 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Effects of Data Replay in Continual Learning: A Feature Learning Perspective
Feb 02, 2026Continual learning (CL) aims to train models on a sequence of tasks while retaining performance on previously learned ones. A core challenge in this setting is catastrophic forgetting, where new learning interferes with past knowledge. Among various mitigation strategies, data-replay methods, where past samples are periodically revisited, are considered simple yet effective, especially when memory constraints are relaxed. However, the theoretical effectiveness of full data replay, where all past data is accessible during training, remains largely unexplored. In this paper, we present a comprehensive theoretical framework for analyzing full data-replay training in continual learning from a feature learning perspective. Adopting a multi-view data model, we identify the signal-to-noise ratio (SNR) as a critical factor affecting forgetting. Focusing on task-incremental binary classification across $M$ tasks, our analysis verifies two key conclusions: (1) forgetting can still occur under full replay when the cumulative noise from later tasks dominates the signal from earlier ones; and (2) with sufficient signal accumulation, data replay can recover earlier tasks-even if their initial learning was poor. Notably, we uncover a novel insight into task ordering: prioritizing higher-signal tasks not only facilitates learning of lower-signal tasks but also helps prevent catastrophic forgetting. We validate our theoretical findings through synthetic and real-world experiments that visualize the interplay between signal learning and noise memorization across varying SNRs and task correlation regimes.
Beyond Ordinary Lipschitz Constraints: Differentially Private Stochastic Optimization with Tsybakov Noise Condition
Sep 04, 2025
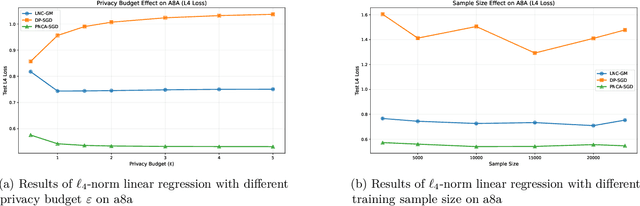
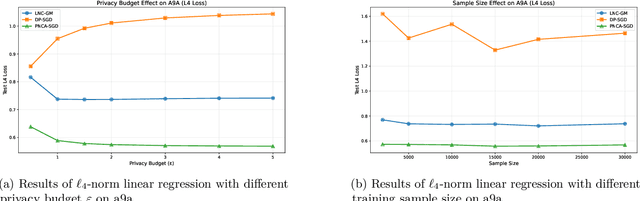
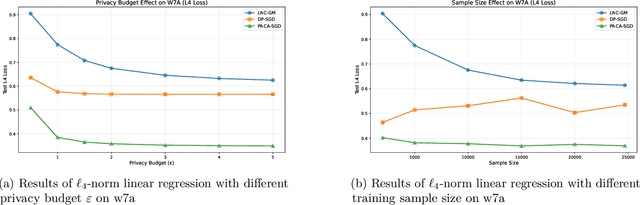
We study Stochastic Convex Optimization in the Differential Privacy model (DP-SCO). Unlike previous studies, here we assume the population risk function satisfies the Tsybakov Noise Condition (TNC) with some parameter $\theta>1$, where the Lipschitz constant of the loss could be extremely large or even unbounded, but the $\ell_2$-norm gradient of the loss has bounded $k$-th moment with $k\geq 2$. For the Lipschitz case with $\theta\geq 2$, we first propose an $(\varepsilon, \delta)$-DP algorithm whose utility bound is $\Tilde{O}\left(\left(\tilde{r}_{2k}(\frac{1}{\sqrt{n}}+(\frac{\sqrt{d}}{n\varepsilon}))^\frac{k-1}{k}\right)^\frac{\theta}{\theta-1}\right)$ in high probability, where $n$ is the sample size, $d$ is the model dimension, and $\tilde{r}_{2k}$ is a term that only depends on the $2k$-th moment of the gradient. It is notable that such an upper bound is independent of the Lipschitz constant. We then extend to the case where $\theta\geq \bar{\theta}> 1$ for some known constant $\bar{\theta}$. Moreover, when the privacy budget $\varepsilon$ is small enough, we show an upper bound of $\tilde{O}\left(\left(\tilde{r}_{k}(\frac{1}{\sqrt{n}}+(\frac{\sqrt{d}}{n\varepsilon}))^\frac{k-1}{k}\right)^\frac{\theta}{\theta-1}\right)$ even if the loss function is not Lipschitz. For the lower bound, we show that for any $\theta\geq 2$, the private minimax rate for $\rho$-zero Concentrated Differential Privacy is lower bounded by $\Omega\left(\left(\tilde{r}_{k}(\frac{1}{\sqrt{n}}+(\frac{\sqrt{d}}{n\sqrt{\rho}}))^\frac{k-1}{k}\right)^\frac{\theta}{\theta-1}\right)$.
Nearly Optimal Differentially Private ReLU Regression
Mar 08, 2025In this paper, we investigate one of the most fundamental nonconvex learning problems, ReLU regression, in the Differential Privacy (DP) model. Previous studies on private ReLU regression heavily rely on stringent assumptions, such as constant bounded norms for feature vectors and labels. We relax these assumptions to a more standard setting, where data can be i.i.d. sampled from $O(1)$-sub-Gaussian distributions. We first show that when $\varepsilon = \tilde{O}(\sqrt{\frac{1}{N}})$ and there is some public data, it is possible to achieve an upper bound of $\Tilde{O}(\frac{d^2}{N^2 \varepsilon^2})$ for the excess population risk in $(\epsilon, \delta)$-DP, where $d$ is the dimension and $N$ is the number of data samples. Moreover, we relax the requirement of $\epsilon$ and public data by proposing and analyzing a one-pass mini-batch Generalized Linear Model Perceptron algorithm (DP-MBGLMtron). Additionally, using the tracing attack argument technique, we demonstrate that the minimax rate of the estimation error for $(\varepsilon, \delta)$-DP algorithms is lower bounded by $\Omega(\frac{d^2}{N^2 \varepsilon^2})$. This shows that DP-MBGLMtron achieves the optimal utility bound up to logarithmic factors. Experiments further support our theoretical results.
Towards User-level Private Reinforcement Learning with Human Feedback
Feb 22, 2025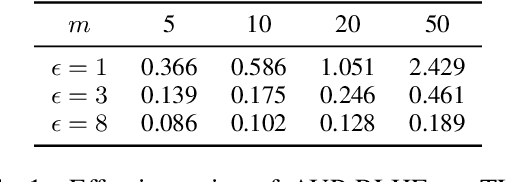
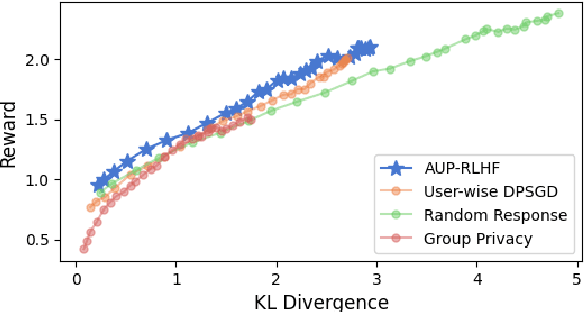

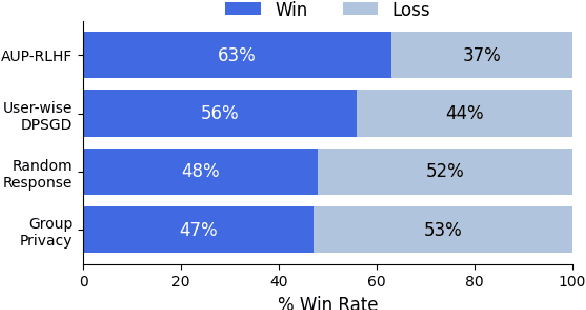
Reinforcement Learning with Human Feedback (RLHF) has emerged as an influential technique, enabling the alignment of large language models (LLMs) with human preferences. Despite the promising potential of RLHF, how to protect user preference privacy has become a crucial issue. Most previous work has focused on using differential privacy (DP) to protect the privacy of individual data. However, they have concentrated primarily on item-level privacy protection and have unsatisfactory performance for user-level privacy, which is more common in RLHF. This study proposes a novel framework, AUP-RLHF, which integrates user-level label DP into RLHF. We first show that the classical random response algorithm, which achieves an acceptable performance in item-level privacy, leads to suboptimal utility when in the user-level settings. We then establish a lower bound for the user-level label DP-RLHF and develop the AUP-RLHF algorithm, which guarantees $(\varepsilon, \delta)$ user-level privacy and achieves an improved estimation error. Experimental results show that AUP-RLHF outperforms existing baseline methods in sentiment generation and summarization tasks, achieving a better privacy-utility trade-off.
TTVD: Towards a Geometric Framework for Test-Time Adaptation Based on Voronoi Diagram
Dec 10, 2024



Deep learning models often struggle with generalization when deploying on real-world data, due to the common distributional shift to the training data. Test-time adaptation (TTA) is an emerging scheme used at inference time to address this issue. In TTA, models are adapted online at the same time when making predictions to test data. Neighbor-based approaches have gained attention recently, where prototype embeddings provide location information to alleviate the feature shift between training and testing data. However, due to their inherit limitation of simplicity, they often struggle to learn useful patterns and encounter performance degradation. To confront this challenge, we study the TTA problem from a geometric point of view. We first reveal that the underlying structure of neighbor-based methods aligns with the Voronoi Diagram, a classical computational geometry model for space partitioning. Building on this observation, we propose the Test-Time adjustment by Voronoi Diagram guidance (TTVD), a novel framework that leverages the benefits of this geometric property. Specifically, we explore two key structures: 1) Cluster-induced Voronoi Diagram (CIVD): This integrates the joint contribution of self-supervision and entropy-based methods to provide richer information. 2) Power Diagram (PD): A generalized version of the Voronoi Diagram that refines partitions by assigning weights to each Voronoi cell. Our experiments under rigid, peer-reviewed settings on CIFAR-10-C, CIFAR-100-C, ImageNet-C, and ImageNet-R shows that TTVD achieves remarkable improvements compared to state-of-the-art methods. Moreover, extensive experimental results also explore the effects of batch size and class imbalance, which are two scenarios commonly encountered in real-world applications. These analyses further validate the robustness and adaptability of our proposed framework.
Multiset Transformer: Advancing Representation Learning in Persistence Diagrams
Nov 22, 2024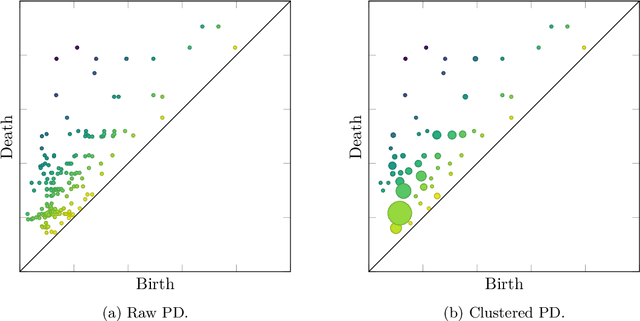


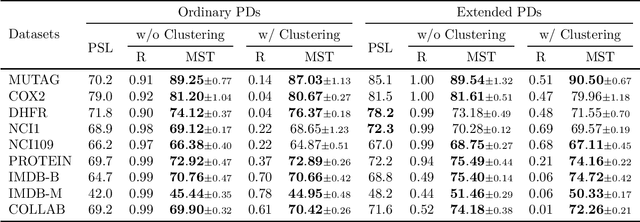
To improve persistence diagram representation learning, we propose Multiset Transformer. This is the first neural network that utilizes attention mechanisms specifically designed for multisets as inputs and offers rigorous theoretical guarantees of permutation invariance. The architecture integrates multiset-enhanced attentions with a pool-decomposition scheme, allowing multiplicities to be preserved across equivariant layers. This capability enables full leverage of multiplicities while significantly reducing both computational and spatial complexity compared to the Set Transformer. Additionally, our method can greatly benefit from clustering as a preprocessing step to further minimize complexity, an advantage not possessed by the Set Transformer. Experimental results demonstrate that the Multiset Transformer outperforms existing neural network methods in the realm of persistence diagram representation learning.
Why Fine-Tuning Struggles with Forgetting in Machine Unlearning? Theoretical Insights and a Remedial Approach
Oct 04, 2024


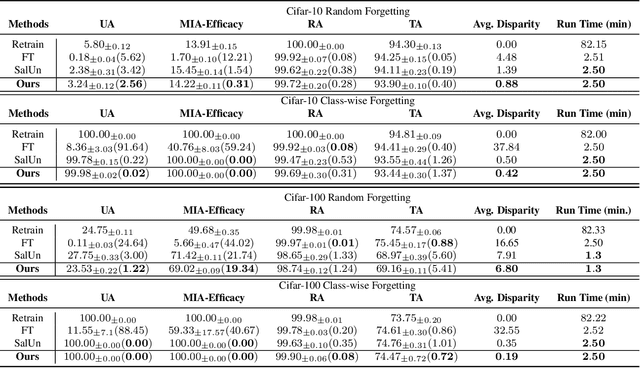
Machine Unlearning has emerged as a significant area of research, focusing on 'removing' specific subsets of data from a trained model. Fine-tuning (FT) methods have become one of the fundamental approaches for approximating unlearning, as they effectively retain model performance. However, it is consistently observed that naive FT methods struggle to forget the targeted data. In this paper, we present the first theoretical analysis of FT methods for machine unlearning within a linear regression framework, providing a deeper exploration of this phenomenon. We investigate two scenarios with distinct features and overlapping features. Our findings reveal that FT models can achieve zero remaining loss yet fail to forget the forgetting data, unlike golden models (trained from scratch without the forgetting data). This analysis reveals that naive FT methods struggle with forgetting because the pretrained model retains information about the forgetting data, and the fine-tuning process has no impact on this retained information. To address this issue, we first propose a theoretical approach to mitigate the retention of forgetting data in the pretrained model. Our analysis shows that removing the forgetting data's influence allows FT models to match the performance of the golden model. Building on this insight, we introduce a discriminative regularization term to practically reduce the unlearning loss gap between the fine-tuned model and the golden model. Our experiments on both synthetic and real-world datasets validate these theoretical insights and demonstrate the effectiveness of the proposed regularization method.
Understanding Forgetting in Continual Learning with Linear Regression
May 27, 2024
Continual learning, focused on sequentially learning multiple tasks, has gained significant attention recently. Despite the tremendous progress made in the past, the theoretical understanding, especially factors contributing to catastrophic forgetting, remains relatively unexplored. In this paper, we provide a general theoretical analysis of forgetting in the linear regression model via Stochastic Gradient Descent (SGD) applicable to both underparameterized and overparameterized regimes. Our theoretical framework reveals some interesting insights into the intricate relationship between task sequence and algorithmic parameters, an aspect not fully captured in previous studies due to their restrictive assumptions. Specifically, we demonstrate that, given a sufficiently large data size, the arrangement of tasks in a sequence, where tasks with larger eigenvalues in their population data covariance matrices are trained later, tends to result in increased forgetting. Additionally, our findings highlight that an appropriate choice of step size will help mitigate forgetting in both underparameterized and overparameterized settings. To validate our theoretical analysis, we conducted simulation experiments on both linear regression models and Deep Neural Networks (DNNs). Results from these simulations substantiate our theoretical findings.
Improved Analysis of Sparse Linear Regression in Local Differential Privacy Model
Oct 11, 2023
In this paper, we revisit the problem of sparse linear regression in the local differential privacy (LDP) model. Existing research in the non-interactive and sequentially local models has focused on obtaining the lower bounds for the case where the underlying parameter is $1$-sparse, and extending such bounds to the more general $k$-sparse case has proven to be challenging. Moreover, it is unclear whether efficient non-interactive LDP (NLDP) algorithms exist. To address these issues, we first consider the problem in the $\epsilon$ non-interactive LDP model and provide a lower bound of $\Omega(\frac{\sqrt{dk\log d}}{\sqrt{n}\epsilon})$ on the $\ell_2$-norm estimation error for sub-Gaussian data, where $n$ is the sample size and $d$ is the dimension of the space. We propose an innovative NLDP algorithm, the very first of its kind for the problem. As a remarkable outcome, this algorithm also yields a novel and highly efficient estimator as a valuable by-product. Our algorithm achieves an upper bound of $\tilde{O}({\frac{d\sqrt{k}}{\sqrt{n}\epsilon}})$ for the estimation error when the data is sub-Gaussian, which can be further improved by a factor of $O(\sqrt{d})$ if the server has additional public but unlabeled data. For the sequentially interactive LDP model, we show a similar lower bound of $\Omega({\frac{\sqrt{dk}}{\sqrt{n}\epsilon}})$. As for the upper bound, we rectify a previous method and show that it is possible to achieve a bound of $\tilde{O}(\frac{k\sqrt{d}}{\sqrt{n}\epsilon})$. Our findings reveal fundamental differences between the non-private case, central DP model, and local DP model in the sparse linear regression problem.
Enhancing Detail Preservation for Customized Text-to-Image Generation: A Regularization-Free Approach
May 23, 2023



Recent text-to-image generation models have demonstrated impressive capability of generating text-aligned images with high fidelity. However, generating images of novel concept provided by the user input image is still a challenging task. To address this problem, researchers have been exploring various methods for customizing pre-trained text-to-image generation models. Currently, most existing methods for customizing pre-trained text-to-image generation models involve the use of regularization techniques to prevent over-fitting. While regularization will ease the challenge of customization and leads to successful content creation with respect to text guidance, it may restrict the model capability, resulting in the loss of detailed information and inferior performance. In this work, we propose a novel framework for customized text-to-image generation without the use of regularization. Specifically, our proposed framework consists of an encoder network and a novel sampling method which can tackle the over-fitting problem without the use of regularization. With the proposed framework, we are able to customize a large-scale text-to-image generation model within half a minute on single GPU, with only one image provided by the user. We demonstrate in experiments that our proposed framework outperforms existing methods, and preserves more fine-grained details.