 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in Diffusion-Based Generative Compression
Jan 26, 2026Popularized by their strong image generation performance, diffusion and related methods for generative modeling have found widespread success in visual media applications. In particular, diffusion methods have enabled new approaches to data compression, where realistic reconstructions can be generated at extremely low bit-rates. This article provides a unifying review of recent diffusion-based methods for generative lossy compression, with a focus on image compression. These methods generally encode the source into an embedding and employ a diffusion model to iteratively refine it in the decoding procedure, such that the final reconstruction approximately follows the ground truth data distribution. The embedding can take various forms and is typically transmitted via an auxiliary entropy model, and recent methods also explore the use of diffusion models themselves for information transmission via channel simulation. We review representative approaches through the lens of rate-distortion-perception theory, highlighting the role of common randomness and connections to inverse problems, and identify open challenges.
Safeguarding LLM Fine-tuning via Push-Pull Distributional Alignment
Jan 12, 2026The inherent safety alignment of Large Language Models (LLMs) is prone to erosion during fine-tuning, even when using seemingly innocuous datasets. While existing defenses attempt to mitigate this via data selection, they typically rely on heuristic, instance-level assessments that neglect the global geometry of the data distribution and fail to explicitly repel harmful patterns. To address this, we introduce Safety Optimal Transport (SOT), a novel framework that reframes safe fine-tuning from an instance-level filtering challenge to a distribution-level alignment task grounded in Optimal Transport (OT). At its core is a dual-reference ``push-pull'' weight-learning mechanism: SOT optimizes sample importance by actively pulling the downstream distribution towards a trusted safe anchor while simultaneously pushing it away from a general harmful reference. This establishes a robust geometric safety boundary that effectively purifies the training data. Extensive experiments across diverse model families and domains demonstrate that SOT significantly enhances model safety while maintaining competitive downstream performance, achieving a superior safety-utility trade-off compared to baselines.
PDR: A Plug-and-Play Positional Decay Framework for LLM Pre-training Data Detection
Jan 11, 2026Detecting pre-training data in Large Language Models (LLMs) is crucial for auditing data privacy and copyright compliance, yet it remains challenging in black-box, zero-shot settings where computational resources and training data are scarce. While existing likelihood-based methods have shown promise, they typically aggregate token-level scores using uniform weights, thereby neglecting the inherent information-theoretic dynamics of autoregressive generation. In this paper, we hypothesize and empirically validate that memorization signals are heavily skewed towards the high-entropy initial tokens, where model uncertainty is highest, and decay as context accumulates. To leverage this linguistic property, we introduce Positional Decay Reweighting (PDR), a training-free and plug-and-play framework. PDR explicitly reweights token-level scores to amplify distinct signals from early positions while suppressing noise from later ones. Extensive experiments show that PDR acts as a robust prior and can usually enhance a wide range of advanced methods across multiple benchmarks.
A Guardrail for Safety Preservation: When Safety-Sensitive Subspace Meets Harmful-Resistant Null-Space
Oct 16, 2025Large language models (LLMs) have achieved remarkable success in diverse tasks, yet their safety alignment remains fragile during adaptation. Even when fine-tuning on benign data or with low-rank adaptation, pre-trained safety behaviors are easily degraded, leading to harmful responses in the fine-tuned models. To address this challenge, we propose GuardSpace, a guardrail framework for preserving safety alignment throughout fine-tuning, composed of two key components: a safety-sensitive subspace and a harmful-resistant null space. First, we explicitly decompose pre-trained weights into safety-relevant and safety-irrelevant components using covariance-preconditioned singular value decomposition, and initialize low-rank adapters from the safety-irrelevant ones, while freezing safety-relevant components to preserve their associated safety mechanism. Second, we construct a null space projector that restricts adapter updates from altering safe outputs on harmful prompts, thereby maintaining the original refusal behavior. Experiments with various pre-trained models on multiple downstream tasks demonstrate that GuardSpace achieves superior performance over existing methods. Notably, for Llama-2-7B-Chat fine-tuned on GSM8K, GuardSpace outperforms the state-of-the-art method AsFT, reducing the average harmful score from 14.4% to 3.6%, while improving the accuracy from from 26.0% to 28.0%.
Deep Neural Network Calibration by Reducing Classifier Shift with Stochastic Masking
Aug 12, 2025In recent years, deep neural networks (DNNs) have shown competitive results in many fields. Despite this success, they often suffer from poor calibration, especially in safety-critical scenarios such as autonomous driving and healthcare, where unreliable confidence estimates can lead to serious consequences. Recent studies have focused on improving calibration by modifying the classifier, yet such efforts remain limited. Moreover, most existing approaches overlook calibration errors caused by underconfidence, which can be equally detrimental. To address these challenges, we propose MaC-Cal, a novel mask-based classifier calibration method that leverages stochastic sparsity to enhance the alignment between confidence and accuracy. MaC-Cal adopts a two-stage training scheme with adaptive sparsity, dynamically adjusting mask retention rates based on the deviation between confidence and accuracy. Extensive experiments show that MaC-Cal achieves superior calibration performance and robustness under data corruption, offering a practical and effective solution for reliable confidence estimation in DNNs.
Self-Guided Process Reward Optimization with Redefined Step-wise Advantage for Process Reinforcement Learning
Jul 03, 2025Process Reinforcement Learning~(PRL) has demonstrated considerable potential in enhancing the reasoning capabilities of Large Language Models~(LLMs). However, introducing additional process reward models incurs substantial computational overhead, and there is no unified theoretical framework for process-level advantage estimation. To bridge this gap, we propose \textbf{S}elf-Guided \textbf{P}rocess \textbf{R}eward \textbf{O}ptimization~(\textbf{SPRO}), a novel framework that enables process-aware RL through two key innovations: (1) we first theoretically demonstrate that process rewards can be derived intrinsically from the policy model itself, and (2) we introduce well-defined cumulative process rewards and \textbf{M}asked \textbf{S}tep \textbf{A}dvantage (\textbf{MSA}), which facilitates rigorous step-wise action advantage estimation within shared-prompt sampling groups. Our experimental results demonstrate that SPRO outperforms vaniila GRPO with 3.4x higher training efficiency and a 17.5\% test accuracy improvement. Furthermore, SPRO maintains a stable and elevated policy entropy throughout training while reducing the average response length by approximately $1/3$, evidencing sufficient exploration and prevention of reward hacking. Notably, SPRO incurs no additional computational overhead compared to outcome-supervised RL methods such as GRPO, which benefit industrial implementation.
Dynamic Context-oriented Decomposition for Task-aware Low-rank Adaptation with Less Forgetting and Faster Convergence
Jun 16, 2025



Conventional low-rank adaptation methods build adapters without considering data context, leading to sub-optimal fine-tuning performance and severe forgetting of inherent world knowledge. In this paper, we propose context-oriented decomposition adaptation (CorDA), a novel method that initializes adapters in a task-aware manner. Concretely, we develop context-oriented singular value decomposition, where we collect covariance matrices of input activations for each linear layer using sampled data from the target task, and apply SVD to the product of weight matrix and its corresponding covariance matrix. By doing so, the task-specific capability is compacted into the principal components. Thanks to the task awareness, our method enables two optional adaptation modes, knowledge-preserved mode (KPM) and instruction-previewed mode (IPM), providing flexibility to choose between freezing the principal components to preserve their associated knowledge or adapting them to better learn a new task. We further develop CorDA++ by deriving a metric that reflects the compactness of task-specific principal components, and then introducing dynamic covariance selection and dynamic rank allocation strategies based on the same metric. The two strategies provide each layer with the most representative covariance matrix and a proper rank allocation. Experimental results show that CorDA++ outperforms CorDA by a significant margin. CorDA++ in KPM not only achieves better fine-tuning performance than LoRA, but also mitigates the forgetting of pre-trained knowledge in both large language models and vision language models. For IPM, our method exhibits faster convergence, \emph{e.g.,} 4.5x speedup over QLoRA, and improves adaptation performance in various scenarios, outperforming strong baseline methods. Our method has been integrated into the PEFT library developed by Hugging Face.
AstroCompress: A benchmark dataset for multi-purpose compression of astronomical data
Jun 10, 2025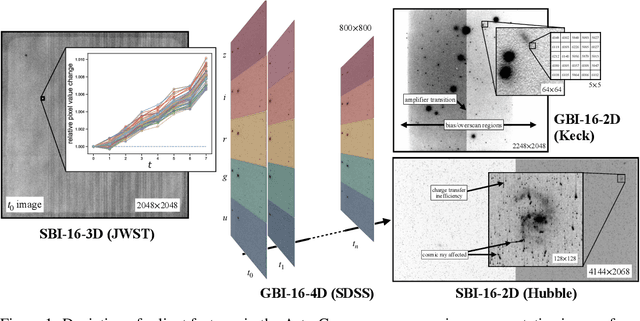
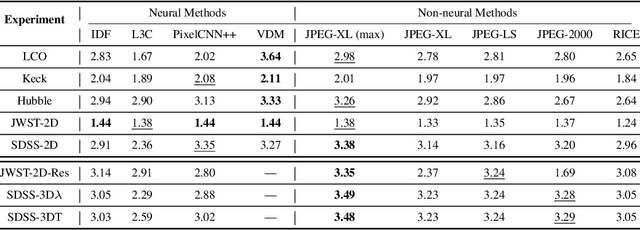
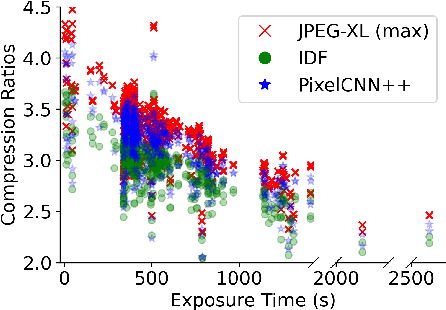
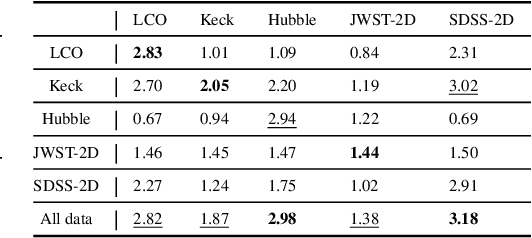
The site conditions that make astronomical observatories in space and on the ground so desirable -- cold and dark -- demand a physical remoteness that leads to limited data transmission capabilities. Such transmission limitations directly bottleneck the amount of data acquired and in an era of costly modern observatories, any improvements in lossless data compression has the potential scale to billions of dollars worth of additional science that can be accomplished on the same instrument. Traditional lossless methods for compressing astrophysical data are manually designed. Neural data compression, on the other hand, holds the promise of learning compression algorithms end-to-end from data and outperforming classical techniques by leveraging the unique spatial, temporal, and wavelength structures of astronomical images. This paper introduces AstroCompress: a neural compression challenge for astrophysics data, featuring four new datasets (and one legacy dataset) with 16-bit unsigned integer imaging data in various modes: space-based, ground-based, multi-wavelength, and time-series imaging. We provide code to easily access the data and benchmark seven lossless compression methods (three neural and four non-neural, including all practical state-of-the-art algorithms). Our results on lossless compression indicate that lossless neural compression techniques can enhance data collection at observatories, and provide guidance on the adoption of neural compression in scientific applications. Though the scope of this paper is restricted to lossless compression, we also comment on the potential exploration of lossy compression methods in future studies.
Optimization-Inspired Few-Shot Adaptation for Large Language Models
May 25, 2025Large Language Models (LLMs) have demonstrated remarkable performance in real-world applications. However, adapting LLMs to novel tasks via fine-tuning often requires substantial training data and computational resources that are impractical in few-shot scenarios. Existing approaches, such as in-context learning and Parameter-Efficient Fine-Tuning (PEFT), face key limitations: in-context learning introduces additional inference computational overhead with limited performance gains, while PEFT models are prone to overfitting on the few demonstration examples. In this work, we reinterpret the forward pass of LLMs as an optimization process, a sequence of preconditioned gradient descent steps refining internal representations. Based on this connection, we propose Optimization-Inspired Few-Shot Adaptation (OFA), integrating a parameterization that learns preconditioners without introducing additional trainable parameters, and an objective that improves optimization efficiency by learning preconditioners based on a convergence bound, while simultaneously steering the optimization path toward the flat local minimum. Our method overcomes both issues of ICL-based and PEFT-based methods, and demonstrates superior performance over the existing methods on a variety of few-shot adaptation tasks in experiments.
Inference Compute-Optimal Video Vision Language Models
May 24, 2025This work investigates the optimal allocation of inference compute across three key scaling factors in video vision language models: language model size, frame count, and the number of visual tokens per frame. While prior works typically focuses on optimizing model efficiency or improving performance without considering resource constraints, we instead identify optimal model configuration under fixed inference compute budgets. We conduct large-scale training sweeps and careful parametric modeling of task performance to identify the inference compute-optimal frontier. Our experiments reveal how task performance depends on scaling factors and finetuning data size, as well as how changes in data size shift the compute-optimal frontier. These findings translate to practical tips for selecting these scaling factors.