 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Few Shot CLIP Benchmarks: A Critical Analysis in the Inductive Setting
Jul 28, 2025CLIP is a foundational model with transferable classification performance in the few-shot setting. Several methods have shown improved performance of CLIP using few-shot examples. However, so far, all these techniques have been benchmarked using standard few-shot datasets. We argue that this mode of evaluation does not provide a true indication of the inductive generalization ability using few-shot examples. As most datasets have been seen by the CLIP model, the resultant setting can be termed as partially transductive. To solve this, we propose a pipeline that uses an unlearning technique to obtain true inductive baselines. In this new inductive setting, the methods show a significant drop in performance (-55% on average among 13 baselines with multiple datasets). We validate the unlearning technique using oracle baselines. An improved few-shot classification technique is proposed that consistently obtains state-of-the-art performance over 13 other recent baseline methods on a comprehensive analysis with 5880 experiments - varying the datasets, differing number of few-shot examples, unlearning setting, and with different seeds. Thus, we identify the issue with the evaluation of CLIP-based few-shot classification, provide a solution using unlearning, propose new benchmarks, and provide an improved method.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
GAPNet: Granularity Attention Network with Anatomy-Prior-Constraint for Carotid Artery Segmentation
Jun 27, 2024



Atherosclerosis is a chronic, progressive disease that primarily affects the arterial walls. It is one of the major causes of cardiovascular disease. Magnetic Resonance (MR) black-blood vessel wall imaging (BB-VWI) offers crucial insights into vascular disease diagnosis by clearly visualizing vascular structures. However, the complex anatomy of the neck poses challenges in distinguishing the carotid artery (CA) from surrounding structures, especially with changes like atherosclerosis. In order to address these issues, we propose GAPNet, which is a consisting of a novel geometric prior deduced from.
DSCA: A Digital Subtraction Angiography Sequence Dataset and Spatio-Temporal Model for Cerebral Artery Segmentation
Jun 01, 2024



Cerebrovascular diseases (CVDs) remain a leading cause of global disability and mortality. Digital Subtraction Angiography (DSA) sequences, recognized as the golden standard for diagnosing CVDs, can clearly visualize the dynamic flow and reveal pathological conditions within the cerebrovasculature. Therefore, precise segmentation of cerebral arteries (CAs) and classification between their main trunks and branches are crucial for physicians to accurately quantify diseases. However, achieving accurate CA segmentation in DSA sequences remains a challenging task due to small vessels with low contrast, and ambiguity between vessels and residual skull structures. Moreover, the lack of publicly available datasets limits exploration in the field. In this paper, we introduce a DSA Sequence-based Cerebral Artery segmentation dataset (DSCA), the first publicly accessible dataset designed specifically for pixel-level semantic segmentation of CAs. Additionally, we propose DSANet, a spatio-temporal network for CA segmentation in DSA sequences. Unlike existing DSA segmentation methods that focus only on a single frame, the proposed DSANet introduces a separate temporal encoding branch to capture dynamic vessel details across multiple frames. To enhance small vessel segmentation and improve vessel connectivity, we design a novel TemporalFormer module to capture global context and correlations among sequential frames. Furthermore, we develop a Spatio-Temporal Fusion (STF) module to effectively integrate spatial and temporal features from the encoder. Extensive experiments demonstrate that DSANet outperforms other state-of-the-art methods in CA segmentation, achieving a Dice of 0.9033.
RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness
May 27, 2024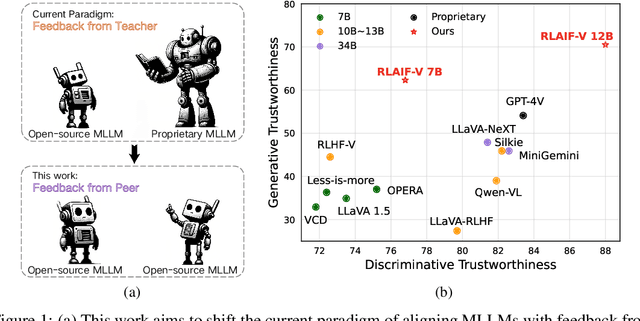
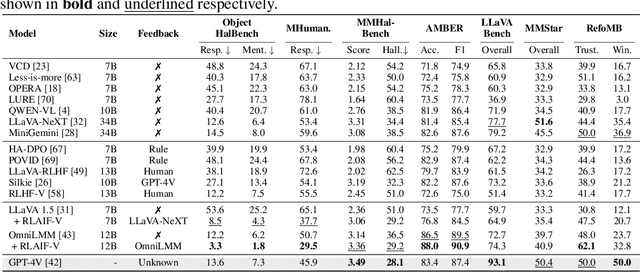
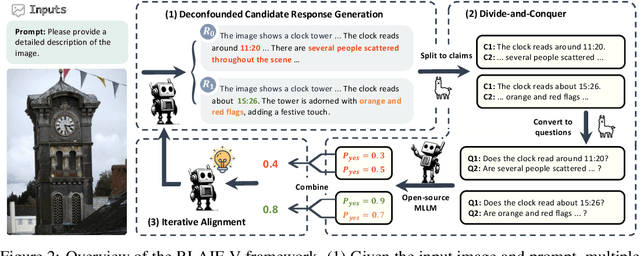
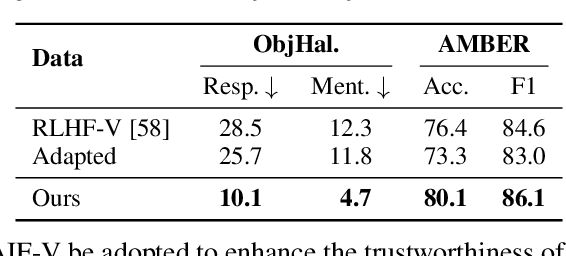
Learning from feedback reduces the hallucination of multimodal large language models (MLLMs) by aligning them with human preferences. While traditional methods rely on labor-intensive and time-consuming manual labeling, recent approaches employing models as automatic labelers have shown promising results without human intervention. However, these methods heavily rely on costly proprietary models like GPT-4V, resulting in scalability issues. Moreover, this paradigm essentially distills the proprietary models to provide a temporary solution to quickly bridge the performance gap. As this gap continues to shrink, the community is soon facing the essential challenge of aligning MLLMs using labeler models of comparable capability. In this work, we introduce RLAIF-V, a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. RLAIF-V maximally exploits the open-source feedback from two perspectives, including high-quality feedback data and online feedback learning algorithm. Extensive experiments on seven benchmarks in both automatic and human evaluation show that RLAIF-V substantially enhances the trustworthiness of models without sacrificing performance on other tasks. Using a 34B model as labeler, RLAIF-V 7B model reduces object hallucination by 82.9\% and overall hallucination by 42.1\%, outperforming the labeler model. Remarkably, RLAIF-V also reveals the self-alignment potential of open-source MLLMs, where a 12B model can learn from the feedback of itself to achieve less than 29.5\% overall hallucination rate, surpassing GPT-4V (45.9\%) by a large margin. The results shed light on a promising route to enhance the efficacy of leading-edge MLLMs.
Grouping Boundary Proposals for Fast Interactive Image Segmentation
Sep 08, 2023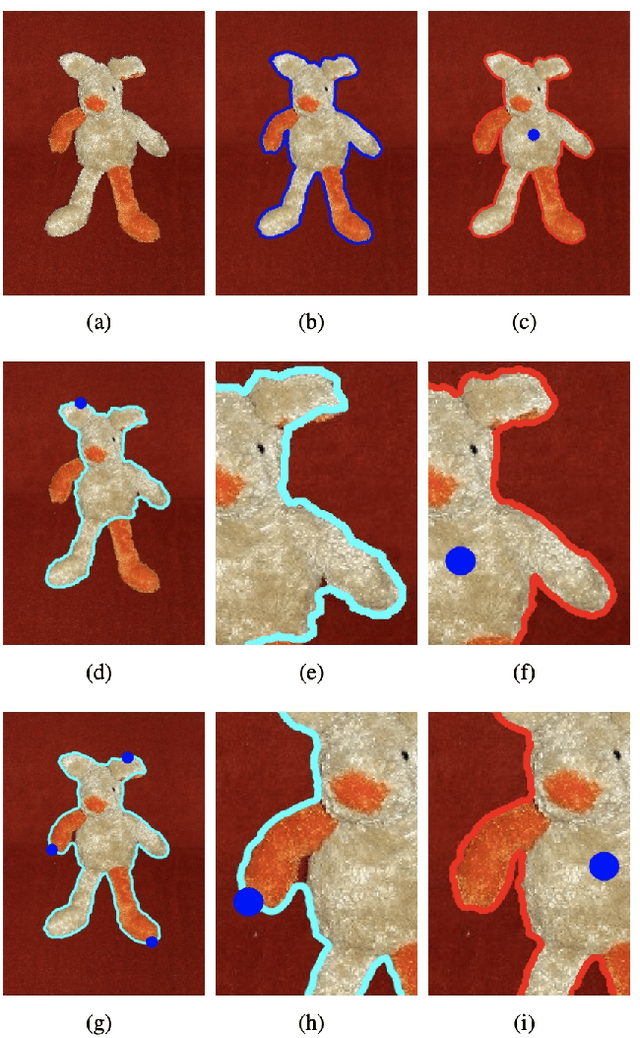
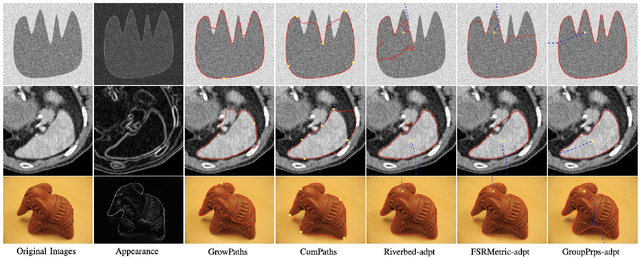


Geodesic models are known as an efficient tool for solving various image segmentation problems. Most of existing approaches only exploit local pointwise image features to track geodesic paths for delineating the objective boundaries. However, such a segmentation strategy cannot take into account the connectivity of the image edge features, increasing the risk of shortcut problem, especially in the case of complicated scenario. In this work, we introduce a new image segmentation model based on the minimal geodesic framework in conjunction with an adaptive cut-based circular optimal path computation scheme and a graph-based boundary proposals grouping scheme. Specifically, the adaptive cut can disconnect the image domain such that the target contours are imposed to pass through this cut only once. The boundary proposals are comprised of precomputed image edge segments, providing the connectivity information for our segmentation model. These boundary proposals are then incorporated into the proposed image segmentation model, such that the target segmentation contours are made up of a set of selected boundary proposals and the corresponding geodesic paths linking them. Experimental results show that the proposed model indeed outperforms state-of-the-art minimal paths-based image segmentation approaches.
Identity-Consistent Aggregation for Video Object Detection
Aug 15, 2023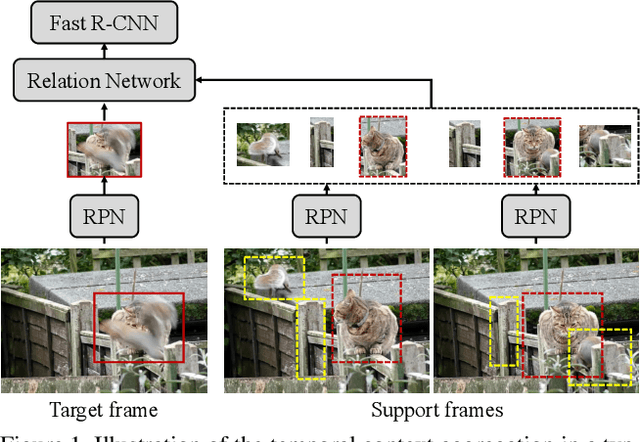



In Video Object Detection (VID), a common practice is to leverage the rich temporal contexts from the video to enhance the object representations in each frame. Existing methods treat the temporal contexts obtained from different objects indiscriminately and ignore their different identities. While intuitively, aggregating local views of the same object in different frames may facilitate a better understanding of the object. Thus, in this paper, we aim to enable the model to focus on the identity-consistent temporal contexts of each object to obtain more comprehensive object representations and handle the rapid object appearance variations such as occlusion, motion blur, etc. However, realizing this goal on top of existing VID models faces low-efficiency problems due to their redundant region proposals and nonparallel frame-wise prediction manner. To aid this, we propose ClipVID, a VID model equipped with Identity-Consistent Aggregation (ICA) layers specifically designed for mining fine-grained and identity-consistent temporal contexts. It effectively reduces the redundancies through the set prediction strategy, making the ICA layers very efficient and further allowing us to design an architecture that makes parallel clip-wise predictions for the whole video clip. Extensive experimental results demonstrate the superiority of our method: a state-of-the-art (SOTA) performance (84.7% mAP) on the ImageNet VID dataset while running at a speed about 7x faster (39.3 fps) than previous SOTAs.
Prompt Switch: Efficient CLIP Adaptation for Text-Video Retrieval
Aug 15, 2023In text-video retrieval, recent works have benefited from the powerful learning capabilities of pre-trained text-image foundation models (e.g., CLIP) by adapting them to the video domain. A critical problem for them is how to effectively capture the rich semantics inside the video using the image encoder of CLIP. To tackle this, state-of-the-art methods adopt complex cross-modal modeling techniques to fuse the text information into video frame representations, which, however, incurs severe efficiency issues in large-scale retrieval systems as the video representations must be recomputed online for every text query. In this paper, we discard this problematic cross-modal fusion process and aim to learn semantically-enhanced representations purely from the video, so that the video representations can be computed offline and reused for different texts. Concretely, we first introduce a spatial-temporal "Prompt Cube" into the CLIP image encoder and iteratively switch it within the encoder layers to efficiently incorporate the global video semantics into frame representations. We then propose to apply an auxiliary video captioning objective to train the frame representations, which facilitates the learning of detailed video semantics by providing fine-grained guidance in the semantic space. With a naive temporal fusion strategy (i.e., mean-pooling) on the enhanced frame representations, we obtain state-of-the-art performances on three benchmark datasets, i.e., MSR-VTT, MSVD, and LSMDC.
COCO-O: A Benchmark for Object Detectors under Natural Distribution Shifts
Aug 02, 2023



Practical object detection application can lose its effectiveness on image inputs with natural distribution shifts. This problem leads the research community to pay more attention on the robustness of detectors under Out-Of-Distribution (OOD) inputs. Existing works construct datasets to benchmark the detector's OOD robustness for a specific application scenario, e.g., Autonomous Driving. However, these datasets lack universality and are hard to benchmark general detectors built on common tasks such as COCO. To give a more comprehensive robustness assessment, we introduce COCO-O(ut-of-distribution), a test dataset based on COCO with 6 types of natural distribution shifts. COCO-O has a large distribution gap with training data and results in a significant 55.7% relative performance drop on a Faster R-CNN detector. We leverage COCO-O to conduct experiments on more than 100 modern object detectors to investigate if their improvements are credible or just over-fitting to the COCO test set. Unfortunately, most classic detectors in early years do not exhibit strong OOD generalization. We further study the robustness effect on recent breakthroughs of detector's architecture design, augmentation and pre-training techniques. Some empirical findings are revealed: 1) Compared with detection head or neck, backbone is the most important part for robustness; 2) An end-to-end detection transformer design brings no enhancement, and may even reduce robustness; 3) Large-scale foundation models have made a great leap on robust object detection. We hope our COCO-O could provide a rich testbed for robustness study of object detection. The dataset will be available at https://github.com/alibaba/easyrobust/tree/main/benchmarks/coco_o.