 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScouting By Reward: VLM-TO-IRL-Driven Player Selection For Esports
Apr 15, 2026Traditional esports scouting workflows rely heavily on manual video review and aggregate performance metrics, which often fail to capture the nuanced decision-making patterns necessary to determine if a prospect fits a specific tactical archetype. To address this, we reframe style-based player evaluation in esports as an Inverse Reinforcement Learning (IRL) problem. In this paper, we introduce a novel player selection framework that learns professional-specific reward functions from logged gameplay demonstrations, allowing organizations to rank candidates by their stylistic alignment with a target star player. Our proposed architecture utilizes a multimodal, two-branch intake: one branch encodes structured state-action trajectories derived from high-resolution in-game telemetry, while the second encodes temporally aligned tactical pseudo-commentary generated by Vision-Language Models (VLMs) from broadcast footage. These representations are fused and evaluated via a Generative Adversarial Imitation Learning (GAIL) objective, where a discriminator learns to capture the unique mechanical and tactical signatures of elite professionals. By transitioning from generic skill estimation to scouting "by reward," this framework provides a scalable, workflow-aware digital twin system that enables data-driven roster construction and targeted talent discovery across massive candidate pools.
ThinkRL-Edit: Thinking in Reinforcement Learning for Reasoning-Centric Image Editing
Jan 06, 2026Instruction-driven image editing with unified multimodal generative models has advanced rapidly, yet their underlying visual reasoning remains limited, leading to suboptimal performance on reasoning-centric edits. Reinforcement learning (RL) has been investigated for improving the quality of image editing, but it faces three key challenges: (1) limited reasoning exploration confined to denoising stochasticity, (2) biased reward fusion, and (3) unstable VLM-based instruction rewards. In this work, we propose ThinkRL-Edit, a reasoning-centric RL framework that decouples visual reasoning from image synthesis and expands reasoning exploration beyond denoising. To the end, we introduce Chain-of-Thought (CoT)-based reasoning sampling with planning and reflection stages prior to generation in online sampling, compelling the model to explore multiple semantic hypotheses and validate their plausibility before committing to a visual outcome. To avoid the failures of weighted aggregation, we propose an unbiased chain preference grouping strategy across multiple reward dimensions. Moreover, we replace interval-based VLM scores with a binary checklist, yielding more precise, lower-variance, and interpretable rewards for complex reasoning. Experiments show our method significantly outperforms prior work on reasoning-centric image editing, producing instruction-faithful, visually coherent, and semantically grounded edits.
InstructMoLE: Instruction-Guided Mixture of Low-rank Experts for Multi-Conditional Image Generation
Dec 25, 2025Parameter-Efficient Fine-Tuning of Diffusion Transformers (DiTs) for diverse, multi-conditional tasks often suffers from task interference when using monolithic adapters like LoRA. The Mixture of Low-rank Experts (MoLE) architecture offers a modular solution, but its potential is usually limited by routing policies that operate at a token level. Such local routing can conflict with the global nature of user instructions, leading to artifacts like spatial fragmentation and semantic drift in complex image generation tasks. To address these limitations, we introduce InstructMoLE, a novel framework that employs an Instruction-Guided Mixture of Low-Rank Experts. Instead of per-token routing, InstructMoLE utilizes a global routing signal, Instruction-Guided Routing (IGR), derived from the user's comprehensive instruction. This ensures that a single, coherently chosen expert council is applied uniformly across all input tokens, preserving the global semantics and structural integrity of the generation process. To complement this, we introduce an output-space orthogonality loss, which promotes expert functional diversity and mitigates representational collapse. Extensive experiments demonstrate that InstructMoLE significantly outperforms existing LoRA adapters and MoLE variants across challenging multi-conditional generation benchmarks. Our work presents a robust and generalizable framework for instruction-driven fine-tuning of generative models, enabling superior compositional control and fidelity to user intent.
StoryMem: Multi-shot Long Video Storytelling with Memory
Dec 22, 2025
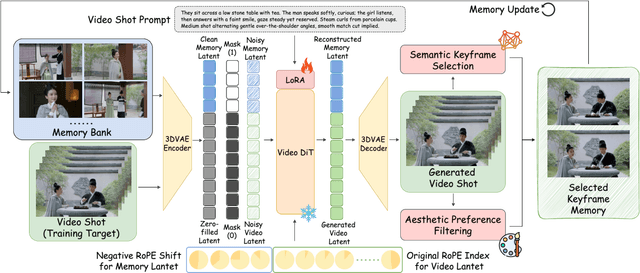

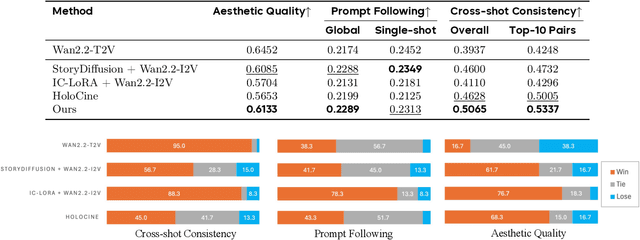
Visual storytelling requires generating multi-shot videos with cinematic quality and long-range consistency. Inspired by human memory, we propose StoryMem, a paradigm that reformulates long-form video storytelling as iterative shot synthesis conditioned on explicit visual memory, transforming pre-trained single-shot video diffusion models into multi-shot storytellers. This is achieved by a novel Memory-to-Video (M2V) design, which maintains a compact and dynamically updated memory bank of keyframes from historical generated shots. The stored memory is then injected into single-shot video diffusion models via latent concatenation and negative RoPE shifts with only LoRA fine-tuning. A semantic keyframe selection strategy, together with aesthetic preference filtering, further ensures informative and stable memory throughout generation. Moreover, the proposed framework naturally accommodates smooth shot transitions and customized story generation applications. To facilitate evaluation, we introduce ST-Bench, a diverse benchmark for multi-shot video storytelling. Extensive experiments demonstrate that StoryMem achieves superior cross-shot consistency over previous methods while preserving high aesthetic quality and prompt adherence, marking a significant step toward coherent minute-long video storytelling.
GUIDES: Guidance Using Instructor-Distilled Embeddings for Pre-trained Robot Policy Enhancement
Nov 05, 2025Pre-trained robot policies serve as the foundation of many validated robotic systems, which encapsulate extensive embodied knowledge. However, they often lack the semantic awareness characteristic of foundation models, and replacing them entirely is impractical in many situations due to high costs and the loss of accumulated knowledge. To address this gap, we introduce GUIDES, a lightweight framework that augments pre-trained policies with semantic guidance from foundation models without requiring architectural redesign. GUIDES employs a fine-tuned vision-language model (Instructor) to generate contextual instructions, which are encoded by an auxiliary module into guidance embeddings. These embeddings are injected into the policy's latent space, allowing the legacy model to adapt to this new semantic input through brief, targeted fine-tuning. For inference-time robustness, a large language model-based Reflector monitors the Instructor's confidence and, when confidence is low, initiates a reasoning loop that analyzes execution history, retrieves relevant examples, and augments the VLM's context to refine subsequent actions. Extensive validation in the RoboCasa simulation environment across diverse policy architectures shows consistent and substantial improvements in task success rates. Real-world deployment on a UR5 robot further demonstrates that GUIDES enhances motion precision for critical sub-tasks such as grasping. Overall, GUIDES offers a practical and resource-efficient pathway to upgrade, rather than replace, validated robot policies.
Learning Joint ID-Textual Representation for ID-Preserving Image Synthesis
Apr 19, 2025We propose a novel framework for ID-preserving generation using a multi-modal encoding strategy rather than injecting identity features via adapters into pre-trained models. Our method treats identity and text as a unified conditioning input. To achieve this, we introduce FaceCLIP, a multi-modal encoder that learns a joint embedding space for both identity and textual semantics. Given a reference face and a text prompt, FaceCLIP produces a unified representation that encodes both identity and text, which conditions a base diffusion model to generate images that are identity-consistent and text-aligned. We also present a multi-modal alignment algorithm to train FaceCLIP, using a loss that aligns its joint representation with face, text, and image embedding spaces. We then build FaceCLIP-SDXL, an ID-preserving image synthesis pipeline by integrating FaceCLIP with Stable Diffusion XL (SDXL). Compared to prior methods, FaceCLIP-SDXL enables photorealistic portrait generation with better identity preservation and textual relevance. Extensive experiments demonstrate its quantitative and qualitative superiority.
Flux Already Knows - Activating Subject-Driven Image Generation without Training
Apr 12, 2025We propose a simple yet effective zero-shot framework for subject-driven image generation using a vanilla Flux model. By framing the task as grid-based image completion and simply replicating the subject image(s) in a mosaic layout, we activate strong identity-preserving capabilities without any additional data, training, or inference-time fine-tuning. This "free lunch" approach is further strengthened by a novel cascade attention design and meta prompting technique, boosting fidelity and versatility. Experimental results show that our method outperforms baselines across multiple key metrics in benchmarks and human preference studies, with trade-offs in certain aspects. Additionally, it supports diverse edits, including logo insertion, virtual try-on, and subject replacement or insertion. These results demonstrate that a pre-trained foundational text-to-image model can enable high-quality, resource-efficient subject-driven generation, opening new possibilities for lightweight customization in downstream applications.
InfiniteYou: Flexible Photo Recrafting While Preserving Your Identity
Mar 20, 2025Achieving flexible and high-fidelity identity-preserved image generation remains formidable, particularly with advanced Diffusion Transformers (DiTs) like FLUX. We introduce InfiniteYou (InfU), one of the earliest robust frameworks leveraging DiTs for this task. InfU addresses significant issues of existing methods, such as insufficient identity similarity, poor text-image alignment, and low generation quality and aesthetics. Central to InfU is InfuseNet, a component that injects identity features into the DiT base model via residual connections, enhancing identity similarity while maintaining generation capabilities. A multi-stage training strategy, including pretraining and supervised fine-tuning (SFT) with synthetic single-person-multiple-sample (SPMS) data, further improves text-image alignment, ameliorates image quality, and alleviates face copy-pasting. Extensive experiments demonstrate that InfU achieves state-of-the-art performance, surpassing existing baselines. In addition, the plug-and-play design of InfU ensures compatibility with various existing methods, offering a valuable contribution to the broader community.
COAP: Memory-Efficient Training with Correlation-Aware Gradient Projection
Nov 26, 2024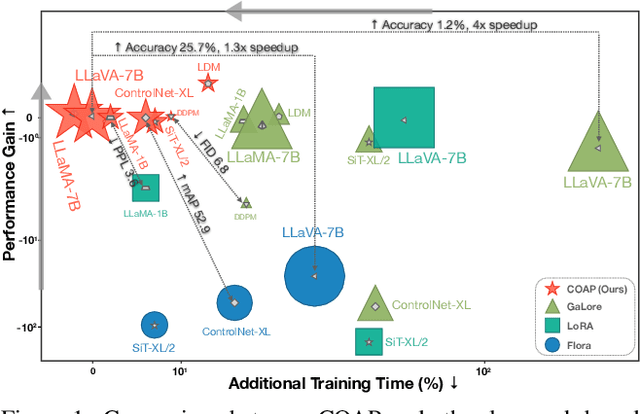
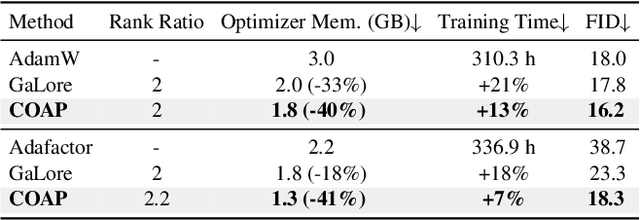
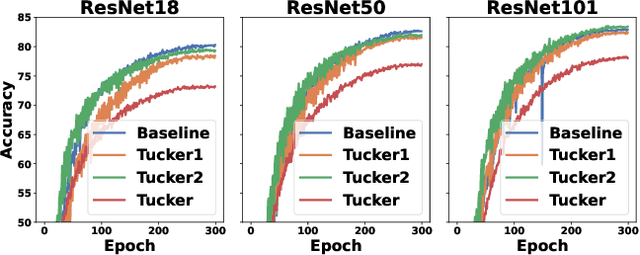
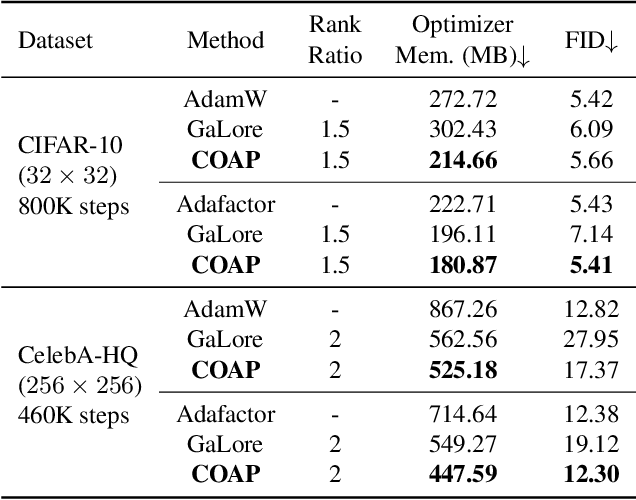
Training large-scale neural networks in vision, and multimodal domains demands substantial memory resources, primarily due to the storage of optimizer states. While LoRA, a popular parameter-efficient method, reduces memory usage, it often suffers from suboptimal performance due to the constraints of low-rank updates. Low-rank gradient projection methods (e.g., GaLore, Flora) reduce optimizer memory by projecting gradients and moment estimates into low-rank spaces via singular value decomposition or random projection. However, they fail to account for inter-projection correlation, causing performance degradation, and their projection strategies often incur high computational costs. In this paper, we present COAP (Correlation-Aware Gradient Projection), a memory-efficient method that minimizes computational overhead while maintaining training performance. Evaluated across various vision, language, and multimodal tasks, COAP outperforms existing methods in both training speed and model performance. For LLaMA-1B, it reduces optimizer memory by 61% with only 2% additional time cost, achieving the same PPL as AdamW. With 8-bit quantization, COAP cuts optimizer memory by 81% and achieves 4x speedup over GaLore for LLaVA-v1.5-7B fine-tuning, while delivering higher accuracy.
ID-Patch: Robust ID Association for Group Photo Personalization
Nov 20, 2024



The ability to synthesize personalized group photos and specify the positions of each identity offers immense creative potential. While such imagery can be visually appealing, it presents significant challenges for existing technologies. A persistent issue is identity (ID) leakage, where injected facial features interfere with one another, resulting in low face resemblance, incorrect positioning, and visual artifacts. Existing methods suffer from limitations such as the reliance on segmentation models, increased runtime, or a high probability of ID leakage. To address these challenges, we propose ID-Patch, a novel method that provides robust association between identities and 2D positions. Our approach generates an ID patch and ID embeddings from the same facial features: the ID patch is positioned on the conditional image for precise spatial control, while the ID embeddings integrate with text embeddings to ensure high resemblance. Experimental results demonstrate that ID-Patch surpasses baseline methods across metrics, such as face ID resemblance, ID-position association accuracy, and generation efficiency. Project Page is: https://byteaigc.github.io/ID-Patch/