 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgTEMP: Temporal-Aware Surgical Video Question Answering with Text-guided Visual Memory for Laparoscopic Cholecystectomy
Apr 01, 2026Surgical procedures are inherently complex and risky, requiring extensive expertise and constant focus to well navigate evolving intraoperative scenes. Computer-assisted systems such as surgical visual question answering (VQA) offer promises for education and intraoperative support. Current surgical VQA research largely focuses on static frame analysis, overlooking rich temporal semantics. Surgical video question answering is further challenged by low visual contrast, its highly knowledge-driven nature, diverse analytical needs spanning scattered temporal windows, and the hierarchy from basic perception to high-level intraoperative assessment. To address these challenges, we propose SurgTEMP, a multimodal LLM framework featuring (i) a query-guided token selection module that builds hierarchical visual memory (spatial and temporal memory banks) and (ii) a Surgical Competency Progression (SCP) training scheme. Together, these components enable effective modeling of variable-length surgical videos while preserving procedure-relevant cues and temporal coherence, and better support diverse downstream assessment tasks. To support model development, we introduce CholeVidQA-32K, a surgical video question answering dataset comprising 32K open-ended QA pairs and 3,855 video segments (approximately 128 h total) from laparoscopic cholecystectomy. The dataset is organized into a three-level hierarchy -- Perception, Assessment, and Reasoning -- spanning 11 tasks from instrument/action/anatomy perception to Critical View of Safety (CVS), intraoperative difficulty, skill proficiency, and adverse event assessment. In comprehensive evaluations against state-of-the-art open-source multimodal and video LLMs (fine-tuned and zero-shot), SurgTEMP achieves substantial performance improvements, advancing the state of video-based surgical VQA.
Discriminative Representation Learning for Clinical Prediction
Mar 21, 2026Foundation models in healthcare have largely adopted self supervised pretraining objectives inherited from natural language processing and computer vision, emphasizing reconstruction and large scale representation learning prior to downstream adaptation. We revisit this paradigm in outcome centric clinical prediction settings and argue that, when high quality supervision is available, direct outcome alignment may provide a stronger inductive bias than generative pretraining. We propose a supervised deep learning framework that explicitly shapes representation geometry by maximizing inter class separation relative to within class variance, thereby concentrating model capacity along clinically meaningful axes. Across multiple longitudinal electronic health record tasks, including mortality and readmission prediction, our approach consistently outperforms masked, autoregressive, and contrastive pretraining baselines under matched model capacity. The proposed method improves discrimination, calibration, and sample efficiency, while simplifying the training pipeline to a single stage optimization. These findings suggest that in low entropy, outcome driven healthcare domains, supervision can act as the statistically optimal driver of representation learning, challenging the assumption that large scale self supervised pretraining is a prerequisite for strong clinical performance.
Dense Feature Learning via Linear Structure Preservation in Medical Data
Feb 07, 2026Deep learning models for medical data are typically trained using task specific objectives that encourage representations to collapse onto a small number of discriminative directions. While effective for individual prediction problems, this paradigm underutilizes the rich structure of clinical data and limits the transferability, stability, and interpretability of learned features. In this work, we propose dense feature learning, a representation centric framework that explicitly shapes the linear structure of medical embeddings. Our approach operates directly on embedding matrices, encouraging spectral balance, subspace consistency, and feature orthogonality through objectives defined entirely in terms of linear algebraic properties. Without relying on labels or generative reconstruction, dense feature learning produces representations with higher effective rank, improved conditioning, and greater stability across time. Empirical evaluations across longitudinal EHR data, clinical text, and multimodal patient representations demonstrate consistent improvements in downstream linear performance, robustness, and subspace alignment compared to supervised and self supervised baselines. These results suggest that learning to span clinical variation may be as important as learning to predict clinical outcomes, and position representation geometry as a first class objective in medical AI.
Learning Longitudinal Health Representations from EHR and Wearable Data
Jan 18, 2026Foundation models trained on electronic health records show strong performance on many clinical prediction tasks but are limited by sparse and irregular documentation. Wearable devices provide dense continuous physiological signals but lack semantic grounding. Existing methods usually model these data sources separately or combine them through late fusion. We propose a multimodal foundation model that jointly represents electronic health records and wearable data as a continuous time latent process. The model uses modality specific encoders and a shared temporal backbone pretrained with self supervised and cross modal objectives. This design produces representations that are temporally coherent and clinically grounded. Across forecasting physiological and risk modeling tasks the model outperforms strong electronic health record only and wearable only baselines especially at long horizons and under missing data. These results show that joint electronic health record and wearable pretraining yields more faithful representations of longitudinal health.
Where It Moves, It Matters: Referring Surgical Instrument Segmentation via Motion
Jan 18, 2026Enabling intuitive, language-driven interaction with surgical scenes is a critical step toward intelligent operating rooms and autonomous surgical robotic assistance. However, the task of referring segmentation, localizing surgical instruments based on natural language descriptions, remains underexplored in surgical videos, with existing approaches struggling to generalize due to reliance on static visual cues and predefined instrument names. In this work, we introduce SurgRef, a novel motion-guided framework that grounds free-form language expressions in instrument motion, capturing how tools move and interact across time, rather than what they look like. This allows models to understand and segment instruments even under occlusion, ambiguity, or unfamiliar terminology. To train and evaluate SurgRef, we present Ref-IMotion, a diverse, multi-institutional video dataset with dense spatiotemporal masks and rich motion-centric expressions. SurgRef achieves state-of-the-art accuracy and generalization across surgical procedures, setting a new benchmark for robust, language-driven surgical video segmentation.
A Unified Graph-based Framework for Scalable 3D Tree Reconstruction and Non-Destructive Biomass Estimation from Point Clouds
Jun 18, 2025Estimating forest above-ground biomass (AGB) is crucial for assessing carbon storage and supporting sustainable forest management. Quantitative Structural Model (QSM) offers a non-destructive approach to AGB estimation through 3D tree structural reconstruction. However, current QSM methods face significant limitations, as they are primarily designed for individual trees,depend on high-quality point cloud data from terrestrial laser scanning (TLS), and also require multiple pre-processing steps that hinder scalability and practical deployment. This study presents a novel unified framework that enables end-to-end processing of large-scale point clouds using an innovative graph-based pipeline. The proposed approach seamlessly integrates tree segmentation,leaf-wood separation and 3D skeletal reconstruction through dedicated graph operations including pathing and abstracting for tree topology reasoning. Comprehensive validation was conducted on datasets with varying leaf conditions (leaf-on and leaf-off), spatial scales (tree- and plot-level), and data sources (TLS and UAV-based laser scanning, ULS). Experimental results demonstrate strong performance under challenging conditions, particularly in leaf-on scenarios (~20% relative error) and low-density ULS datasets with partial coverage (~30% relative error). These findings indicate that the proposed framework provides a robust and scalable solution for large-scale, non-destructive AGB estimation. It significantly reduces dependency on specialized pre-processing tools and establishes ULS as a viable alternative to TLS. To our knowledge, this is the first method capable of enabling seamless, end-to-end 3D tree reconstruction at operational scales. This advancement substantially improves the feasibility of QSM-based AGB estimation, paving the way for broader applications in forest inventory and climate change research.
Temporal Entailment Pretraining for Clinical Language Models over EHR Data
Apr 25, 2025Clinical language models have achieved strong performance on downstream tasks by pretraining on domain specific corpora such as discharge summaries and medical notes. However, most approaches treat the electronic health record as a static document, neglecting the temporally-evolving and causally entwined nature of patient trajectories. In this paper, we introduce a novel temporal entailment pretraining objective for language models in the clinical domain. Our method formulates EHR segments as temporally ordered sentence pairs and trains the model to determine whether a later state is entailed by, contradictory to, or neutral with respect to an earlier state. Through this temporally structured pretraining task, models learn to perform latent clinical reasoning over time, improving their ability to generalize across forecasting and diagnosis tasks. We pretrain on a large corpus derived from MIMIC IV and demonstrate state of the art results on temporal clinical QA, early warning prediction, and disease progression modeling.
ChronoFormer: Time-Aware Transformer Architectures for Structured Clinical Event Modeling
Apr 10, 2025The temporal complexity of electronic health record (EHR) data presents significant challenges for predicting clinical outcomes using machine learning. This paper proposes ChronoFormer, an innovative transformer based architecture specifically designed to encode and leverage temporal dependencies in longitudinal patient data. ChronoFormer integrates temporal embeddings, hierarchical attention mechanisms, and domain specific masking techniques. Extensive experiments conducted on three benchmark tasks mortality prediction, readmission prediction, and long term comorbidity onset demonstrate substantial improvements over current state of the art methods. Furthermore, detailed analyses of attention patterns underscore ChronoFormer's capability to capture clinically meaningful long range temporal relationships.
Exploring Neural Ordinary Differential Equations as Interpretable Healthcare classifiers
Mar 05, 2025



Deep Learning has emerged as one of the most significant innovations in machine learning. However, a notable limitation of this field lies in the ``black box" decision-making processes, which have led to skepticism within groups like healthcare and scientific communities regarding its applicability. In response, this study introduces a interpretable approach using Neural Ordinary Differential Equations (NODEs), a category of neural network models that exploit the dynamics of differential equations for representation learning. Leveraging their foundation in differential equations, we illustrate the capability of these models to continuously process textual data, marking the first such model of its kind, and thereby proposing a promising direction for future research in this domain. The primary objective of this research is to propose a novel architecture for groups like healthcare that require the predictive capabilities of deep learning while emphasizing the importance of model transparency demonstrated in NODEs.
Advanced Equalization in 112 Gb/s Upstream PON Using a Novel Fourier Convolution-based Network
May 04, 2024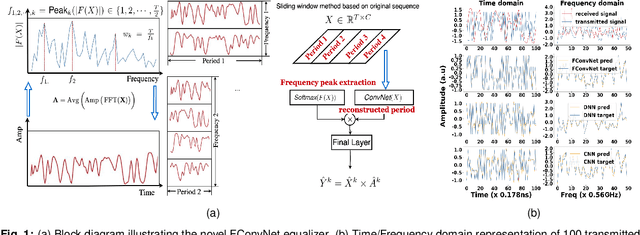

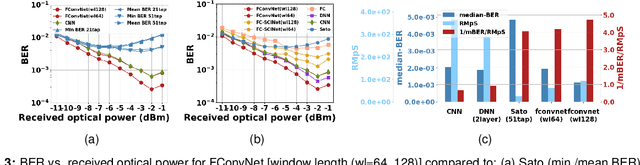
We experimentally demonstrate a novel, low-complexity Fourier Convolution-based Network (FConvNet) based equalizer for 112 Gb/s upstream PAM4-PON. At a BER of 0.005, FConvNet enhances the receiver sensitivity by 2 and 1 dB compared to a 51-tap Sato equalizer and benchmark machine learning algorithms respectively.