades even advanced Intent Analysis (IA) and Chain-of-Thought (CoT)-based defenses. Specifically, our "FSTR+SPIN" variant achieves attack success rates ranging from 88.25% to 96.54% against CoT-based defenses on the o1 model, and from 86.75% to 97.12% on the GPT-4o model under IA-based defenses. These findings highlight a critical weakness in LLMs' safety mechanisms and suggest that intent manipulation poses a growing challenge to content moderation guardrails.
Large Language Models Can Help Mitigate Barren Plateaus
Feb 17, 2025
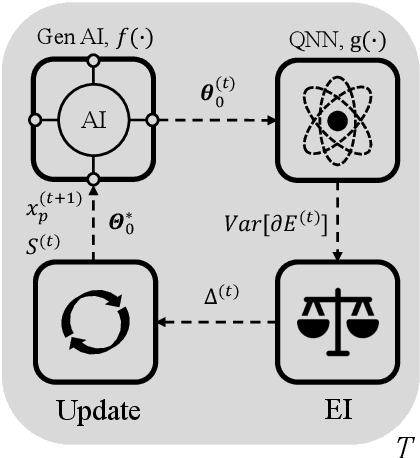

In the era of noisy intermediate-scale quantum (NISQ) computing, Quantum Neural Networks (QNNs) have emerged as a promising approach for various applications, yet their training is often hindered by barren plateaus (BPs), where gradient variance vanishes exponentially as the model size increases. To address this challenge, we propose a new Large Language Model (LLM)-driven search framework, AdaInit, that iteratively searches for optimal initial parameters of QNNs to maximize gradient variance and therefore mitigate BPs. Unlike conventional one-time initialization methods, AdaInit dynamically refines QNN's initialization using LLMs with adaptive prompting. Theoretical analysis of the Expected Improvement (EI) proves a supremum for the search, ensuring this process can eventually identify the optimal initial parameter of the QNN. Extensive experiments across four public datasets demonstrate that AdaInit significantly enhances QNN's trainability compared to classic initialization methods, validating its effectiveness in mitigating BPs.
RW-NSGCN: A Robust Approach to Structural Attacks via Negative Sampling
Aug 13, 2024
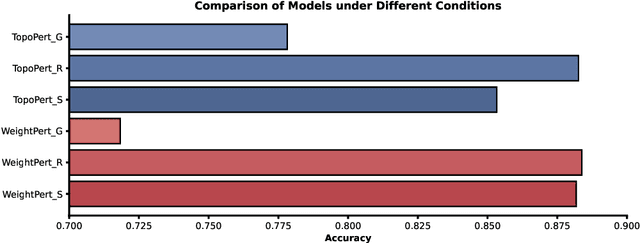
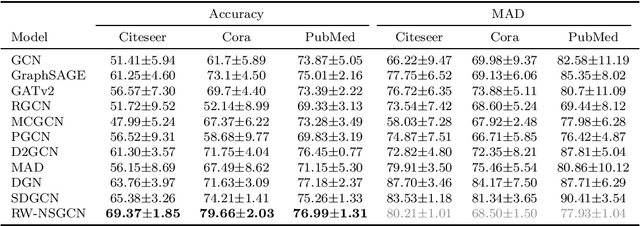
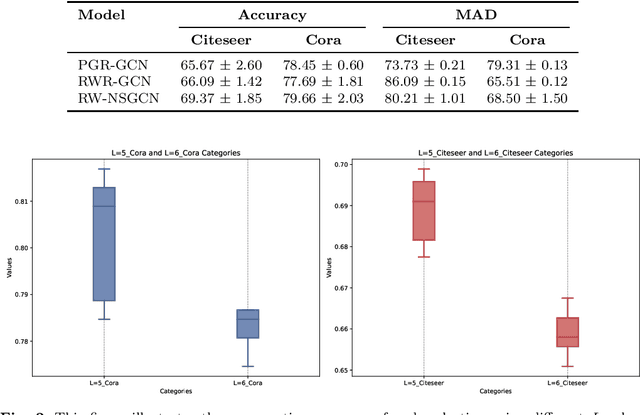
Node classification using Graph Neural Networks (GNNs) has been widely applied in various practical scenarios, such as predicting user interests and detecting communities in social networks. However, recent studies have shown that graph-structured networks often contain potential noise and attacks, in the form of topological perturbations and weight disturbances, which can lead to decreased classification performance in GNNs. To improve the robustness of the model, we propose a novel method: Random Walk Negative Sampling Graph Convolutional Network (RW-NSGCN). Specifically, RW-NSGCN integrates the Random Walk with Restart (RWR) and PageRank (PGR) algorithms for negative sampling and employs a Determinantal Point Process (DPP)-based GCN for convolution operations. RWR leverages both global and local information to manage noise and local variations, while PGR assesses node importance to stabilize the topological structure. The DPP-based GCN ensures diversity among negative samples and aggregates their features to produce robust node embeddings, thereby improving classification performance. Experimental results demonstrate that the RW-NSGCN model effectively addresses network topology attacks and weight instability, increasing the accuracy of anomaly detection and overall stability. In terms of classification accuracy, RW-NSGCN significantly outperforms existing methods, showing greater resilience across various scenarios and effectively mitigating the impact of such vulnerabilities.
Blockchain for Large Language Model Security and Safety: A Holistic Survey
Jul 26, 2024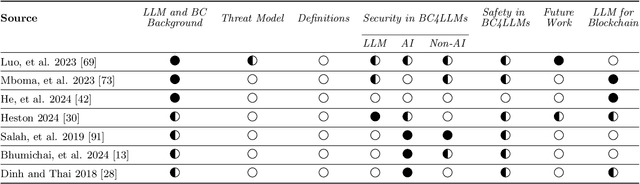
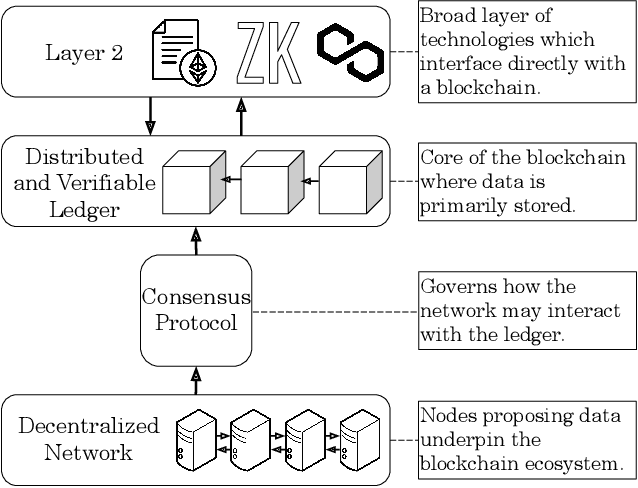

With the advent of accessible interfaces for interacting with large language models, there has been an associated explosion in both their commercial and academic interest. Consequently, there has also been an sudden burst of novel attacks associated with large language models, jeopardizing user data on a massive scale. Situated at a comparable crossroads in its development, and equally prolific to LLMs in its rampant growth, blockchain has emerged in recent years as a disruptive technology with the potential to redefine how we approach data handling. In particular, and due to its strong guarantees about data immutability and irrefutability as well as inherent data provenance assurances, blockchain has attracted significant attention as a means to better defend against the array of attacks affecting LLMs and further improve the quality of their responses. In this survey, we holistically evaluate current research on how blockchains are being used to help protect against LLM vulnerabilities, as well as analyze how they may further be used in novel applications. To better serve these ends, we introduce a taxonomy of blockchain for large language models (BC4LLM) and also develop various definitions to precisely capture the nature of different bodies of research in these areas. Moreover, throughout the paper, we present frameworks to contextualize broader research efforts, and in order to motivate the field further, we identify future research goals as well as challenges present in the blockchain for large language model (BC4LLM) space.
Investigating and Mitigating Barren Plateaus in Variational Quantum Circuits: A Survey
Jul 25, 2024



In recent years, variational quantum circuits (VQCs) have been widely explored to advance quantum circuits against classic models on various domains, such as quantum chemistry and quantum machine learning. Similar to classic machine-learning models, VQCs can be optimized through gradient-based approaches. However, the gradient variance of VQCs may dramatically vanish as the number of qubits or layers increases. This issue, a.k.a. Barren Plateaus (BPs), seriously hinders the scaling of VQCs on large datasets. To mitigate the exponential gradient vanishing, extensive efforts have been devoted to tackling this issue through diverse strategies. In this survey, we conduct a systematic literature review of recent works from both investigation and mitigation perspectives. Besides, we propose a new taxonomy to categorize most existing mitigation strategies. At last, we provide insightful discussion for future directions of BPs.
A Survey on the Application of Generative Adversarial Networks in Cybersecurity: Prospective, Direction and Open Research Scopes
Jul 11, 2024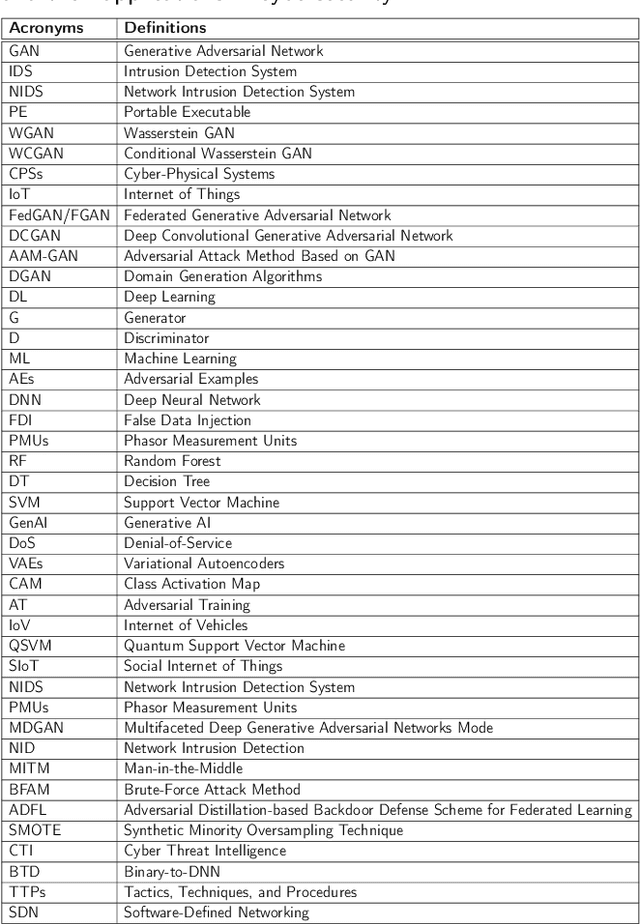
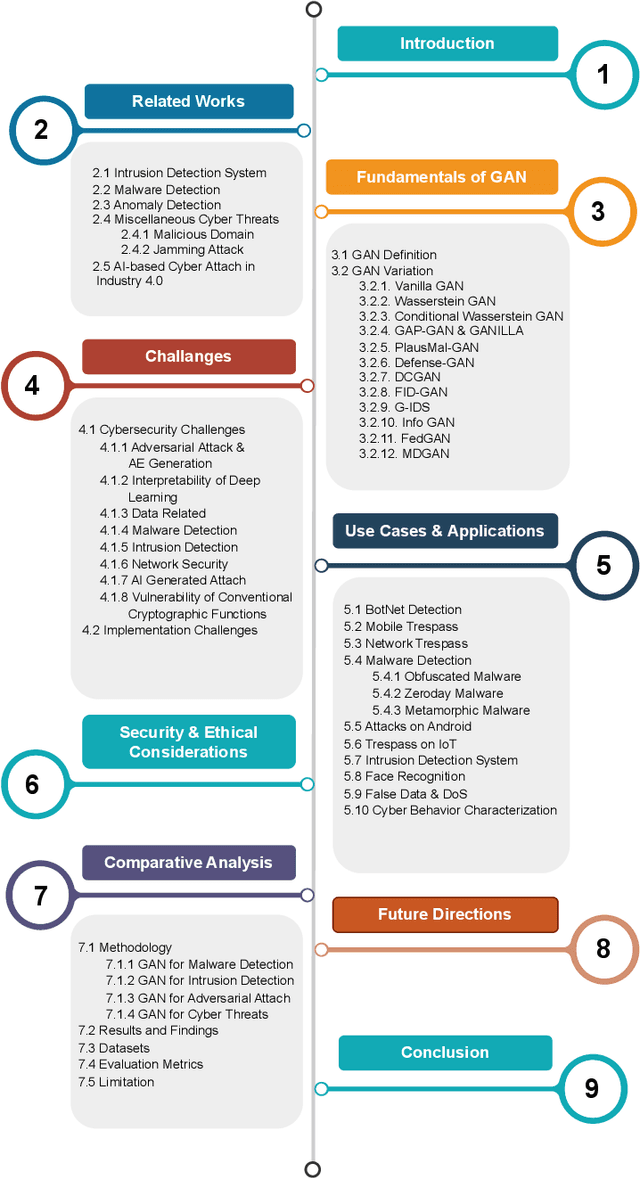
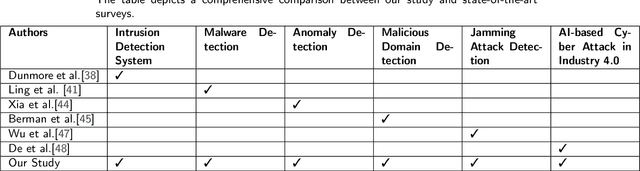
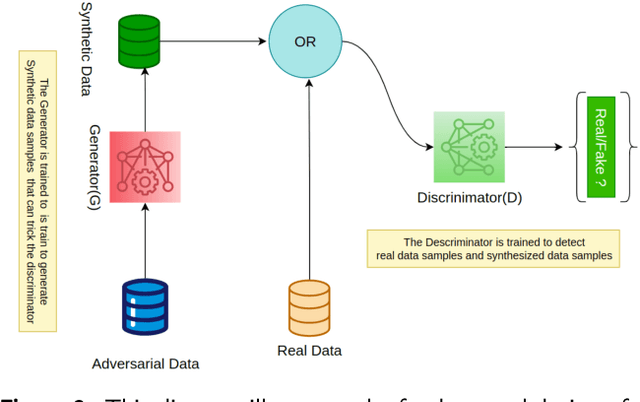
With the proliferation of Artificial Intelligence, there has been a massive increase in the amount of data required to be accumulated and disseminated digitally. As the data are available online in digital landscapes with complex and sophisticated infrastructures, it is crucial to implement various defense mechanisms based on cybersecurity. Generative Adversarial Networks (GANs), which are deep learning models, have emerged as powerful solutions for addressing the constantly changing security issues. This survey studies the significance of the deep learning model, precisely on GANs, in strengthening cybersecurity defenses. Our survey aims to explore the various works completed in GANs, such as Intrusion Detection Systems (IDS), Mobile and Network Trespass, BotNet Detection, and Malware Detection. The focus is to examine how GANs can be influential tools to strengthen cybersecurity defenses in these domains. Further, the paper discusses the challenges and constraints of using GANs in these areas and suggests future research directions. Overall, the paper highlights the potential of GANs in enhancing cybersecurity measures and addresses the need for further exploration in this field.
JailbreakZoo: Survey, Landscapes, and Horizons in Jailbreaking Large Language and Vision-Language Models
Jun 26, 2024
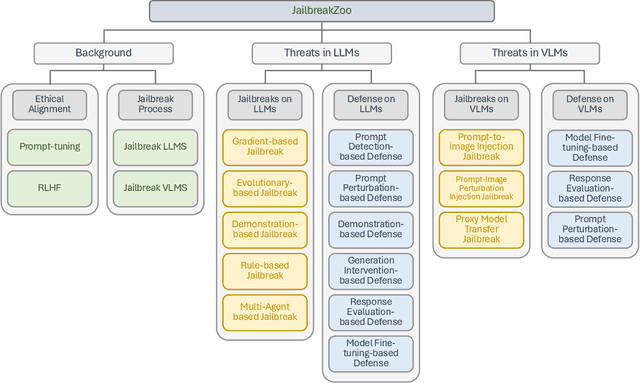
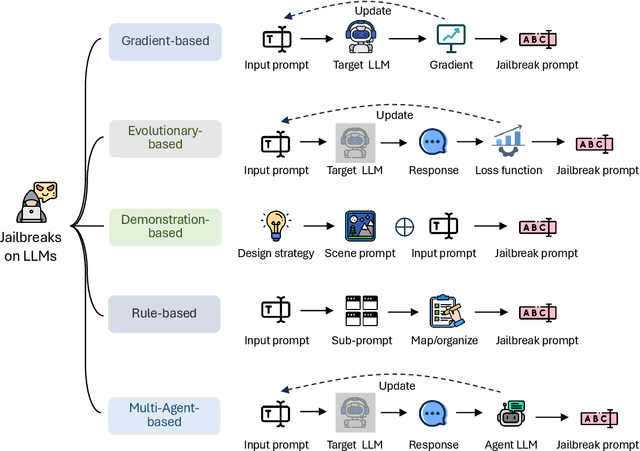
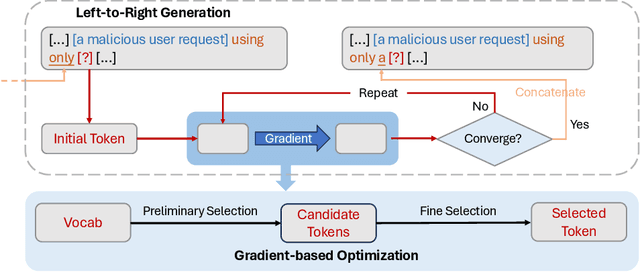
The rapid evolution of artificial intelligence (AI) through developments in Large Language Models (LLMs) and Vision-Language Models (VLMs) has brought significant advancements across various technological domains. While these models enhance capabilities in natural language processing and visual interactive tasks, their growing adoption raises critical concerns regarding security and ethical alignment. This survey provides an extensive review of the emerging field of jailbreaking--deliberately circumventing the ethical and operational boundaries of LLMs and VLMs--and the consequent development of defense mechanisms. Our study categorizes jailbreaks into seven distinct types and elaborates on defense strategies that address these vulnerabilities. Through this comprehensive examination, we identify research gaps and propose directions for future studies to enhance the security frameworks of LLMs and VLMs. Our findings underscore the necessity for a unified perspective that integrates both jailbreak strategies and defensive solutions to foster a robust, secure, and reliable environment for the next generation of language models. More details can be found on our website: \url{https://chonghan-chen.com/llm-jailbreak-zoo-survey/}.