 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARM: An AutoRegressive Large Multimodal Model with Unified Discrete Representations
Jun 09, 2026This paper introduces ARM, a discrete representation-based AutoRegressive Model that unifies image understanding, generation, and editing within a next-token prediction framework. ARM is built on three efforts: first, we train a discrete semantic visual tokenizer that maps images into compact token sequences. Our tokenizer is supervised with multiple objectives that jointly promote semantic discriminability, language alignment and faithful reconstruction, thereby supporting diverse tasks in a shared latent space. With this, we train a 7B autoregressive model over large-scale text and image token sequences, seamlessly developing vision-language perception and generation capabilities. Finally, to further improve preference-aligned behavior for text-to-image generation and instruction-guided editing, ARM applies reinforcement learning (RL) to optimize task-level objectives such as visual quality, instruction adherence, and edit consistency. Surprisingly, the results show that RL not only substantially improves performance on the target tasks (e.g., raising WISE overall from 0.50 to 0.56, GEdit-Bench-EN G_O from 5.75 to 6.68), but also induces cross-task synergy between text-to-image generation and editing. Collectively, these findings highlight autoregressive modeling, when paired with strong representations and preference optimization, as a scalable foundation for multimodal intelligence. Code: https://github.com/wdrink/ARM.
Context Unrolling in Omni Models
Apr 23, 2026We present Omni, a unified multimodal model natively trained on diverse modalities, including text, images, videos, 3D geometry, and hidden representations. We find that such training enables Context Unrolling, where the model explicitly reasons across multiple modal representations before producing predictions. This process enables the model to aggregate complementary information across heterogeneous modalities, facilitating a more faithful approximation of the shared multimodal knowledge manifold and improving downstream reasoning fidelity. As a result, Omni achieves strong performance on both multimodal generation and understanding benchmarks, while demonstrating advanced multimodal reasoning capabilities, including in-context generation of text, image, video, and 3D geometry.
LightBagel: A Light-weighted, Double Fusion Framework for Unified Multimodal Understanding and Generation
Oct 27, 2025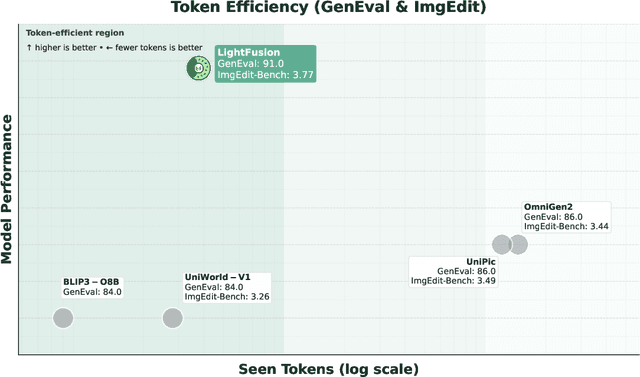
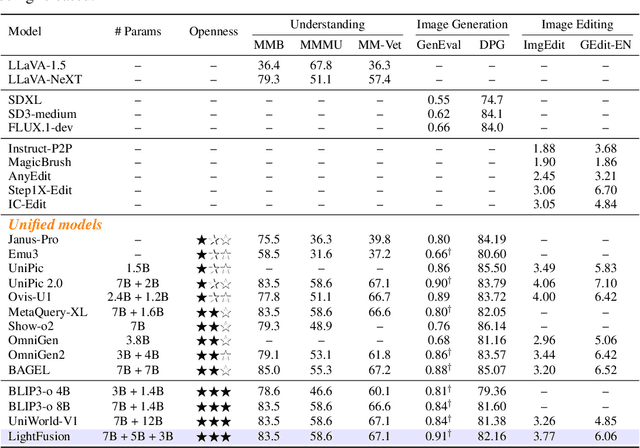
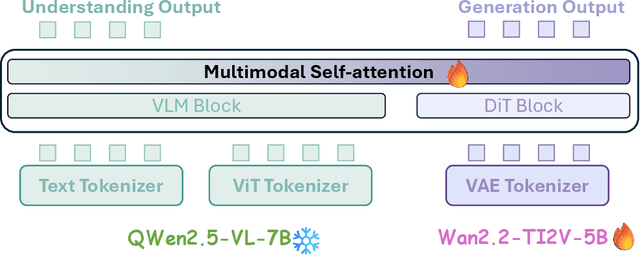
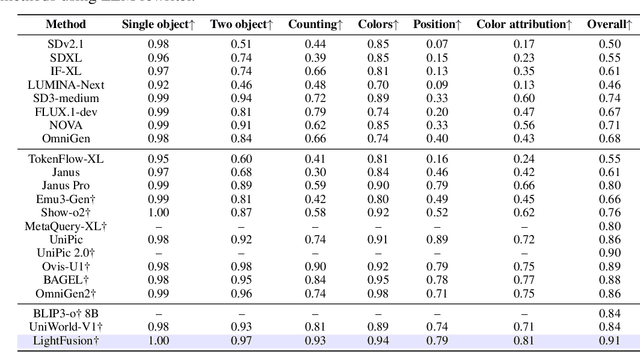
Unified multimodal models have recently shown remarkable gains in both capability and versatility, yet most leading systems are still trained from scratch and require substantial computational resources. In this paper, we show that competitive performance can be obtained far more efficiently by strategically fusing publicly available models specialized for either generation or understanding. Our key design is to retain the original blocks while additionally interleaving multimodal self-attention blocks throughout the networks. This double fusion mechanism (1) effectively enables rich multi-modal fusion while largely preserving the original strengths of the base models, and (2) catalyzes synergistic fusion of high-level semantic representations from the understanding encoder with low-level spatial signals from the generation encoder. By training with only ~ 35B tokens, this approach achieves strong results across multiple benchmarks: 0.91 on GenEval for compositional text-to-image generation, 82.16 on DPG-Bench for complex text-to-image generation, 6.06 on GEditBench, and 3.77 on ImgEdit-Bench for image editing. By fully releasing the entire suite of code, model weights, and datasets, we hope to support future research on unified multimodal modeling.
Emerging Properties in Unified Multimodal Pretraining
May 20, 2025



Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. In this work, we introduce BAGEL, an open0source foundational model that natively supports multimodal understanding and generation. BAGEL is a unified, decoder0only model pretrained on trillions of tokens curated from large0scale interleaved text, image, video, and web data. When scaled with such diverse multimodal interleaved data, BAGEL exhibits emerging capabilities in complex multimodal reasoning. As a result, it significantly outperforms open-source unified models in both multimodal generation and understanding across standard benchmarks, while exhibiting advanced multimodal reasoning abilities such as free-form image manipulation, future frame prediction, 3D manipulation, and world navigation. In the hope of facilitating further opportunities for multimodal research, we share the key findings, pretraining details, data creation protocal, and release our code and checkpoints to the community. The project page is at https://bagel-ai.org/
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Causal Diffusion Transformers for Generative Modeling
Dec 17, 2024We introduce Causal Diffusion as the autoregressive (AR) counterpart of Diffusion models. It is a next-token(s) forecasting framework that is friendly to both discrete and continuous modalities and compatible with existing next-token prediction models like LLaMA and GPT. While recent works attempt to combine diffusion with AR models, we show that introducing sequential factorization to a diffusion model can substantially improve its performance and enables a smooth transition between AR and diffusion generation modes. Hence, we propose CausalFusion - a decoder-only transformer that dual-factorizes data across sequential tokens and diffusion noise levels, leading to state-of-the-art results on the ImageNet generation benchmark while also enjoying the AR advantage of generating an arbitrary number of tokens for in-context reasoning. We further demonstrate CausalFusion's multimodal capabilities through a joint image generation and captioning model, and showcase CausalFusion's ability for zero-shot in-context image manipulations. We hope that this work could provide the community with a fresh perspective on training multimodal models over discrete and continuous data.
Likelihood-Based Text-to-Image Evaluation with Patch-Level Perceptual and Semantic Credit Assignment
Aug 16, 2023Text-to-image synthesis has made encouraging progress and attracted lots of public attention recently. However, popular evaluation metrics in this area, like the Inception Score and Fr'echet Inception Distance, incur several issues. First of all, they cannot explicitly assess the perceptual quality of generated images and poorly reflect the semantic alignment of each text-image pair. Also, they are inefficient and need to sample thousands of images to stabilise their evaluation results. In this paper, we propose to evaluate text-to-image generation performance by directly estimating the likelihood of the generated images using a pre-trained likelihood-based text-to-image generative model, i.e., a higher likelihood indicates better perceptual quality and better text-image alignment. To prevent the likelihood of being dominated by the non-crucial part of the generated image, we propose several new designs to develop a credit assignment strategy based on the semantic and perceptual significance of the image patches. In the experiments, we evaluate the proposed metric on multiple popular text-to-image generation models and datasets in accessing both the perceptual quality and the text-image alignment. Moreover, it can successfully assess the generation ability of these models with as few as a hundred samples, making it very efficient in practice.
Identity-Consistent Aggregation for Video Object Detection
Aug 15, 2023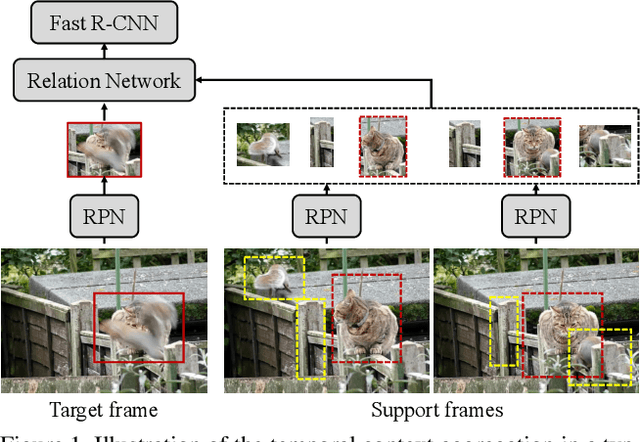



In Video Object Detection (VID), a common practice is to leverage the rich temporal contexts from the video to enhance the object representations in each frame. Existing methods treat the temporal contexts obtained from different objects indiscriminately and ignore their different identities. While intuitively, aggregating local views of the same object in different frames may facilitate a better understanding of the object. Thus, in this paper, we aim to enable the model to focus on the identity-consistent temporal contexts of each object to obtain more comprehensive object representations and handle the rapid object appearance variations such as occlusion, motion blur, etc. However, realizing this goal on top of existing VID models faces low-efficiency problems due to their redundant region proposals and nonparallel frame-wise prediction manner. To aid this, we propose ClipVID, a VID model equipped with Identity-Consistent Aggregation (ICA) layers specifically designed for mining fine-grained and identity-consistent temporal contexts. It effectively reduces the redundancies through the set prediction strategy, making the ICA layers very efficient and further allowing us to design an architecture that makes parallel clip-wise predictions for the whole video clip. Extensive experimental results demonstrate the superiority of our method: a state-of-the-art (SOTA) performance (84.7% mAP) on the ImageNet VID dataset while running at a speed about 7x faster (39.3 fps) than previous SOTAs.
Prompt Switch: Efficient CLIP Adaptation for Text-Video Retrieval
Aug 15, 2023



In text-video retrieval, recent works have benefited from the powerful learning capabilities of pre-trained text-image foundation models (e.g., CLIP) by adapting them to the video domain. A critical problem for them is how to effectively capture the rich semantics inside the video using the image encoder of CLIP. To tackle this, state-of-the-art methods adopt complex cross-modal modeling techniques to fuse the text information into video frame representations, which, however, incurs severe efficiency issues in large-scale retrieval systems as the video representations must be recomputed online for every text query. In this paper, we discard this problematic cross-modal fusion process and aim to learn semantically-enhanced representations purely from the video, so that the video representations can be computed offline and reused for different texts. Concretely, we first introduce a spatial-temporal "Prompt Cube" into the CLIP image encoder and iteratively switch it within the encoder layers to efficiently incorporate the global video semantics into frame representations. We then propose to apply an auxiliary video captioning objective to train the frame representations, which facilitates the learning of detailed video semantics by providing fine-grained guidance in the semantic space. With a naive temporal fusion strategy (i.e., mean-pooling) on the enhanced frame representations, we obtain state-of-the-art performances on three benchmark datasets, i.e., MSR-VTT, MSVD, and LSMDC.
Learning Distinct and Representative Modes for Image Captioning
Sep 17, 2022

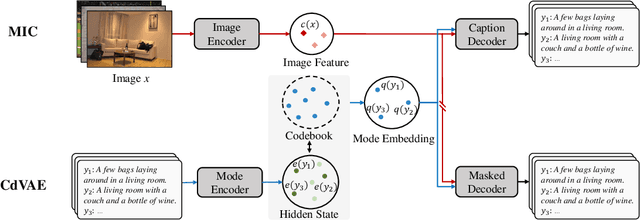
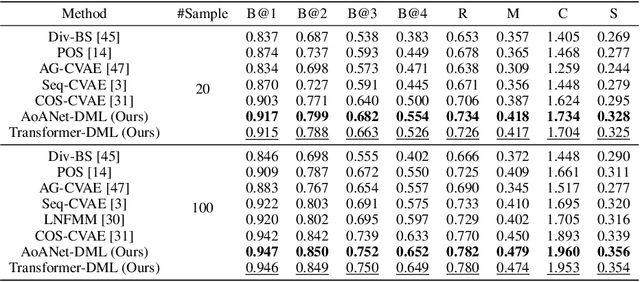
Over the years, state-of-the-art (SoTA) image captioning methods have achieved promising results on some evaluation metrics (e.g., CIDEr). However, recent findings show that the captions generated by these methods tend to be biased toward the "average" caption that only captures the most general mode (a.k.a, language pattern) in the training corpus, i.e., the so-called mode collapse problem. Affected by it, the generated captions are limited in diversity and usually less informative than natural image descriptions made by humans. In this paper, we seek to avoid this problem by proposing a Discrete Mode Learning (DML) paradigm for image captioning. Our innovative idea is to explore the rich modes in the training caption corpus to learn a set of "mode embeddings", and further use them to control the mode of the generated captions for existing image captioning models. Specifically, the proposed DML optimizes a dual architecture that consists of an image-conditioned discrete variational autoencoder (CdVAE) branch and a mode-conditioned image captioning (MIC) branch. The CdVAE branch maps each image caption to one of the mode embeddings stored in a learned codebook, and is trained with a pure non-autoregressive generation objective to make the modes distinct and representative. The MIC branch can be simply modified from an existing image captioning model, where the mode embedding is added to the original word embeddings as the control signal. In the experiments, we apply the proposed DML to two widely used image captioning models, Transformer and AoANet. The results show that the learned mode embedding successfully facilitates these models to generate high-quality image captions with different modes, further leading to better performance for both diversity and quality on the MSCOCO dataset.