 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Zero-shot Learning Method Based on Large Language Models for Multi-modal Knowledge Graph Embedding
Mar 10, 2025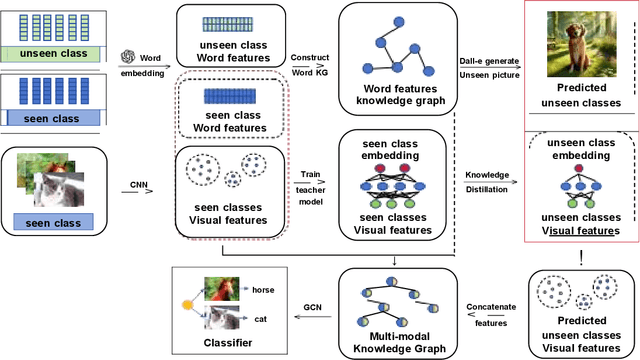
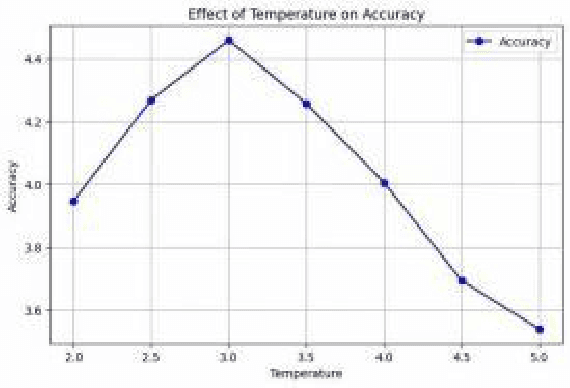
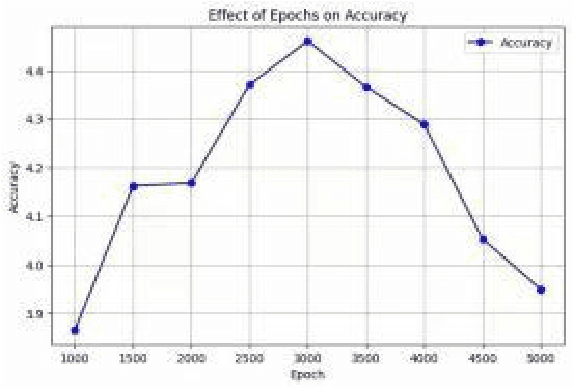
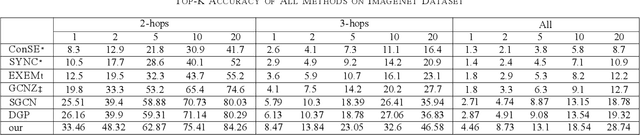
Zero-shot learning (ZL) is crucial for tasks involving unseen categories, such as natural language processing, image classification, and cross-lingual transfer. Current applications often fail to accurately infer and handle new relations or entities involving unseen categories, severely limiting their scalability and practicality in open-domain scenarios. ZL learning faces the challenge of effectively transferring semantic information of unseen categories in multi-modal knowledge graph (MMKG) embedding representation learning. In this paper, we propose ZSLLM, a framework for zero-shot embedding learning of MMKGs using large language models (LLMs). We leverage textual modality information of unseen categories as prompts to fully utilize the reasoning capabilities of LLMs, enabling semantic information transfer across different modalities for unseen categories. Through model-based learning, the embedding representation of unseen categories in MMKG is enhanced. Extensive experiments conducted on multiple real-world datasets demonstrate the superiority of our approach compared to state-of-the-art methods.
SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
Jan 30, 2025



This paper presents SANA-1.5, a linear Diffusion Transformer for efficient scaling in text-to-image generation. Building upon SANA-1.0, we introduce three key innovations: (1) Efficient Training Scaling: A depth-growth paradigm that enables scaling from 1.6B to 4.8B parameters with significantly reduced computational resources, combined with a memory-efficient 8-bit optimizer. (2) Model Depth Pruning: A block importance analysis technique for efficient model compression to arbitrary sizes with minimal quality loss. (3) Inference-time Scaling: A repeated sampling strategy that trades computation for model capacity, enabling smaller models to match larger model quality at inference time. Through these strategies, SANA-1.5 achieves a text-image alignment score of 0.72 on GenEval, which can be further improved to 0.80 through inference scaling, establishing a new SoTA on GenEval benchmark. These innovations enable efficient model scaling across different compute budgets while maintaining high quality, making high-quality image generation more accessible.
Large Language Models for Knowledge Graph Embedding Techniques, Methods, and Challenges: A Survey
Jan 14, 2025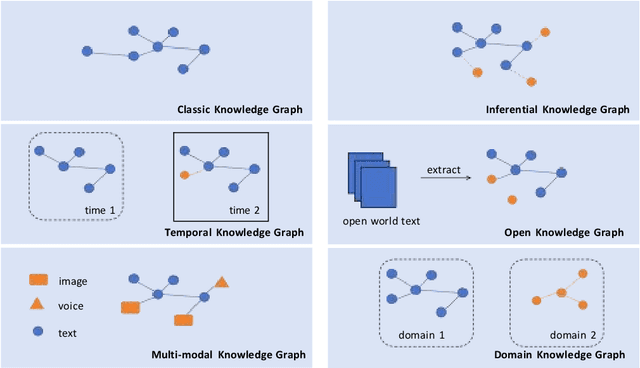

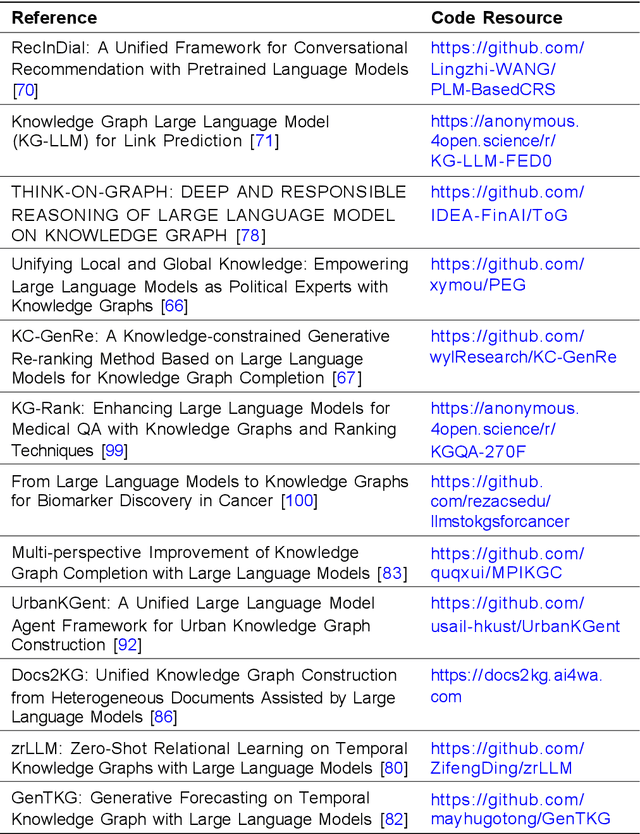
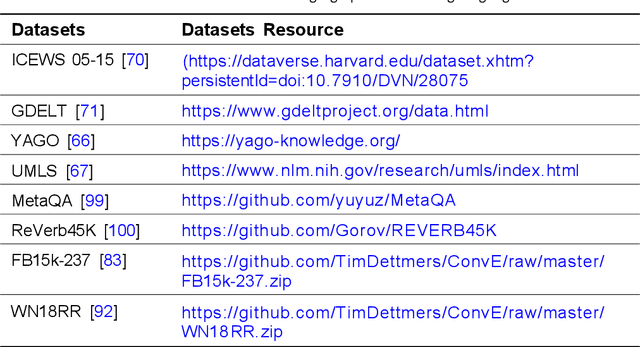
Large Language Models (LLMs) have attracted a lot of attention in various fields due to their superior performance, aiming to train hundreds of millions or more parameters on large amounts of text data to understand and generate natural language. As the superior performance of LLMs becomes apparent, they are increasingly being applied to knowledge graph embedding (KGE) related tasks to improve the processing results. As a deep learning model in the field of Natural Language Processing (NLP), it learns a large amount of textual data to predict the next word or generate content related to a given text. However, LLMs have recently been invoked to varying degrees in different types of KGE related scenarios such as multi-modal KGE and open KGE according to their task characteristics. In this paper, we investigate a wide range of approaches for performing LLMs-related tasks in different types of KGE scenarios. To better compare the various approaches, we summarize each KGE scenario in a classification. In addition to the categorization methods, we provide a tabular overview of the methods and their source code links for a more direct comparison. In the article we also discuss the applications in which the methods are mainly used and suggest several forward-looking directions for the development of this new research area.
Learn to Unlearn: Meta-Learning-Based Knowledge Graph Embedding Unlearning
Dec 01, 2024



Knowledge graph (KG) embedding methods map entities and relations into continuous vector spaces, improving performance in tasks like link prediction and question answering. With rising privacy concerns, machine unlearning (MU) has emerged as a critical AI technology, enabling models to eliminate the influence of specific data. Existing MU approaches often rely on data obfuscation and adjustments to training loss but lack generalization across unlearning tasks. This paper introduces MetaEU, a Meta-Learning-Based Knowledge Graph Embedding Unlearning framework. MetaEU leverages meta-learning to unlearn specific embeddings, mitigating their impact while preserving model performance on remaining data. Experiments on benchmark datasets demonstrate its effectiveness in KG embedding unlearning.
Playground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models
Sep 16, 2024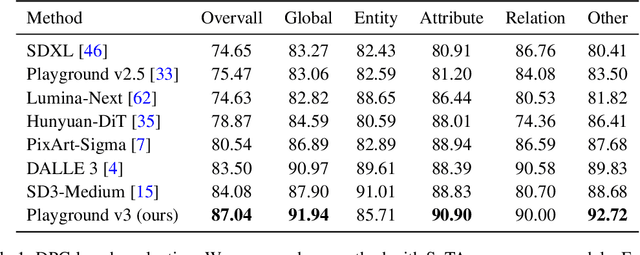
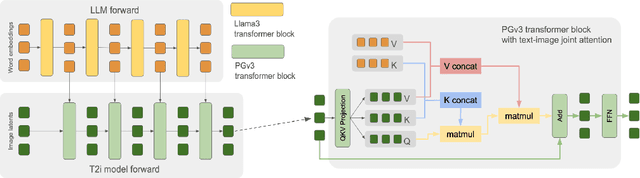
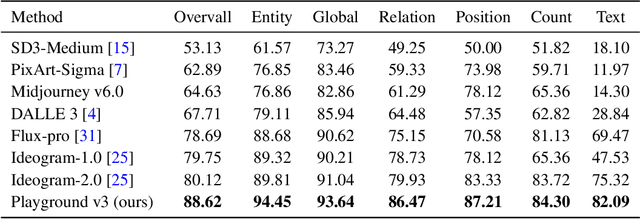

We introduce Playground v3 (PGv3), our latest text-to-image model that achieves state-of-the-art (SoTA) performance across multiple testing benchmarks, excels in graphic design abilities and introduces new capabilities. Unlike traditional text-to-image generative models that rely on pre-trained language models like T5 or CLIP text encoders, our approach fully integrates Large Language Models (LLMs) with a novel structure that leverages text conditions exclusively from a decoder-only LLM. Additionally, to enhance image captioning quality-we developed an in-house captioner, capable of generating captions with varying levels of detail, enriching the diversity of text structures. We also introduce a new benchmark CapsBench to evaluate detailed image captioning performance. Experimental results demonstrate that PGv3 excels in text prompt adherence, complex reasoning, and accurate text rendering. User preference studies indicate the super-human graphic design ability of our model for common design applications, such as stickers, posters, and logo designs. Furthermore, PGv3 introduces new capabilities, including precise RGB color control and robust multilingual understanding.
MoMA: Multimodal LLM Adapter for Fast Personalized Image Generation
Apr 08, 2024



In this paper, we present MoMA: an open-vocabulary, training-free personalized image model that boasts flexible zero-shot capabilities. As foundational text-to-image models rapidly evolve, the demand for robust image-to-image translation grows. Addressing this need, MoMA specializes in subject-driven personalized image generation. Utilizing an open-source, Multimodal Large Language Model (MLLM), we train MoMA to serve a dual role as both a feature extractor and a generator. This approach effectively synergizes reference image and text prompt information to produce valuable image features, facilitating an image diffusion model. To better leverage the generated features, we further introduce a novel self-attention shortcut method that efficiently transfers image features to an image diffusion model, improving the resemblance of the target object in generated images. Remarkably, as a tuning-free plug-and-play module, our model requires only a single reference image and outperforms existing methods in generating images with high detail fidelity, enhanced identity-preservation and prompt faithfulness. Our work is open-source, thereby providing universal access to these advancements.
Open Knowledge Base Canonicalization with Multi-task Learning
Mar 21, 2024



The construction of large open knowledge bases (OKBs) is integral to many knowledge-driven applications on the world wide web such as web search. However, noun phrases and relational phrases in OKBs often suffer from redundancy and ambiguity, which calls for the investigation on OKB canonicalization. Current solutions address OKB canonicalization by devising advanced clustering algorithms and using knowledge graph embedding (KGE) to further facilitate the canonicalization process. Nevertheless, these works fail to fully exploit the synergy between clustering and KGE learning, and the methods designed for these subtasks are sub-optimal. To this end, we put forward a multi-task learning framework, namely MulCanon, to tackle OKB canonicalization. In addition, diffusion model is used in the soft clustering process to improve the noun phrase representations with neighboring information, which can lead to more accurate representations. MulCanon unifies the learning objectives of these sub-tasks, and adopts a two-stage multi-task learning paradigm for training. A thorough experimental study on popular OKB canonicalization benchmarks validates that MulCanon can achieve competitive canonicalization results.
Federated Knowledge Graph Unlearning via Diffusion Model
Mar 13, 2024


Federated learning (FL) promotes the development and application of artificial intelligence technologies by enabling model sharing and collaboration while safeguarding data privacy. Knowledge graph (KG) embedding representation provides a foundation for knowledge reasoning and applications by mapping entities and relations into vector space. Federated KG embedding enables the utilization of knowledge from diverse client sources while safeguarding the privacy of local data. However, due to demands such as privacy protection and the need to adapt to dynamic data changes, investigations into machine unlearning (MU) have been sparked. However, it is challenging to maintain the performance of KG embedding models while forgetting the influence of specific forgotten data on the model. In this paper, we propose FedDM, a novel framework tailored for machine unlearning in federated knowledge graphs. Leveraging diffusion models, we generate noisy data to sensibly mitigate the influence of specific knowledge on FL models while preserving the overall performance concerning the remaining data. We conduct experimental evaluations on benchmark datasets to assess the efficacy of the proposed model. Extensive experiments demonstrate that FedDM yields promising results in knowledge forgetting.
Open Knowledge Base Canonicalization with Multi-task Unlearning
Oct 25, 2023



The construction of large open knowledge bases (OKBs) is integral to many applications in the field of mobile computing. Noun phrases and relational phrases in OKBs often suffer from redundancy and ambiguity, which calls for the investigation on OKB canonicalization. However, in order to meet the requirements of some privacy protection regulations and to ensure the timeliness of the data, the canonicalized OKB often needs to remove some sensitive information or outdated data. The machine unlearning in OKB canonicalization is an excellent solution to the above problem. Current solutions address OKB canonicalization by devising advanced clustering algorithms and using knowledge graph embedding (KGE) to further facilitate the canonicalization process. Effective schemes are urgently needed to fully synergise machine unlearning with clustering and KGE learning. To this end, we put forward a multi-task unlearning framework, namely MulCanon, to tackle machine unlearning problem in OKB canonicalization. Specifically, the noise characteristics in the diffusion model are utilized to achieve the effect of machine unlearning for data in OKB. MulCanon unifies the learning objectives of diffusion model, KGE and clustering algorithms, and adopts a two-step multi-task learning paradigm for training. A thorough experimental study on popular OKB canonicalization datasets validates that MulCanon achieves advanced machine unlearning effects.
Common Diffusion Noise Schedules and Sample Steps are Flawed
May 15, 2023We discover that common diffusion noise schedules do not enforce the last timestep to have zero signal-to-noise ratio (SNR), and some implementations of diffusion samplers do not start from the last timestep. Such designs are flawed and do not reflect the fact that the model is given pure Gaussian noise at inference, creating a discrepancy between training and inference. We show that the flawed design causes real problems in existing implementations. In Stable Diffusion, it severely limits the model to only generate images with medium brightness and prevents it from generating very bright and dark samples. We propose a few simple fixes: (1) rescale the noise schedule to enforce zero terminal SNR; (2) train the model with v prediction; (3) change the sampler to always start from the last timestep; (4) rescale classifier-free guidance to prevent over-exposure. These simple changes ensure the diffusion process is congruent between training and inference and allow the model to generate samples more faithful to the original data distribution.