 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Non-Linear Bandit Optimization
Mar 04, 2025We study non-linear bandit optimization where the learner maximizes a black-box function with zeroth order function oracle, which has been successfully applied in many critical applications such as drug discovery and hyperparameter tuning. Existing works have showed that with the aid of quantum computing, it is possible to break the $\Omega(\sqrt{T})$ regret lower bound in classical settings and achieve the new $O(\mathrm{poly}\log T)$ upper bound. However, they usually assume that the objective function sits within the reproducing kernel Hilbert space and their algorithms suffer from the curse of dimensionality. In this paper, we propose the new Q-NLB-UCB algorithm which uses the novel parametric function approximation technique and enjoys performance improvement due to quantum fast-forward and quantum Monte Carlo mean estimation. We prove that the regret bound of Q-NLB-UCB is not only $O(\mathrm{poly}\log T)$ but also input dimension-free, making it applicable for high-dimensional tasks. At the heart of our analyses are a new quantum regression oracle and a careful construction of parameter uncertainty region. Our algorithm is also validated for its efficiency on both synthetic and real-world tasks.
Large Language Models Can Help Mitigate Barren Plateaus
Feb 17, 2025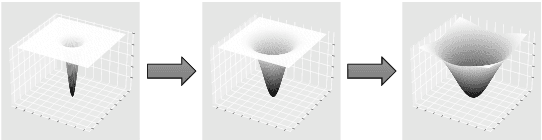
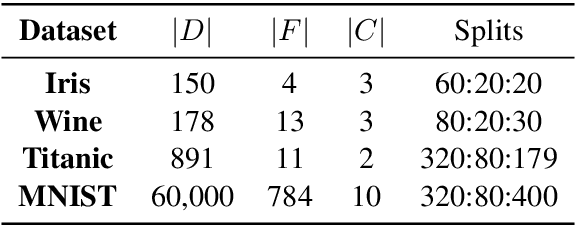
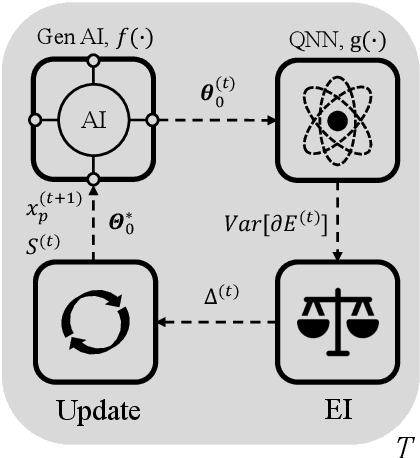

In the era of noisy intermediate-scale quantum (NISQ) computing, Quantum Neural Networks (QNNs) have emerged as a promising approach for various applications, yet their training is often hindered by barren plateaus (BPs), where gradient variance vanishes exponentially as the model size increases. To address this challenge, we propose a new Large Language Model (LLM)-driven search framework, AdaInit, that iteratively searches for optimal initial parameters of QNNs to maximize gradient variance and therefore mitigate BPs. Unlike conventional one-time initialization methods, AdaInit dynamically refines QNN's initialization using LLMs with adaptive prompting. Theoretical analysis of the Expected Improvement (EI) proves a supremum for the search, ensuring this process can eventually identify the optimal initial parameter of the QNN. Extensive experiments across four public datasets demonstrate that AdaInit significantly enhances QNN's trainability compared to classic initialization methods, validating its effectiveness in mitigating BPs.
Improving Trainability of Variational Quantum Circuits via Regularization Strategies
May 02, 2024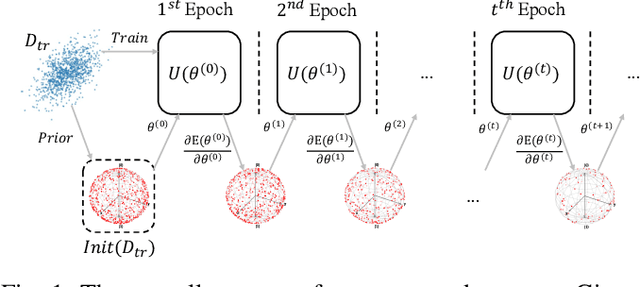
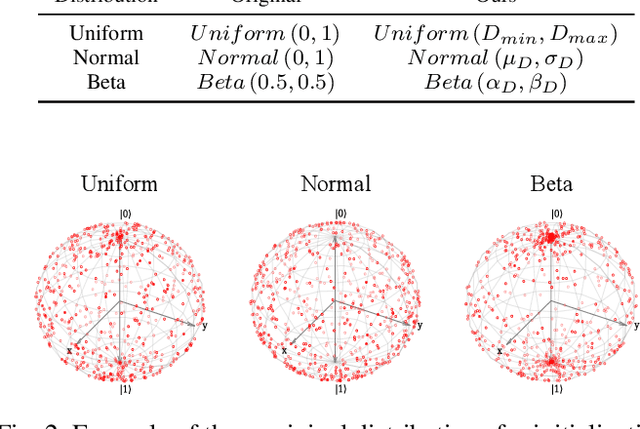
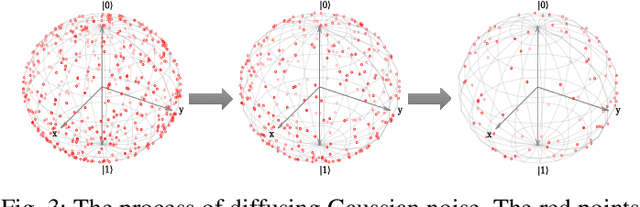
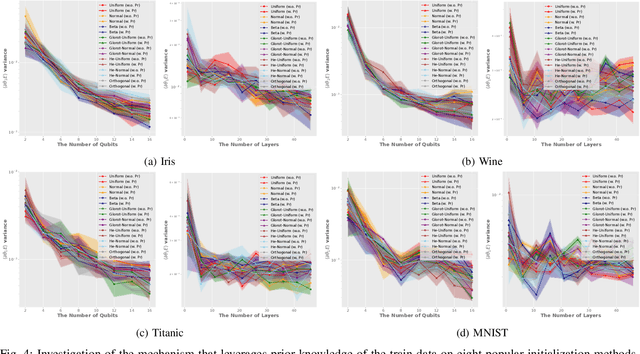
In the era of noisy intermediate-scale quantum (NISQ), variational quantum circuits (VQCs) have been widely applied in various domains, advancing the superiority of quantum circuits against classic models. Similar to classic models, regular VQCs can be optimized by various gradient-based methods. However, the optimization may be initially trapped in barren plateaus or eventually entangled in saddle points during training. These gradient issues can significantly undermine the trainability of VQC. In this work, we propose a strategy that regularizes model parameters with prior knowledge of the train data and Gaussian noise diffusion. We conduct ablation studies to verify the effectiveness of our strategy across four public datasets and demonstrate that our method can improve the trainability of VQCs against the above-mentioned gradient issues.
Quantum Heavy-tailed Bandits
Jan 23, 2023



In this paper, we study multi-armed bandits (MAB) and stochastic linear bandits (SLB) with heavy-tailed rewards and quantum reward oracle. Unlike the previous work on quantum bandits that assumes bounded/sub-Gaussian distributions for rewards, here we investigate the quantum bandits problem under a weaker assumption that the distributions of rewards only have bounded $(1+v)$-th moment for some $v\in (0,1]$. In order to achieve regret improvements for heavy-tailed bandits, we first propose a new quantum mean estimator for heavy-tailed distributions, which is based on the Quantum Monte Carlo Mean Estimator and achieves a quadratic improvement of estimation error compared to the classical one. Based on our quantum mean estimator, we focus on quantum heavy-tailed MAB and SLB and propose quantum algorithms based on the Upper Confidence Bound (UCB) framework for both problems with $\Tilde{O}(T^{\frac{1-v}{1+v}})$ regrets, polynomially improving the dependence in terms of $T$ as compared to classical (near) optimal regrets of $\Tilde{O}(T^{\frac{1}{1+v}})$, where $T$ is the number of rounds. Finally, experiments also support our theoretical results and show the effectiveness of our proposed methods.
Estimating Stochastic Linear Combination of Non-linear Regressions Efficiently and Scalably
Oct 19, 2020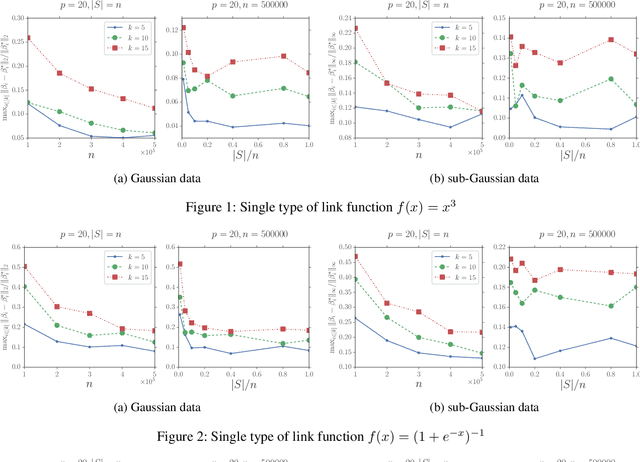
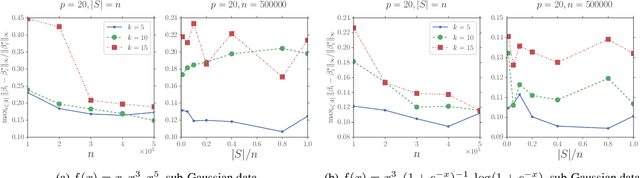
Recently, many machine learning and statistical models such as non-linear regressions, the Single Index, Multi-index, Varying Coefficient Index Models and Two-layer Neural Networks can be reduced to or be seen as a special case of a new model which is called the \textit{Stochastic Linear Combination of Non-linear Regressions} model. However, due to the high non-convexity of the problem, there is no previous work study how to estimate the model. In this paper, we provide the first study on how to estimate the model efficiently and scalably. Specifically, we first show that with some mild assumptions, if the variate vector $x$ is multivariate Gaussian, then there is an algorithm whose output vectors have $\ell_2$-norm estimation errors of $O(\sqrt{\frac{p}{n}})$ with high probability, where $p$ is the dimension of $x$ and $n$ is the number of samples. The key idea of the proof is based on an observation motived by the Stein's lemma. Then we extend our result to the case where $x$ is bounded and sub-Gaussian using the zero-bias transformation, which could be seen as a generalization of the classic Stein's lemma. We also show that with some additional assumptions there is an algorithm whose output vectors have $\ell_\infty$-norm estimation errors of $O(\frac{1}{\sqrt{p}}+\sqrt{\frac{p}{n}})$ with high probability. We also provide a concrete example to show that there exists some link function which satisfies the previous assumptions. Finally, for both Gaussian and sub-Gaussian cases we propose a faster sub-sampling based algorithm and show that when the sub-sample sizes are large enough then the estimation errors will not be sacrificed by too much. Experiments for both cases support our theoretical results. To the best of our knowledge, this is the first work that studies and provides theoretical guarantees for the stochastic linear combination of non-linear regressions model.