 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Self-Reconfiguration Planning for Deformable Quadrilateral Modular Robots
Jan 27, 2026For lattice modular self-reconfigurable robots (MSRRs), maintaining stable connections during reconfiguration is crucial for physical feasibility and deployability. This letter presents a novel self-reconfiguration planning algorithm for deformable quadrilateral MSRRs that guarantees stable connection. The method first constructs feasible connect/disconnect actions using a virtual graph representation, and then organizes these actions into a valid execution sequence through a Dependence-based Reverse Tree (DRTree) that resolves interdependencies. We also prove that reconfiguration sequences satisfying motion characteristics exist for any pair of configurations with seven or more modules (excluding linear topologies). Finally, comparisons with a modified BiRRT algorithm highlight the superior efficiency and stability of our approach, while deployment on a physical robotic platform confirms its practical feasibility.
Rhombot: Rhombus-shaped Modular Robots for Stable, Medium-Independent Reconfiguration Motion
Jan 27, 2026In this paper, we present Rhombot, a novel deformable planar lattice modular self-reconfigurable robot (MSRR) with a rhombus shaped module. Each module consists of a parallelogram skeleton with a single centrally mounted actuator that enables folding and unfolding along its diagonal. The core design philosophy is to achieve essential MSRR functionalities such as morphing, docking, and locomotion with minimal control complexity. This enables a continuous and stable reconfiguration process that is independent of the surrounding medium, allowing the system to reliably form various configurations in diverse environments. To leverage the unique kinematics of Rhombot, we introduce morphpivoting, a novel motion primitive for reconfiguration that differs from advanced MSRR systems, and propose a strategy for its continuous execution. Finally, a series of physical experiments validate the module's stable reconfiguration ability, as well as its positional and docking accuracy.
CORD: Bridging the Audio-Text Reasoning Gap via Weighted On-policy Cross-modal Distillation
Jan 23, 2026Large Audio Language Models (LALMs) have garnered significant research interest. Despite being built upon text-based large language models (LLMs), LALMs frequently exhibit a degradation in knowledge and reasoning capabilities. We hypothesize that this limitation stems from the failure of current training paradigms to effectively bridge the acoustic-semantic gap within the feature representation space. To address this challenge, we propose CORD, a unified alignment framework that performs online cross-modal self-distillation. Specifically, it aligns audio-conditioned reasoning with its text-conditioned counterpart within a unified model. Leveraging the text modality as an internal teacher, CORD performs multi-granularity alignment throughout the audio rollout process. At the token level, it employs on-policy reverse KL divergence with importance-aware weighting to prioritize early and semantically critical tokens. At the sequence level, CORD introduces a judge-based global reward to optimize complete reasoning trajectories via Group Relative Policy Optimization (GRPO). Empirical results across multiple benchmarks demonstrate that CORD consistently enhances audio-conditioned reasoning and substantially bridges the audio-text performance gap with only 80k synthetic training samples, validating the efficacy and data efficiency of our on-policy, multi-level cross-modal alignment approach.
MoE Adapter for Large Audio Language Models: Sparsity, Disentanglement, and Gradient-Conflict-Free
Jan 08, 2026Extending the input modality of Large Language Models~(LLMs) to the audio domain is essential for achieving comprehensive multimodal perception. However, it is well-known that acoustic information is intrinsically \textit{heterogeneous}, entangling attributes such as speech, music, and environmental context. Existing research is limited to a dense, parameter-shared adapter to model these diverse patterns, which induces \textit{gradient conflict} during optimization, as parameter updates required for distinct attributes contradict each other. To address this limitation, we introduce the \textit{\textbf{MoE-Adapter}}, a sparse Mixture-of-Experts~(MoE) architecture designed to decouple acoustic information. Specifically, it employs a dynamic gating mechanism that routes audio tokens to specialized experts capturing complementary feature subspaces while retaining shared experts for global context, thereby mitigating gradient conflicts and enabling fine-grained feature learning. Comprehensive experiments show that the MoE-Adapter achieves superior performance on both audio semantic and paralinguistic tasks, consistently outperforming dense linear baselines with comparable computational costs. Furthermore, we will release the related code and models to facilitate future research.
TDRM: Smooth Reward Models with Temporal Difference for LLM RL and Inference
Sep 18, 2025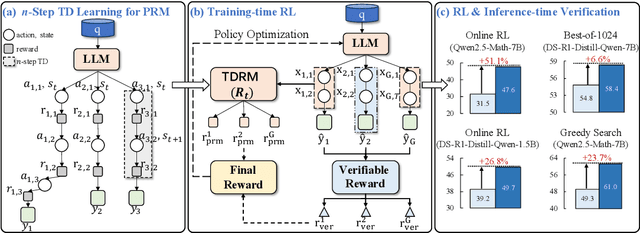
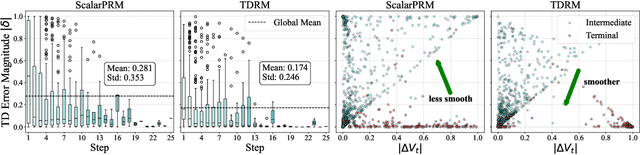

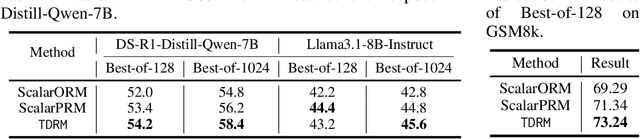
Reward models are central to both reinforcement learning (RL) with language models and inference-time verification. However, existing reward models often lack temporal consistency, leading to ineffective policy updates and unstable RL training. We introduce TDRM, a method for learning smoother and more reliable reward models by minimizing temporal differences during training. This temporal-difference (TD) regularization produces smooth rewards and improves alignment with long-term objectives. Incorporating TDRM into the actor-critic style online RL loop yields consistent empirical gains. It is worth noting that TDRM is a supplement to verifiable reward methods, and both can be used in series. Experiments show that TD-trained process reward models (PRMs) improve performance across Best-of-N (up to 6.6%) and tree-search (up to 23.7%) settings. When combined with Reinforcement Learning with Verifiable Rewards (RLVR), TD-trained PRMs lead to more data-efficient RL -- achieving comparable performance with just 2.5k data to what baseline methods require 50.1k data to attain -- and yield higher-quality language model policies on 8 model variants (5 series), e.g., Qwen2.5-(0.5B, 1,5B), GLM4-9B-0414, GLM-Z1-9B-0414, Qwen2.5-Math-(1.5B, 7B), and DeepSeek-R1-Distill-Qwen-(1.5B, 7B). We release all code at https://github.com/THUDM/TDRM.
ReST-RL: Achieving Accurate Code Reasoning of LLMs with Optimized Self-Training and Decoding
Aug 27, 2025With respect to improving the reasoning accuracy of LLMs, the representative reinforcement learning (RL) method GRPO faces failure due to insignificant reward variance, while verification methods based on process reward models (PRMs) suffer from difficulties with training data acquisition and verification effectiveness. To tackle these problems, this paper introduces ReST-RL, a unified LLM RL paradigm that significantly improves LLM's code reasoning ability by combining an improved GRPO algorithm with a meticulously designed test time decoding method assisted by a value model (VM). As the first stage of policy reinforcement, ReST-GRPO adopts an optimized ReST algorithm to filter and assemble high-value training data, increasing the reward variance of GRPO sampling, thus improving the effectiveness and efficiency of training. After the basic reasoning ability of LLM policy has been improved, we further propose a test time decoding optimization method called VM-MCTS. Through Monte-Carlo Tree Search (MCTS), we collect accurate value targets with no annotation required, on which VM training is based. When decoding, the VM is deployed by an adapted MCTS algorithm to provide precise process signals as well as verification scores, assisting the LLM policy to achieve high reasoning accuracy. We validate the effectiveness of the proposed RL paradigm through extensive experiments on coding problems. Upon comparison, our approach significantly outperforms other reinforcement training baselines (e.g., naive GRPO and ReST-DPO), as well as decoding and verification baselines (e.g., PRM-BoN and ORM-MCTS) on well-known coding benchmarks of various levels (e.g., APPS, BigCodeBench, and HumanEval), indicating its power to strengthen the reasoning ability of LLM policies. Codes for our project can be found at https://github.com/THUDM/ReST-RL.
Benchmarking Feature Upsampling Methods for Vision Foundation Models using Interactive Segmentation
May 04, 2025Vision Foundation Models (VFMs) are large-scale, pre-trained models that serve as general-purpose backbones for various computer vision tasks. As VFMs' popularity grows, there is an increasing interest in understanding their effectiveness for dense prediction tasks. However, VFMs typically produce low-resolution features, limiting their direct applicability in this context. One way to tackle this limitation is by employing a task-agnostic feature upsampling module that refines VFM features resolution. To assess the effectiveness of this approach, we investigate Interactive Segmentation (IS) as a novel benchmark for evaluating feature upsampling methods on VFMs. Due to its inherent multimodal input, consisting of an image and a set of user-defined clicks, as well as its dense mask output, IS creates a challenging environment that demands comprehensive visual scene understanding. Our benchmarking experiments show that selecting appropriate upsampling strategies significantly improves VFM features quality. The code is released at https://github.com/havrylovv/iSegProbe
Integration Flow Models
Apr 28, 2025Ordinary differential equation (ODE) based generative models have emerged as a powerful approach for producing high-quality samples in many applications. However, the ODE-based methods either suffer the discretization error of numerical solvers of ODE, which restricts the quality of samples when only a few NFEs are used, or struggle with training instability. In this paper, we proposed Integration Flow, which directly learns the integral of ODE-based trajectory paths without solving the ODE functions. Moreover, Integration Flow explicitly incorporates the target state $\mathbf{x}_0$ as the anchor state in guiding the reverse-time dynamics. We have theoretically proven this can contribute to both stability and accuracy. To the best of our knowledge, Integration Flow is the first model with a unified structure to estimate ODE-based generative models and the first to show the exact straightness of 1-Rectified Flow without reflow. Through theoretical analysis and empirical evaluations, we show that Integration Flows achieve improved performance when it is applied to existing ODE-based models, such as diffusion models, Rectified Flows, and PFGM++. Specifically, Integration Flow achieves one-step generation on CIFAR10 with FIDs of 2.86 for the Variance Exploding (VE) diffusion model, 3.36 for rectified flow without reflow, and 2.91 for PFGM++; and on ImageNet with FIDs of 4.09 for VE diffusion model, 4.35 for rectified flow without reflow and 4.15 for PFGM++.
LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models
Apr 18, 2025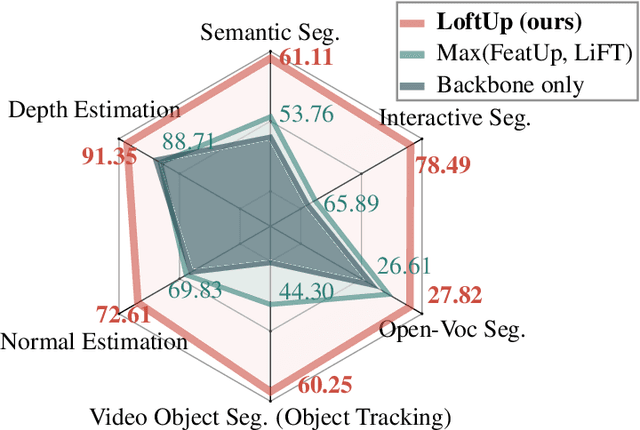
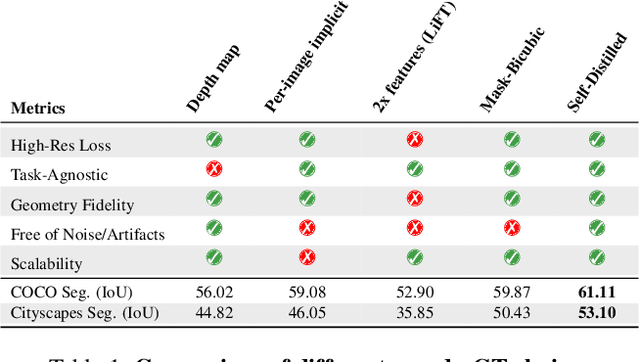
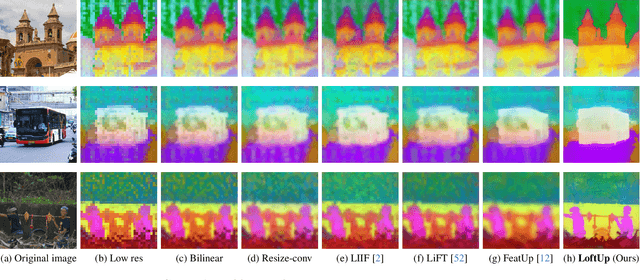
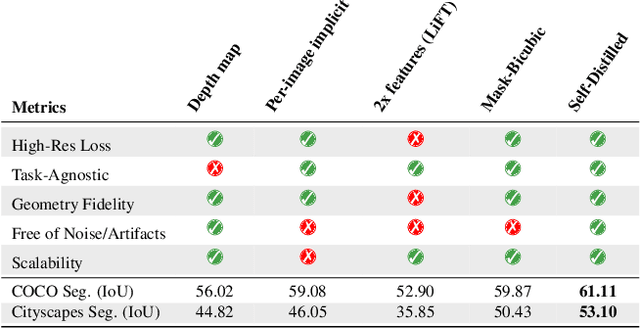
Vision foundation models (VFMs) such as DINOv2 and CLIP have achieved impressive results on various downstream tasks, but their limited feature resolution hampers performance in applications requiring pixel-level understanding. Feature upsampling offers a promising direction to address this challenge. In this work, we identify two critical factors for enhancing feature upsampling: the upsampler architecture and the training objective. For the upsampler architecture, we introduce a coordinate-based cross-attention transformer that integrates the high-resolution images with coordinates and low-resolution VFM features to generate sharp, high-quality features. For the training objective, we propose constructing high-resolution pseudo-groundtruth features by leveraging class-agnostic masks and self-distillation. Our approach effectively captures fine-grained details and adapts flexibly to various input and feature resolutions. Through experiments, we demonstrate that our approach significantly outperforms existing feature upsampling techniques across various downstream tasks. Our code is released at https://github.com/andrehuang/loftup.