 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoL: Longer than Longer, Scaling Video Generation to Hour
Jan 23, 2026Recent research in long-form video generation has shifted from bidirectional to autoregressive models, yet these methods commonly suffer from error accumulation and a loss of long-term coherence. While attention sink frames have been introduced to mitigate this performance decay, they often induce a critical failure mode we term sink-collapse: the generated content repeatedly reverts to the sink frame, resulting in abrupt scene resets and cyclic motion patterns. Our analysis reveals that sink-collapse originates from an inherent conflict between the periodic structure of Rotary Position Embedding (RoPE) and the multi-head attention mechanisms prevalent in current generative models. To address it, we propose a lightweight, training-free approach that effectively suppresses this behavior by introducing multi-head RoPE jitter that breaks inter-head attention homogenization and mitigates long-horizon collapse. Extensive experiments show that our method successfully alleviates sink-collapse while preserving generation quality. To the best of our knowledge, this work achieves the first demonstration of real-time, streaming, and infinite-length video generation with little quality decay. As an illustration of this robustness, we generate continuous videos up to 12 hours in length, which, to our knowledge, is among the longest publicly demonstrated results in streaming video generation.
Rethinking Video Generation Model for the Embodied World
Jan 21, 2026Video generation models have significantly advanced embodied intelligence, unlocking new possibilities for generating diverse robot data that capture perception, reasoning, and action in the physical world. However, synthesizing high-quality videos that accurately reflect real-world robotic interactions remains challenging, and the lack of a standardized benchmark limits fair comparisons and progress. To address this gap, we introduce a comprehensive robotics benchmark, RBench, designed to evaluate robot-oriented video generation across five task domains and four distinct embodiments. It assesses both task-level correctness and visual fidelity through reproducible sub-metrics, including structural consistency, physical plausibility, and action completeness. Evaluation of 25 representative models highlights significant deficiencies in generating physically realistic robot behaviors. Furthermore, the benchmark achieves a Spearman correlation coefficient of 0.96 with human evaluations, validating its effectiveness. While RBench provides the necessary lens to identify these deficiencies, achieving physical realism requires moving beyond evaluation to address the critical shortage of high-quality training data. Driven by these insights, we introduce a refined four-stage data pipeline, resulting in RoVid-X, the largest open-source robotic dataset for video generation with 4 million annotated video clips, covering thousands of tasks and enriched with comprehensive physical property annotations. Collectively, this synergistic ecosystem of evaluation and data establishes a robust foundation for rigorous assessment and scalable training of video models, accelerating the evolution of embodied AI toward general intelligence.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Oct 02, 2025Diffusion models have revolutionized image and video generation, achieving unprecedented visual quality. However, their reliance on transformer architectures incurs prohibitively high computational costs, particularly when extending generation to long videos. Recent work has explored autoregressive formulations for long video generation, typically by distilling from short-horizon bidirectional teachers. Nevertheless, given that teacher models cannot synthesize long videos, the extrapolation of student models beyond their training horizon often leads to pronounced quality degradation, arising from the compounding of errors within the continuous latent space. In this paper, we propose a simple yet effective approach to mitigate quality degradation in long-horizon video generation without requiring supervision from long-video teachers or retraining on long video datasets. Our approach centers on exploiting the rich knowledge of teacher models to provide guidance for the student model through sampled segments drawn from self-generated long videos. Our method maintains temporal consistency while scaling video length by up to 20x beyond teacher's capability, avoiding common issues such as over-exposure and error-accumulation without recomputing overlapping frames like previous methods. When scaling up the computation, our method shows the capability of generating videos up to 4 minutes and 15 seconds, equivalent to 99.9% of the maximum span supported by our base model's position embedding and more than 50x longer than that of our baseline model. Experiments on standard benchmarks and our proposed improved benchmark demonstrate that our approach substantially outperforms baseline methods in both fidelity and consistency. Our long-horizon videos demo can be found at https://self-forcing-plus-plus.github.io/
An Efficient Deep Template Matching and In-Plane Pose Estimation Method via Template-Aware Dynamic Convolution
Oct 02, 2025In industrial inspection and component alignment tasks, template matching requires efficient estimation of a target's position and geometric state (rotation and scaling) under complex backgrounds to support precise downstream operations. Traditional methods rely on exhaustive enumeration of angles and scales, leading to low efficiency under compound transformations. Meanwhile, most deep learning-based approaches only estimate similarity scores without explicitly modeling geometric pose, making them inadequate for real-world deployment. To overcome these limitations, we propose a lightweight end-to-end framework that reformulates template matching as joint localization and geometric regression, outputting the center coordinates, rotation angle, and independent horizontal and vertical scales. A Template-Aware Dynamic Convolution Module (TDCM) dynamically injects template features at inference to guide generalizable matching. The compact network integrates depthwise separable convolutions and pixel shuffle for efficient matching. To enable geometric-annotation-free training, we introduce a rotation-shear-based augmentation strategy with structure-aware pseudo labels. A lightweight refinement module further improves angle and scale precision via local optimization. Experiments show our 3.07M model achieves high precision and 14ms inference under compound transformations. It also demonstrates strong robustness in small-template and multi-object scenarios, making it highly suitable for deployment in real-time industrial applications. The code is available at:https://github.com/ZhouJ6610/PoseMatch-TDCM.
* Published in Expert Systems with Applications
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025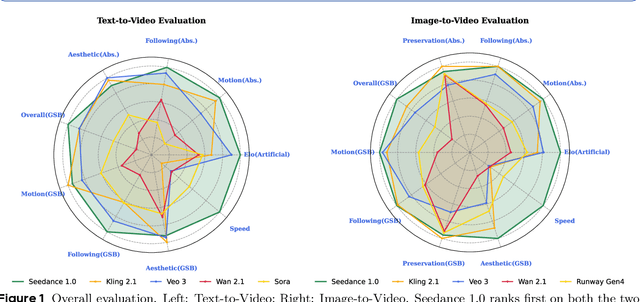
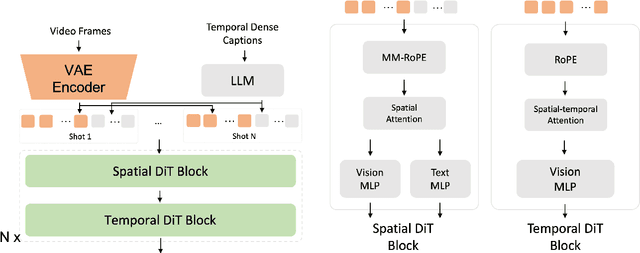
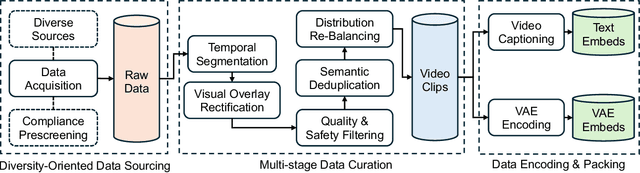
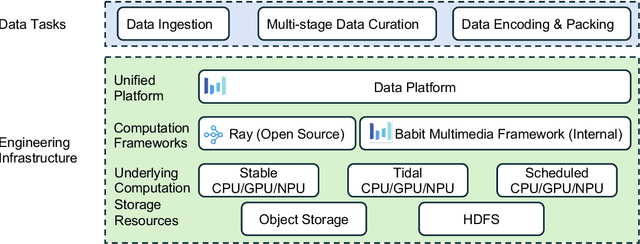
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
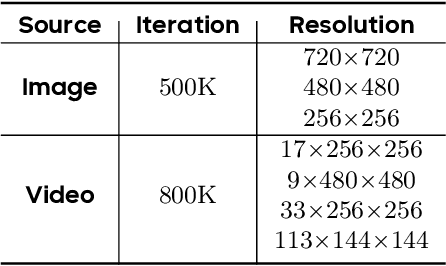
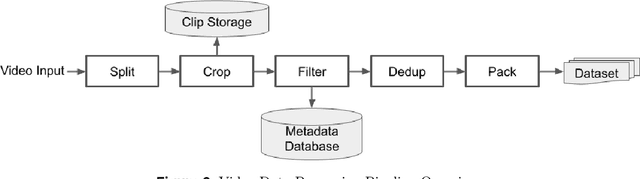

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
IU4Rec: Interest Unit-Based Product Organization and Recommendation for E-Commerce Platform
Feb 11, 2025Most recommendation systems typically follow a product-based paradigm utilizing user-product interactions to identify the most engaging items for users. However, this product-based paradigm has notable drawbacks for Xianyu~\footnote{Xianyu is China's largest online C2C e-commerce platform where a large portion of the product are post by individual sellers}. Most of the product on Xianyu posted from individual sellers often have limited stock available for distribution, and once the product is sold, it's no longer available for distribution. This result in most items distributed product on Xianyu having relatively few interactions, affecting the effectiveness of traditional recommendation depending on accumulating user-item interactions. To address these issues, we introduce \textbf{IU4Rec}, an \textbf{I}nterest \textbf{U}nit-based two-stage \textbf{Rec}ommendation system framework. We first group products into clusters based on attributes such as category, image, and semantics. These IUs are then integrated into the Recommendation system, delivering both product and technological innovations. IU4Rec begins by grouping products into clusters based on attributes such as category, image, and semantics, forming Interest Units (IUs). Then we redesign the recommendation process into two stages. In the first stage, the focus is on recommend these Interest Units, capturing broad-level interests. In the second stage, it guides users to find the best option among similar products within the selected Interest Unit. User-IU interactions are incorporated into our ranking models, offering the advantage of more persistent IU behaviors compared to item-specific interactions. Experimental results on the production dataset and online A/B testing demonstrate the effectiveness and superiority of our proposed IU-centric recommendation approach.
Continuous Knowledge-Preserving Decomposition for Few-Shot Continual Learning
Jan 09, 2025



Few-shot class-incremental learning (FSCIL) involves learning new classes from limited data while retaining prior knowledge, and often results in catastrophic forgetting. Existing methods either freeze backbone networks to preserve knowledge, which limits adaptability, or rely on additional modules or prompts, introducing inference overhead. To this end, we propose Continuous Knowledge-Preserving Decomposition for FSCIL (CKPD-FSCIL), a framework that decomposes a model's weights into two parts: one that compacts existing knowledge (knowledge-sensitive components) and another that carries redundant capacity to accommodate new abilities (redundant-capacity components). The decomposition is guided by a covariance matrix from replay samples, ensuring principal components align with classification abilities. During adaptation, we freeze the knowledge-sensitive components and only adapt the redundant-capacity components, fostering plasticity while minimizing interference without changing the architecture or increasing overhead. Additionally, CKPD introduces an adaptive layer selection strategy to identify layers with redundant capacity, dynamically allocating adapters. Experiments on multiple benchmarks show that CKPD-FSCIL outperforms state-of-the-art methods.
LipGen: Viseme-Guided Lip Video Generation for Enhancing Visual Speech Recognition
Jan 08, 2025



Visual speech recognition (VSR), commonly known as lip reading, has garnered significant attention due to its wide-ranging practical applications. The advent of deep learning techniques and advancements in hardware capabilities have significantly enhanced the performance of lip reading models. Despite these advancements, existing datasets predominantly feature stable video recordings with limited variability in lip movements. This limitation results in models that are highly sensitive to variations encountered in real-world scenarios. To address this issue, we propose a novel framework, LipGen, which aims to improve model robustness by leveraging speech-driven synthetic visual data, thereby mitigating the constraints of current datasets. Additionally, we introduce an auxiliary task that incorporates viseme classification alongside attention mechanisms. This approach facilitates the efficient integration of temporal information, directing the model's focus toward the relevant segments of speech, thereby enhancing discriminative capabilities. Our method demonstrates superior performance compared to the current state-of-the-art on the lip reading in the wild (LRW) dataset and exhibits even more pronounced advantages under challenging conditions.