 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection Selection Algorithm: A Likelihood based Optimization Method to Perform Post Processing for Object Detection
Dec 12, 2022
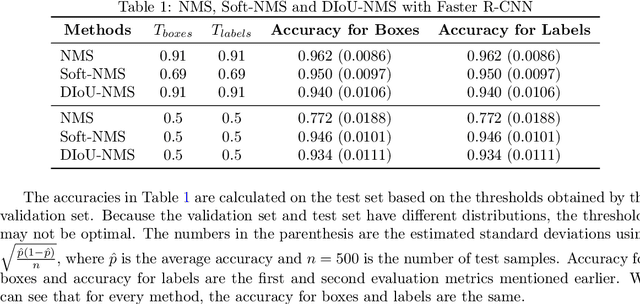


In object detection, post-processing methods like Non-maximum Suppression (NMS) are widely used. NMS can substantially reduce the number of false positive detections but may still keep some detections with low objectness scores. In order to find the exact number of objects and their labels in the image, we propose a post processing method called Detection Selection Algorithm (DSA) which is used after NMS or related methods. DSA greedily selects a subset of detected bounding boxes, together with full object reconstructions that give the interpretation of the whole image with highest likelihood, taking into account object occlusions. The algorithm consists of four components. First, we add an occlusion branch to Faster R-CNN to obtain occlusion relationships between objects. Second, we develop a single reconstruction algorithm which can reconstruct the whole appearance of an object given its visible part, based on the optimization of latent variables of a trained generative network which we call the decoder. Third, we propose a whole reconstruction algorithm which generates the joint reconstruction of all objects in a hypothesized interpretation, taking into account occlusion ordering. Finally we propose a greedy algorithm that incrementally adds or removes detections from a list to maximize the likelihood of the corresponding interpretation. DSA with NMS or Soft-NMS can achieve better results than NMS or Soft-NMS themselves, as is illustrated in our experiments on synthetic images with mutiple 3d objects.
Biologically Plausible Training Mechanisms for Self-Supervised Learning in Deep Networks
Oct 13, 2021
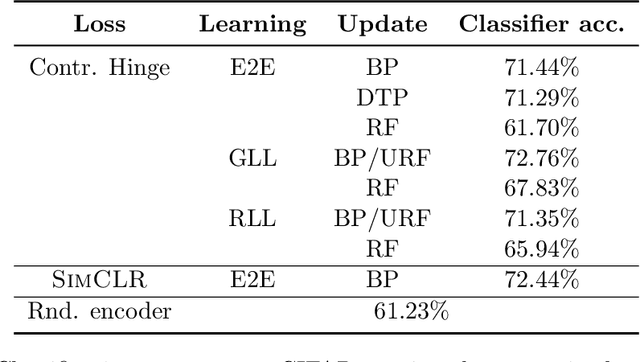

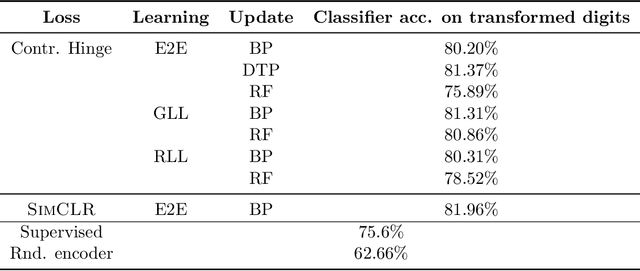
We develop biologically plausible training mechanisms for self-supervised learning (SSL) in deep networks. SSL, with a contrastive loss, is more natural as it does not require labelled data and its robustness to perturbations yields more adaptable embeddings. Moreover the perturbation of data required to create positive pairs for SSL is easily produced in a natural environment by observing objects in motion and with variable lighting over time. We propose a contrastive hinge based loss whose error involves simple local computations as opposed to the standard contrastive losses employed in the literature, which do not lend themselves easily to implementation in a network architecture due to complex computations involving ratios and inner products. Furthermore we show that learning can be performed with one of two more plausible alternatives to backpropagation. The first is difference target propagation (DTP), which trains network parameters using target-based local losses and employs a Hebbian learning rule, thus overcoming the biologically implausible symmetric weight problem in backpropagation. The second is simply layer-wise learning, where each layer is directly connected to a layer computing the loss error. The layers are either updated sequentially in a greedy fashion (GLL) or in random order (RLL), and each training stage involves a single hidden layer network. The one step backpropagation needed for each such network can either be altered with fixed random feedback weights as proposed in Lillicrap et al. (2016), or using updated random feedback as in Amit (2019). Both methods represent alternatives to the symmetric weight issue of backpropagation. By training convolutional neural networks (CNNs) with SSL and DTP, GLL or RLL, we find that our proposed framework achieves comparable performance to its implausible counterparts in both linear evaluation and transfer learning tasks.
Do We Really Need to Learn Representations from In-domain Data for Outlier Detection?
May 19, 2021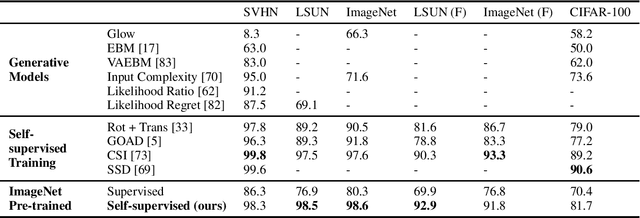
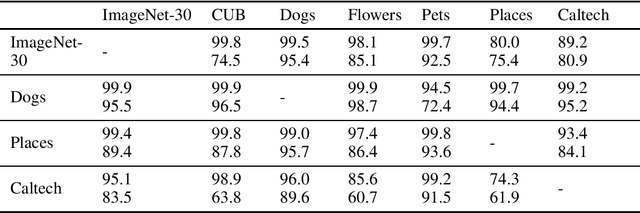
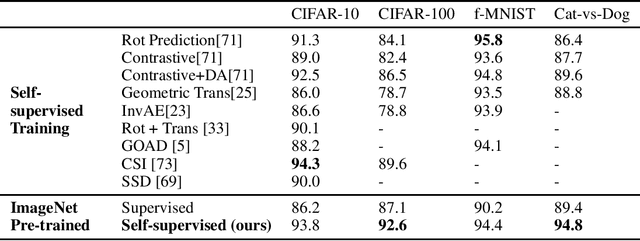

Unsupervised outlier detection, which predicts if a test sample is an outlier or not using only the information from unlabelled inlier data, is an important but challenging task. Recently, methods based on the two-stage framework achieve state-of-the-art performance on this task. The framework leverages self-supervised representation learning algorithms to train a feature extractor on inlier data, and applies a simple outlier detector in the feature space. In this paper, we explore the possibility of avoiding the high cost of training a distinct representation for each outlier detection task, and instead using a single pre-trained network as the universal feature extractor regardless of the source of in-domain data. In particular, we replace the task-specific feature extractor by one network pre-trained on ImageNet with a self-supervised loss. In experiments, we demonstrate competitive or better performance on a variety of outlier detection benchmarks compared with previous two-stage methods, suggesting that learning representations from in-domain data may be unnecessary for outlier detection.
EBMs Trained with Maximum Likelihood are Generator Models Trained with a Self-adverserial Loss
Feb 23, 2021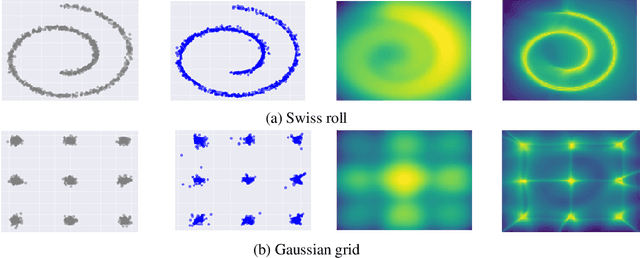



Maximum likelihood estimation is widely used in training Energy-based models (EBMs). Training requires samples from an unnormalized distribution, which is usually intractable, and in practice, these are obtained by MCMC algorithms such as Langevin dynamics. However, since MCMC in high-dimensional space converges extremely slowly, the current understanding of maximum likelihood training, which assumes approximate samples from the model can be drawn, is problematic. In this paper, we try to understand this training procedure by replacing Langevin dynamics with deterministic solutions of the associated gradient descent ODE. Doing so allows us to study the density induced by the dynamics (if the dynamics are invertible), and connect with GANs by treating the dynamics as generator models, the initial values as latent variables and the loss as optimizing a critic defined by the very same energy that determines the generator through its gradient. Hence the term - self-adversarial loss. We show that reintroducing the noise in the dynamics does not lead to a qualitative change in the behavior, and merely reduces the quality of the generator. We thus show that EBM training is effectively a self-adversarial procedure rather than maximum likelihood estimation.
Exponential Tilting of Generative Models: Improving Sample Quality by Training and Sampling from Latent Energy
Jun 15, 2020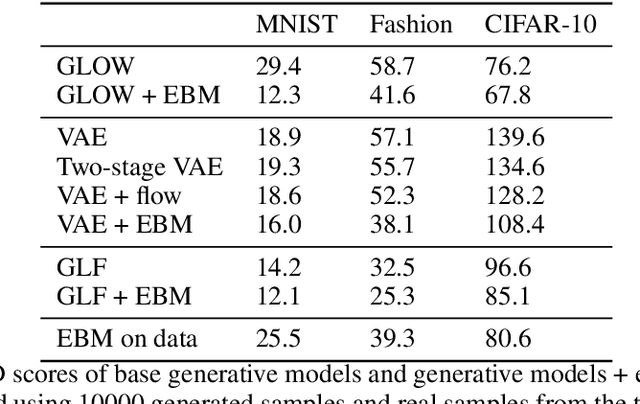
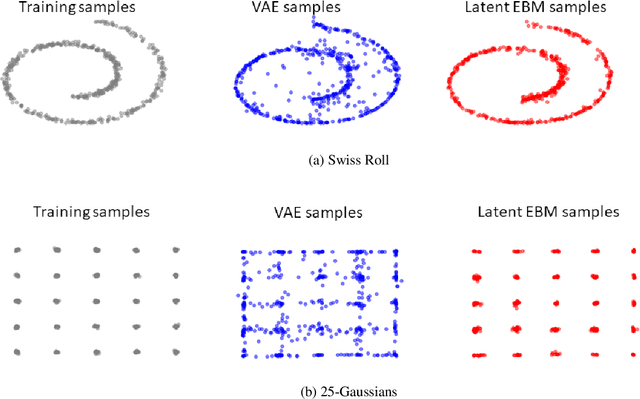


In this paper, we present a general method that can improve the sample quality of pre-trained likelihood based generative models. Our method constructs an energy function on the latent variable space that yields an energy function on samples produced by the pre-trained generative model. The energy based model is efficiently trained by maximizing the data likelihood, and after training, new samples in the latent space are generated from the energy based model and passed through the generator to producing samples in observation space. We show that using our proposed method, we can greatly improve the sample quality of popular likelihood based generative models, such as normalizing flows and VAEs, with very little computational overhead.
Likelihood Regret: An Out-of-Distribution Detection Score For Variational Auto-encoder
Apr 14, 2020
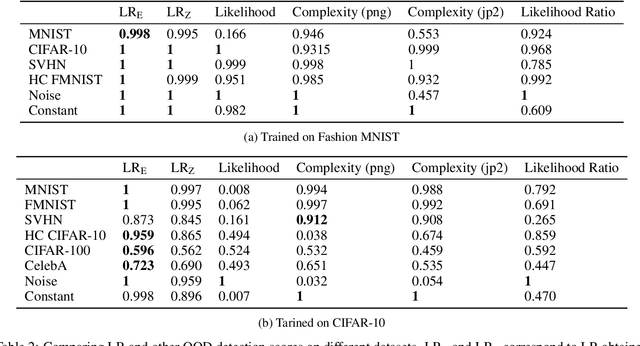
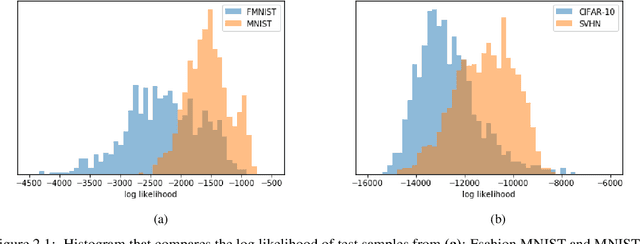

Deep probabilistic generative models enable modeling the likelihoods of very high dimensional data. An important application of generative modeling should be the ability to detect out-of-distribution (OOD) samples by setting a threshold on the likelihood. However, a recent study shows that probabilistic generative models can, in some cases, assign higher likelihoods on certain types of OOD samples, making the OOD detection rules based on likelihood threshold problematic. To address this issue, several OOD detection methods have been proposed for deep generative models. In this paper, we make the observation that some of these methods fail when applied to generative models based on Variational Auto-encoders (VAE). As an alternative, we propose Likelihood Regret, an efficient OOD score for VAEs. We benchmark our proposed method over existing approaches, and empirical results suggest that our method obtains the best overall OOD detection performances compared with other OOD method applied on VAE.
A Method to Model Conditional Distributions with Normalizing Flows
Nov 05, 2019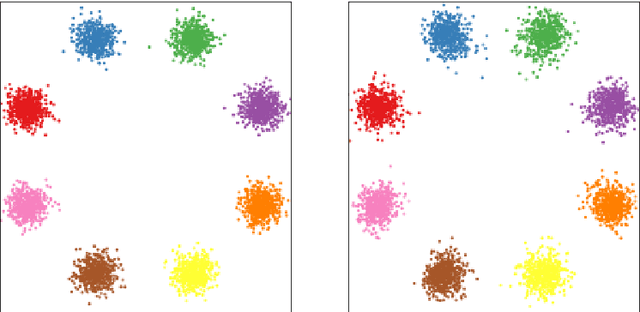


In this work, we investigate the use of normalizing flows to model conditional distributions. In particular, we use our proposed method to analyze inverse problems with invertible neural networks by maximizing the posterior likelihood. Our method uses only a single loss and is easy to train. This is an improvement on the previous method that solves similar inverse problems with invertible neural networks but which involves a combination of several loss terms with ad-hoc weighting. In addition, our method provides a natural framework to incorporate conditioning in normalizing flows, and therefore, we can train an invertible network to perform conditional generation. We analyze our method and perform a careful comparison with previous approaches. Simple experiments show the effectiveness of our method, and more comprehensive experimental evaluations are undergoing.
Generative Latent Flow: A Framework for Non-adversarial Image Generation
May 24, 2019


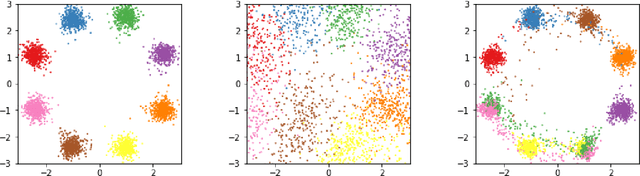
Generative Adversarial Networks (GANs) have been shown to outperform non-adversarial generative models in terms of the image generation quality by a large margin. Recently, researchers have looked into improving non-adversarial alternatives that can close the gap of generation quality while avoiding some common issues of GANs, such as unstable training and mode collapse. Examples in this direction include Two-stage VAE and Generative Latent Nearest Neighbors. However, a major drawback of these models is that they are slow to train, and in particular, they require two training stages. To address this, we propose Generative Latent Flow (GLF), which uses an auto-encoder to learn the mapping to and from the latent space, and an invertible flow to map the distribution in the latent space to simple i.i.d noise. The advantages of our method include a simple conceptual framework, single stage training and fast convergence. Quantitatively, the generation quality of our model significantly outperforms that of VAEs, and is competitive with GANs' benchmark on commonly used datasets.
Deformable Classifiers
Dec 18, 2017

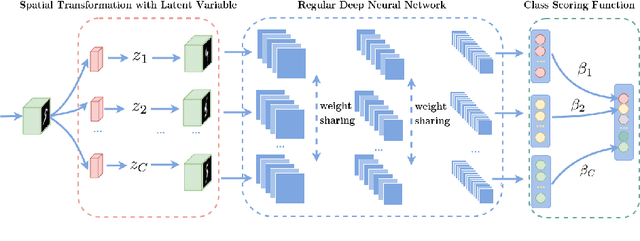
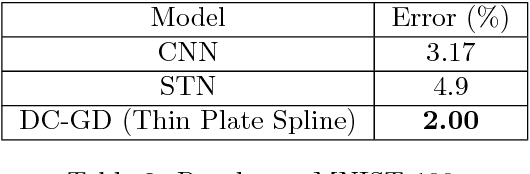
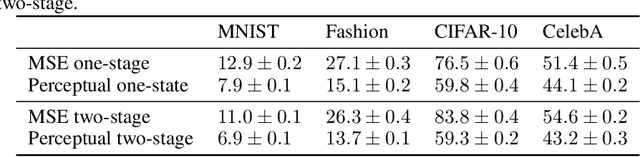
Geometric variations of objects, which do not modify the object class, pose a major challenge for object recognition. These variations could be rigid as well as non-rigid transformations. In this paper, we design a framework for training deformable classifiers, where latent transformation variables are introduced, and a transformation of the object image to a reference instantiation is computed in terms of the classifier output, separately for each class. The classifier outputs for each class, after transformation, are compared to yield the final decision. As a by-product of the classification this yields a transformation of the input object to a reference pose, which can be used for downstream tasks such as the computation of object support. We apply a two-step training mechanism for our framework, which alternates between optimizing over the latent transformation variables and the classifier parameters to minimize the loss function. We show that multilayer perceptrons, also known as deep networks, are well suited for this approach and achieve state of the art results on the rotated MNIST and the Google Earth dataset, and produce competitive results on MNIST and CIFAR-10 when training on smaller subsets of training data.
Dynamic Partition Models
Feb 16, 2017



We present a new approach for learning compact and intuitive distributed representations with binary encoding. Rather than summing up expert votes as in products of experts, we employ for each variable the opinion of the most reliable expert. Data points are hence explained through a partitioning of the variables into expert supports. The partitions are dynamically adapted based on which experts are active. During the learning phase we adopt a smoothed version of this model that uses separate mixtures for each data dimension. In our experiments we achieve accurate reconstructions of high-dimensional data points with at most a dozen experts.