 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMP: Lift Image-Editing as General 3D Priors for Open-world Manipulation
Apr 09, 2026Human-like generalization in open-world remains a fundamental challenge for robotic manipulation. Existing learning-based methods, including reinforcement learning, imitation learning, and vision-language-action-models (VLAs), often struggle with novel tasks and unseen environments. Another promising direction is to explore generalizable representations that capture fine-grained spatial and geometric relations for open-world manipulation. While large-language-model (LLMs) and vision-language-model (VLMs) provide strong semantic reasoning based on language or annotated 2D representations, their limited 3D awareness restricts their applicability to fine-grained manipulation. To address this, we propose LAMP, which lifts image-editing as 3D priors to extract inter-object 3D transformations as continuous, geometry-aware representations. Our key insight is that image-editing inherently encodes rich 2D spatial cues, and lifting these implicit cues into 3D transformations provides fine-grained and accurate guidance for open-world manipulation. Extensive experiments demonstrate that \codename delivers precise 3D transformations and achieves strong zero-shot generalization in open-world manipulation. Project page: https://zju3dv.github.io/LAMP/.
SODA: Semi On-Policy Black-Box Distillation for Large Language Models
Apr 04, 2026Black-box knowledge distillation for large language models presents a strict trade-off. Simple off-policy methods (e.g., sequence-level knowledge distillation) struggle to correct the student's inherent errors. Fully on-policy methods (e.g., Generative Adversarial Distillation) solve this via adversarial training but introduce well-known training instability and crippling computational overhead. To address this dilemma, we propose SODA (Semi On-policy Distillation with Alignment), a highly efficient alternative motivated by the inherent capability gap between frontier teachers and much smaller base models. Because a compact student model's natural, zero-shot responses are almost strictly inferior to the powerful teacher's targets, we can construct a highly effective contrastive signal simply by pairing the teacher's optimal response with a one-time static snapshot of the student's outputs. This demonstrates that exposing the small student to its own static inferior behaviors is sufficient for high-quality distribution alignment, eliminating the need for costly dynamic rollouts and fragile adversarial balancing. Extensive evaluations across four compact Qwen2.5 and Llama-3 models validate this semi on-policy paradigm. SODA matches or outperforms the state-of-the-art methods on 15 out of 16 benchmark results. More importantly, it achieves this superior distillation quality while training 10 times faster, consuming 27% less peak GPU memory, and completely eliminating adversarial instability.
Climate Prompting: Generating the Madden-Julian Oscillation using Video Diffusion and Low-Dimensional Conditioning
Mar 23, 2026Generative Deep Learning is a powerful tool for modeling of the Madden-Julian oscillation (MJO) in the tropics, yet its relationship to traditional theoretical frameworks remains poorly understood. Here we propose a video diffusion model, trained on atmospheric reanalysis, to synthetize long MJO sequences conditioned on key low-dimensional metrics. The generated MJOs capture key features including composites, power spectra and multiscale structures including convectively coupled waves, despite some bias. We then prompt the model to generate more tractable MJOs based on intentionally idealized low-dimensional conditionings, for example a perpetual MJO, an isolated modulation by seasons and/or the El Nino-Southern Oscillation, and so on. This enables deconstructing the underlying processes and identifying physical drivers. The present approach provides a practical framework for bridging the gap between low-dimensional MJO theory and high-resolution atmospheric complexity and will help tropical atmosphere prediction.
RMPL: Relation-aware Multi-task Progressive Learning with Stage-wise Training for Multimedia Event Extraction
Feb 14, 2026Multimedia Event Extraction (MEE) aims to identify events and their arguments from documents that contain both text and images. It requires grounding event semantics across different modalities. Progress in MEE is limited by the lack of annotated training data. M2E2 is the only established benchmark, but it provides annotations only for evaluation. This makes direct supervised training impractical. Existing methods mainly rely on cross-modal alignment or inference-time prompting with Vision--Language Models (VLMs). These approaches do not explicitly learn structured event representations and often produce weak argument grounding in multimodal settings. To address these limitations, we propose RMPL, a Relation-aware Multi-task Progressive Learning framework for MEE under low-resource conditions. RMPL incorporates heterogeneous supervision from unimodal event extraction and multimedia relation extraction with stage-wise training. The model is first trained with a unified schema to learn shared event-centric representations across modalities. It is then fine-tuned for event mention identification and argument role extraction using mixed textual and visual data. Experiments on the M2E2 benchmark with multiple VLMs show consistent improvements across different modality settings.
A Large-Scale Dataset for Molecular Structure-Language Description via a Rule-Regularized Method
Feb 02, 2026Molecular function is largely determined by structure. Accurately aligning molecular structure with natural language is therefore essential for enabling large language models (LLMs) to reason about downstream chemical tasks. However, the substantial cost of human annotation makes it infeasible to construct large-scale, high-quality datasets of structure-grounded descriptions. In this work, we propose a fully automated annotation framework for generating precise molecular structure descriptions at scale. Our approach builds upon and extends a rule-based chemical nomenclature parser to interpret IUPAC names and construct enriched, structured XML metadata that explicitly encodes molecular structure. This metadata is then used to guide LLMs in producing accurate natural-language descriptions. Using this framework, we curate a large-scale dataset of approximately $163$k molecule-description pairs. A rigorous validation protocol combining LLM-based and expert human evaluation on a subset of $2,000$ molecules demonstrates a high description precision of $98.6\%$. The resulting dataset provides a reliable foundation for future molecule-language alignment, and the proposed annotation method is readily extensible to larger datasets and broader chemical tasks that rely on structural descriptions.
LightCity: An Urban Dataset for Outdoor Inverse Rendering and Reconstruction under Multi-illumination Conditions
Feb 01, 2026Inverse rendering in urban scenes is pivotal for applications like autonomous driving and digital twins. Yet, it faces significant challenges due to complex illumination conditions, including multi-illumination and indirect light and shadow effects. However, the effects of these challenges on intrinsic decomposition and 3D reconstruction have not been explored due to the lack of appropriate datasets. In this paper, we present LightCity, a novel high-quality synthetic urban dataset featuring diverse illumination conditions with realistic indirect light and shadow effects. LightCity encompasses over 300 sky maps with highly controllable illumination, varying scales with street-level and aerial perspectives over 50K images, and rich properties such as depth, normal, material components, light and indirect light, etc. Besides, we leverage LightCity to benchmark three fundamental tasks in the urban environments and conduct a comprehensive analysis of these benchmarks, laying a robust foundation for advancing related research.
Prior-Guided DETR for Ultrasound Nodule Detection
Jan 05, 2026Accurate detection of ultrasound nodules is essential for the early diagnosis and treatment of thyroid and breast cancers. However, this task remains challenging due to irregular nodule shapes, indistinct boundaries, substantial scale variations, and the presence of speckle noise that degrades structural visibility. To address these challenges, we propose a prior-guided DETR framework specifically designed for ultrasound nodule detection. Instead of relying on purely data-driven feature learning, the proposed framework progressively incorporates different prior knowledge at multiple stages of the network. First, a Spatially-adaptive Deformable FFN with Prior Regularization (SDFPR) is embedded into the CNN backbone to inject geometric priors into deformable sampling, stabilizing feature extraction for irregular and blurred nodules. Second, a Multi-scale Spatial-Frequency Feature Mixer (MSFFM) is designed to extract multi-scale structural priors, where spatial-domain processing emphasizes contour continuity and boundary cues, while frequency-domain modeling captures global morphology and suppresses speckle noise. Furthermore, a Dense Feature Interaction (DFI) mechanism propagates and exploits these prior-modulated features across all encoder layers, enabling the decoder to enhance query refinement under consistent geometric and structural guidance. Experiments conducted on two clinically collected thyroid ultrasound datasets (Thyroid I and Thyroid II) and two public benchmarks (TN3K and BUSI) for thyroid and breast nodules demonstrate that the proposed method achieves superior accuracy compared with 18 detection methods, particularly in detecting morphologically complex nodules.The source code is publicly available at https://github.com/wjj1wjj/Ultrasound-DETR.
Nodule-DETR: A Novel DETR Architecture with Frequency-Channel Attention for Ultrasound Thyroid Nodule Detection
Jan 05, 2026Thyroid cancer is the most common endocrine malignancy, and its incidence is rising globally. While ultrasound is the preferred imaging modality for detecting thyroid nodules, its diagnostic accuracy is often limited by challenges such as low image contrast and blurred nodule boundaries. To address these issues, we propose Nodule-DETR, a novel detection transformer (DETR) architecture designed for robust thyroid nodule detection in ultrasound images. Nodule-DETR introduces three key innovations: a Multi-Spectral Frequency-domain Channel Attention (MSFCA) module that leverages frequency analysis to enhance features of low-contrast nodules; a Hierarchical Feature Fusion (HFF) module for efficient multi-scale integration; and Multi-Scale Deformable Attention (MSDA) to flexibly capture small and irregularly shaped nodules. We conducted extensive experiments on a clinical dataset of real-world thyroid ultrasound images. The results demonstrate that Nodule-DETR achieves state-of-the-art performance, outperforming the baseline model by a significant margin of 0.149 in mAP@0.5:0.95. The superior accuracy of Nodule-DETR highlights its significant potential for clinical application as an effective tool in computer-aided thyroid diagnosis. The code of work is available at https://github.com/wjj1wjj/Nodule-DETR.
Shared Spatial Memory Through Predictive Coding
Nov 06, 2025

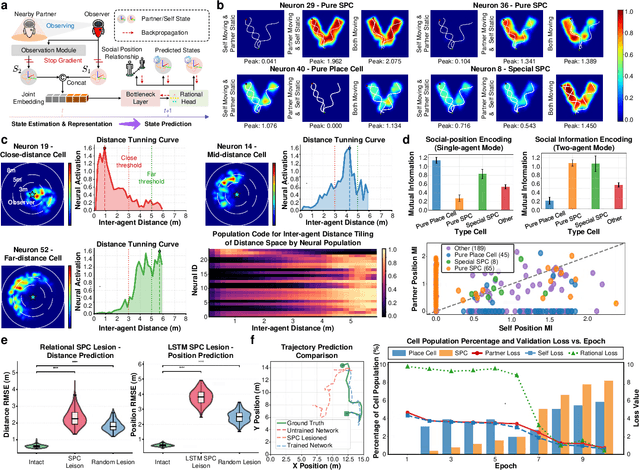
Sharing and reconstructing a consistent spatial memory is a critical challenge in multi-agent systems, where partial observability and limited bandwidth often lead to catastrophic failures in coordination. We introduce a multi-agent predictive coding framework that formulate coordination as the minimization of mutual uncertainty among agents. Instantiated as an information bottleneck objective, it prompts agents to learn not only who and what to communicate but also when. At the foundation of this framework lies a grid-cell-like metric as internal spatial coding for self-localization, emerging spontaneously from self-supervised motion prediction. Building upon this internal spatial code, agents gradually develop a bandwidth-efficient communication mechanism and specialized neural populations that encode partners' locations: an artificial analogue of hippocampal social place cells (SPCs). These social representations are further enacted by a hierarchical reinforcement learning policy that actively explores to reduce joint uncertainty. On the Memory-Maze benchmark, our approach shows exceptional resilience to bandwidth constraints: success degrades gracefully from 73.5% to 64.4% as bandwidth shrinks from 128 to 4 bits/step, whereas a full-broadcast baseline collapses from 67.6% to 28.6%. Our findings establish a theoretically principled and biologically plausible basis for how complex social representations emerge from a unified predictive drive, leading to social collective intelligence.
An Iterative LLM Framework for SIBT utilizing RAG-based Adaptive Weight Optimization
Sep 10, 2025



Seed implant brachytherapy (SIBT) is an effective cancer treatment modality; however, clinical planning often relies on manual adjustment of objective function weights, leading to inefficiencies and suboptimal results. This study proposes an adaptive weight optimization framework for SIBT planning, driven by large language models (LLMs). A locally deployed DeepSeek-R1 LLM is integrated with an automatic planning algorithm in an iterative loop. Starting with fixed weights, the LLM evaluates plan quality and recommends new weights in the next iteration. This process continues until convergence criteria are met, after which the LLM conducts a comprehensive evaluation to identify the optimal plan. A clinical knowledge base, constructed and queried via retrieval-augmented generation (RAG), enhances the model's domain-specific reasoning. The proposed method was validated on 23 patient cases, showing that the LLM-assisted approach produces plans that are comparable to or exceeding clinically approved and fixed-weight plans, in terms of dose homogeneity for the clinical target volume (CTV) and sparing of organs at risk (OARs). The study demonstrates the potential use of LLMs in SIBT planning automation.