 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDummy-Aware Weighted Attack (DAWA): Breaking the Safe Sink in Dummy Class Defenses
Mar 31, 2026Adversarial robustness evaluation faces a critical challenge as new defense paradigms emerge that can exploit limitations in existing assessment methods. This paper reveals that Dummy Classes-based defenses, which introduce an additional "dummy" class as a safety sink for adversarial examples, achieve significantly overestimated robustness under conventional evaluation strategies like AutoAttack. The fundamental limitation stems from these attacks' singular focus on misleading the true class label, which aligns perfectly with the defense mechanism--successful attacks are simply captured by the dummy class. To address this gap, we propose Dummy-Aware Weighted Attack (DAWA), a novel evaluation method that simultaneously targets both the true label and dummy label with adaptive weighting during adversarial example synthesis. Extensive experiments demonstrate that DAWA effectively breaks this defense paradigm, reducing the measured robustness of a leading Dummy Classes-based defense from 58.61% to 29.52% on CIFAR-10 under l_infty perturbation (epsilon=8/255). Our work provides a more reliable benchmark for evaluating this emerging class of defenses and highlights the need for continuous evolution of robustness assessment methodologies.
FlowCut: Rethinking Redundancy via Information Flow for Efficient Vision-Language Models
May 26, 2025Large vision-language models (LVLMs) excel at multimodal understanding but suffer from high computational costs due to redundant vision tokens. Existing pruning methods typically rely on single-layer attention scores to rank and prune redundant visual tokens to solve this inefficiency. However, as the interaction between tokens and layers is complicated, this raises a basic question: Is such a simple single-layer criterion sufficient to identify redundancy? To answer this question, we rethink the emergence of redundant visual tokens from a fundamental perspective: information flow, which models the interaction between tokens and layers by capturing how information moves between tokens across layers. We find (1) the CLS token acts as an information relay, which can simplify the complicated flow analysis; (2) the redundancy emerges progressively and dynamically via layer-wise attention concentration; and (3) relying solely on attention scores from single layers can lead to contradictory redundancy identification. Based on this, we propose FlowCut, an information-flow-aware pruning framework, mitigating the insufficiency of the current criterion for identifying redundant tokens and better aligning with the model's inherent behaviors. Extensive experiments show that FlowCut achieves superior results, outperforming SoTA by 1.6% on LLaVA-1.5-7B with 88.9% token reduction, and by 4.3% on LLaVA-NeXT-7B with 94.4% reduction, delivering 3.2x speed-up in the prefilling stage. Our code is available at https://github.com/TungChintao/FlowCut
RA-BLIP: Multimodal Adaptive Retrieval-Augmented Bootstrapping Language-Image Pre-training
Oct 18, 2024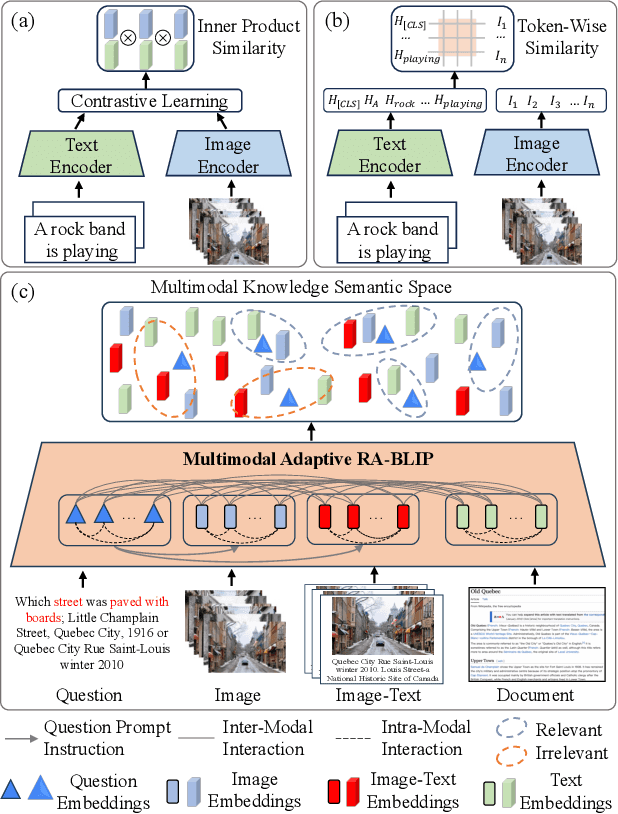
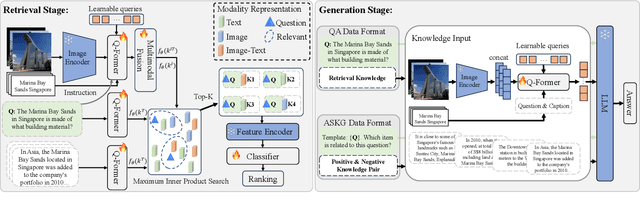
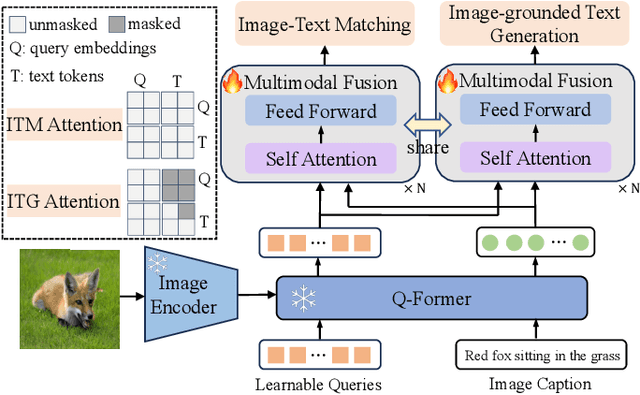
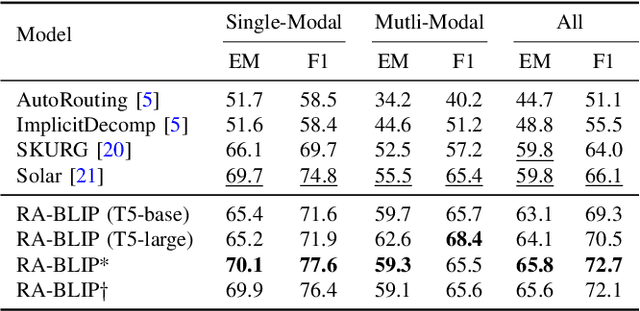
Multimodal Large Language Models (MLLMs) have recently received substantial interest, which shows their emerging potential as general-purpose models for various vision-language tasks. MLLMs involve significant external knowledge within their parameters; however, it is challenging to continually update these models with the latest knowledge, which involves huge computational costs and poor interpretability. Retrieval augmentation techniques have proven to be effective plugins for both LLMs and MLLMs. In this study, we propose multimodal adaptive Retrieval-Augmented Bootstrapping Language-Image Pre-training (RA-BLIP), a novel retrieval-augmented framework for various MLLMs. Considering the redundant information within vision modality, we first leverage the question to instruct the extraction of visual information through interactions with one set of learnable queries, minimizing irrelevant interference during retrieval and generation. Besides, we introduce a pre-trained multimodal adaptive fusion module to achieve question text-to-multimodal retrieval and integration of multimodal knowledge by projecting visual and language modalities into a unified semantic space. Furthermore, we present an Adaptive Selection Knowledge Generation (ASKG) strategy to train the generator to autonomously discern the relevance of retrieved knowledge, which realizes excellent denoising performance. Extensive experiments on open multimodal question-answering datasets demonstrate that RA-BLIP achieves significant performance and surpasses the state-of-the-art retrieval-augmented models.
Preview-based Category Contrastive Learning for Knowledge Distillation
Oct 18, 2024Knowledge distillation is a mainstream algorithm in model compression by transferring knowledge from the larger model (teacher) to the smaller model (student) to improve the performance of student. Despite many efforts, existing methods mainly investigate the consistency between instance-level feature representation or prediction, which neglects the category-level information and the difficulty of each sample, leading to undesirable performance. To address these issues, we propose a novel preview-based category contrastive learning method for knowledge distillation (PCKD). It first distills the structural knowledge of both instance-level feature correspondence and the relation between instance features and category centers in a contrastive learning fashion, which can explicitly optimize the category representation and explore the distinct correlation between representations of instances and categories, contributing to discriminative category centers and better classification results. Besides, we introduce a novel preview strategy to dynamically determine how much the student should learn from each sample according to their difficulty. Different from existing methods that treat all samples equally and curriculum learning that simply filters out hard samples, our method assigns a small weight for hard instances as a preview to better guide the student training. Extensive experiments on several challenging datasets, including CIFAR-100 and ImageNet, demonstrate the superiority over state-of-the-art methods.
LAKE-RED: Camouflaged Images Generation by Latent Background Knowledge Retrieval-Augmented Diffusion
Apr 07, 2024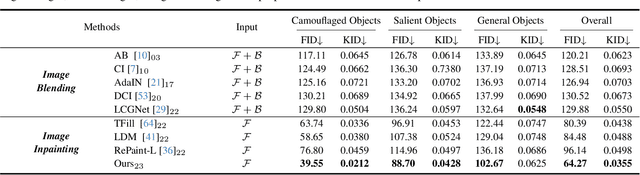
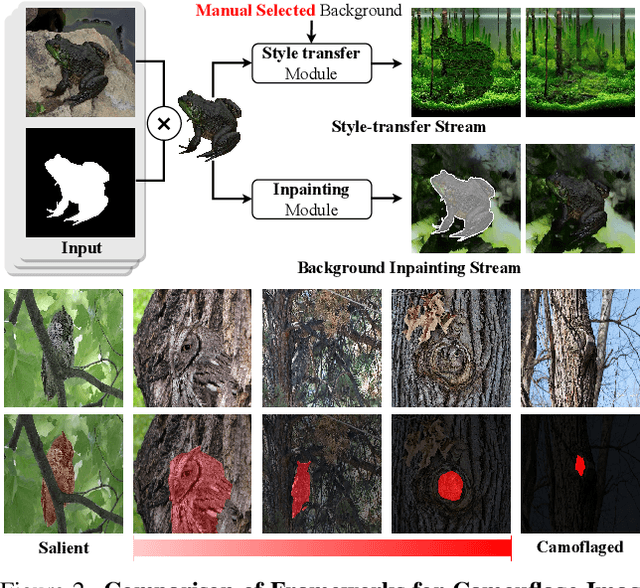
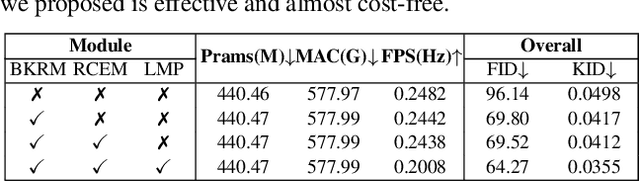
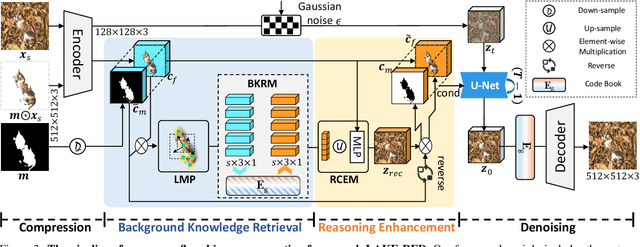
Camouflaged vision perception is an important vision task with numerous practical applications. Due to the expensive collection and labeling costs, this community struggles with a major bottleneck that the species category of its datasets is limited to a small number of object species. However, the existing camouflaged generation methods require specifying the background manually, thus failing to extend the camouflaged sample diversity in a low-cost manner. In this paper, we propose a Latent Background Knowledge Retrieval-Augmented Diffusion (LAKE-RED) for camouflaged image generation. To our knowledge, our contributions mainly include: (1) For the first time, we propose a camouflaged generation paradigm that does not need to receive any background inputs. (2) Our LAKE-RED is the first knowledge retrieval-augmented method with interpretability for camouflaged generation, in which we propose an idea that knowledge retrieval and reasoning enhancement are separated explicitly, to alleviate the task-specific challenges. Moreover, our method is not restricted to specific foreground targets or backgrounds, offering a potential for extending camouflaged vision perception to more diverse domains. (3) Experimental results demonstrate that our method outperforms the existing approaches, generating more realistic camouflage images.
Large Model Based Referring Camouflaged Object Detection
Nov 28, 2023



Referring camouflaged object detection (Ref-COD) is a recently-proposed problem aiming to segment out specified camouflaged objects matched with a textual or visual reference. This task involves two major challenges: the COD domain-specific perception and multimodal reference-image alignment. Our motivation is to make full use of the semantic intelligence and intrinsic knowledge of recent Multimodal Large Language Models (MLLMs) to decompose this complex task in a human-like way. As language is highly condensed and inductive, linguistic expression is the main media of human knowledge learning, and the transmission of knowledge information follows a multi-level progression from simplicity to complexity. In this paper, we propose a large-model-based Multi-Level Knowledge-Guided multimodal method for Ref-COD termed MLKG, where multi-level knowledge descriptions from MLLM are organized to guide the large vision model of segmentation to perceive the camouflage-targets and camouflage-scene progressively and meanwhile deeply align the textual references with camouflaged photos. To our knowledge, our contributions mainly include: (1) This is the first time that the MLLM knowledge is studied for Ref-COD and COD. (2) We, for the first time, propose decomposing Ref-COD into two main perspectives of perceiving the target and scene by integrating MLLM knowledge, and contribute a multi-level knowledge-guided method. (3) Our method achieves the state-of-the-art on the Ref-COD benchmark outperforming numerous strong competitors. Moreover, thanks to the injected rich knowledge, it demonstrates zero-shot generalization ability on uni-modal COD datasets. We will release our code soon.
Prompt Switch: Efficient CLIP Adaptation for Text-Video Retrieval
Aug 15, 2023



In text-video retrieval, recent works have benefited from the powerful learning capabilities of pre-trained text-image foundation models (e.g., CLIP) by adapting them to the video domain. A critical problem for them is how to effectively capture the rich semantics inside the video using the image encoder of CLIP. To tackle this, state-of-the-art methods adopt complex cross-modal modeling techniques to fuse the text information into video frame representations, which, however, incurs severe efficiency issues in large-scale retrieval systems as the video representations must be recomputed online for every text query. In this paper, we discard this problematic cross-modal fusion process and aim to learn semantically-enhanced representations purely from the video, so that the video representations can be computed offline and reused for different texts. Concretely, we first introduce a spatial-temporal "Prompt Cube" into the CLIP image encoder and iteratively switch it within the encoder layers to efficiently incorporate the global video semantics into frame representations. We then propose to apply an auxiliary video captioning objective to train the frame representations, which facilitates the learning of detailed video semantics by providing fine-grained guidance in the semantic space. With a naive temporal fusion strategy (i.e., mean-pooling) on the enhanced frame representations, we obtain state-of-the-art performances on three benchmark datasets, i.e., MSR-VTT, MSVD, and LSMDC.
Synthesizing Coherent Story with Auto-Regressive Latent Diffusion Models
Nov 20, 2022
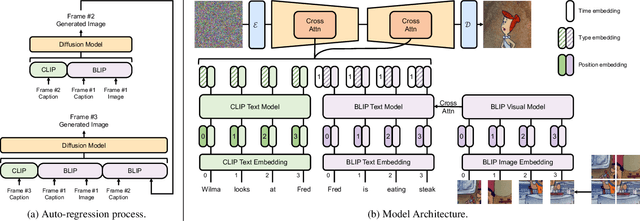


Conditioned diffusion models have demonstrated state-of-the-art text-to-image synthesis capacity. Recently, most works focus on synthesizing independent images; While for real-world applications, it is common and necessary to generate a series of coherent images for story-stelling. In this work, we mainly focus on story visualization and continuation tasks and propose AR-LDM, a latent diffusion model auto-regressively conditioned on history captions and generated images. Moreover, AR-LDM can generalize to new characters through adaptation. To our best knowledge, this is the first work successfully leveraging diffusion models for coherent visual story synthesizing. Quantitative results show that AR-LDM achieves SoTA FID scores on PororoSV, FlintstonesSV, and the newly introduced challenging dataset VIST containing natural images. Large-scale human evaluations show that AR-LDM has superior performance in terms of quality, relevance, and consistency.
TVDIM: Enhancing Image Self-Supervised Pretraining via Noisy Text Data
Jun 13, 2021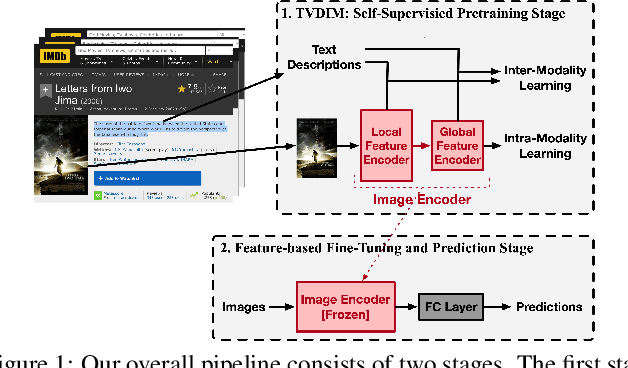
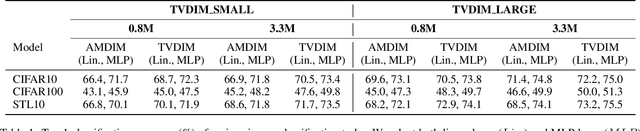
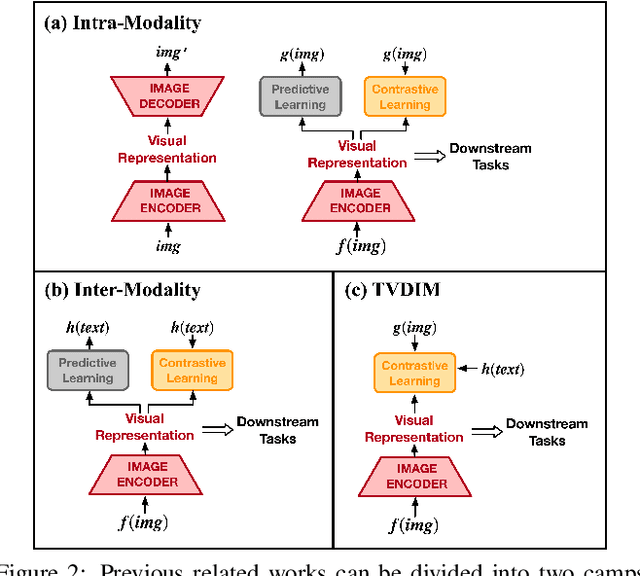
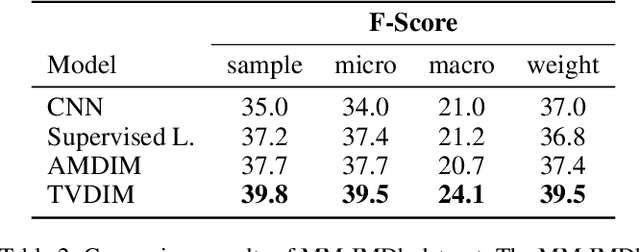
Among ubiquitous multimodal data in the real world, text is the modality generated by human, while image reflects the physical world honestly. In a visual understanding application, machines are expected to understand images like human. Inspired by this, we propose a novel self-supervised learning method, named Text-enhanced Visual Deep InfoMax (TVDIM), to learn better visual representations by fully utilizing the naturally-existing multimodal data. Our core idea of self-supervised learning is to maximize the mutual information between features extracted from multiple views of a shared context to a rational degree. Different from previous methods which only consider multiple views from a single modality, our work produces multiple views from different modalities, and jointly optimizes the mutual information for features pairs of intra-modality and inter-modality. Considering the information gap between inter-modality features pairs from data noise, we adopt a \emph{ranking-based} contrastive learning to optimize the mutual information. During evaluation, we directly use the pre-trained visual representations to complete various image classification tasks. Experimental results show that, TVDIM significantly outperforms previous visual self-supervised methods when processing the same set of images.
InfoBehavior: Self-supervised Representation Learning for Ultra-long Behavior Sequence via Hierarchical Grouping
Jun 13, 2021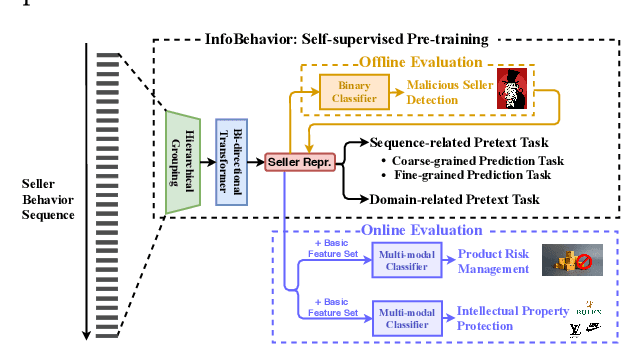
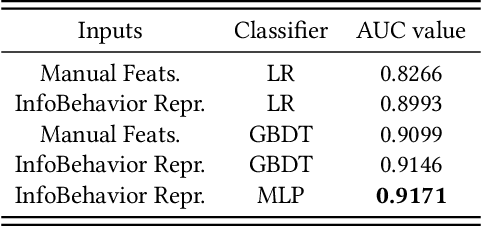
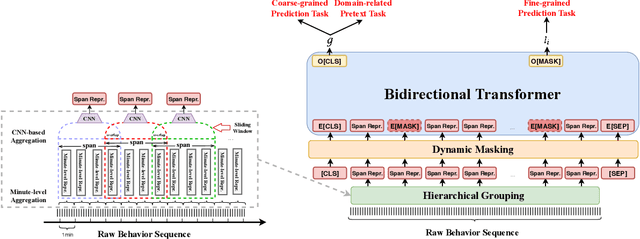
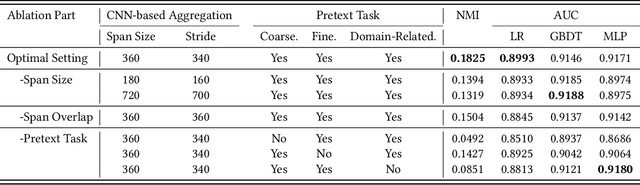
E-commerce companies have to face abnormal sellers who sell potentially-risky products. Typically, the risk can be identified by jointly considering product content (e.g., title and image) and seller behavior. This work focuses on behavior feature extraction as behavior sequences can provide valuable clues for the risk discovery by reflecting the sellers' operation habits. Traditional feature extraction techniques heavily depend on domain experts and adapt poorly to new tasks. In this paper, we propose a self-supervised method InfoBehavior to automatically extract meaningful representations from ultra-long raw behavior sequences instead of the costly feature selection procedure. InfoBehavior utilizes Bidirectional Transformer as feature encoder due to its excellent capability in modeling long-term dependency. However, it is intractable for commodity GPUs because the time and memory required by Transformer grow quadratically with the increase of sequence length. Thus, we propose a hierarchical grouping strategy to aggregate ultra-long raw behavior sequences to length-processable high-level embedding sequences. Moreover, we introduce two types of pretext tasks. Sequence-related pretext task defines a contrastive-based training objective to correctly select the masked-out coarse-grained/fine-grained behavior sequences against other "distractor" behavior sequences; Domain-related pretext task designs a classification training objective to correctly predict the domain-specific statistical results of anomalous behavior. We show that behavior representations from the pre-trained InfoBehavior can be directly used or integrated with features from other side information to support a wide range of downstream tasks. Experimental results demonstrate that InfoBehavior significantly improves the performance of Product Risk Management and Intellectual Property Protection.