 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisasterVQA: A Visual Question Answering Benchmark Dataset for Disaster Scenes
Jan 20, 2026Social media imagery provides a low-latency source of situational information during natural and human-induced disasters, enabling rapid damage assessment and response. While Visual Question Answering (VQA) has shown strong performance in general-purpose domains, its suitability for the complex and safety-critical reasoning required in disaster response remains unclear. We introduce DisasterVQA, a benchmark dataset designed for perception and reasoning in crisis contexts. DisasterVQA consists of 1,395 real-world images and 4,405 expert-curated question-answer pairs spanning diverse events such as floods, wildfires, and earthquakes. Grounded in humanitarian frameworks including FEMA ESF and OCHA MIRA, the dataset includes binary, multiple-choice, and open-ended questions covering situational awareness and operational decision-making tasks. We benchmark seven state-of-the-art vision-language models and find performance variability across question types, disaster categories, regions, and humanitarian tasks. Although models achieve high accuracy on binary questions, they struggle with fine-grained quantitative reasoning, object counting, and context-sensitive interpretation, particularly for underrepresented disaster scenarios. DisasterVQA provides a challenging and practical benchmark to guide the development of more robust and operationally meaningful vision-language models for disaster response. The dataset is publicly available at https://zenodo.org/records/18267770.
Accurate Table Question Answering with Accessible LLMs
Jan 06, 2026Given a table T in a database and a question Q in natural language, the table question answering (TQA) task aims to return an accurate answer to Q based on the content of T. Recent state-of-the-art solutions leverage large language models (LLMs) to obtain high-quality answers. However, most rely on proprietary, large-scale LLMs with costly API access, posing a significant financial barrier. This paper instead focuses on TQA with smaller, open-weight LLMs that can run on a desktop or laptop. This setting is challenging, as such LLMs typically have weaker capabilities than large proprietary models, leading to substantial performance degradation with existing methods. We observe that a key reason for this degradation is that prior approaches often require the LLM to solve a highly sophisticated task using long, complex prompts, which exceed the capabilities of small open-weight LLMs. Motivated by this observation, we present Orchestra, a multi-agent approach that unlocks the potential of accessible LLMs for high-quality, cost-effective TQA. Orchestra coordinates a group of LLM agents, each responsible for a relatively simple task, through a structured, layered workflow to solve complex TQA problems -- akin to an orchestra. By reducing the prompt complexity faced by each agent, Orchestra significantly improves output reliability. We implement Orchestra on top of AgentScope, an open-source multi-agent framework, and evaluate it on multiple TQA benchmarks using a wide range of open-weight LLMs. Experimental results show that Orchestra achieves strong performance even with small- to medium-sized models. For example, with Qwen2.5-14B, Orchestra reaches 72.1% accuracy on WikiTQ, approaching the best prior result of 75.3% achieved with GPT-4; with larger Qwen, Llama, or DeepSeek models, Orchestra outperforms all prior methods and establishes new state-of-the-art results across all benchmarks.
VoroLight: Learning Quality Volumetric Voronoi Meshes from General Inputs
Dec 15, 2025We present VoroLight, a differentiable framework for 3D shape reconstruction based on Voronoi meshing. Our approach generates smooth, watertight surfaces and topologically consistent volumetric meshes directly from diverse inputs, including images, implicit shape level-set fields, point clouds and meshes. VoroLight operates in three stages: it first initializes a surface using a differentiable Voronoi formulation, then refines surface quality through a polygon-face sphere training stage, and finally reuses the differentiable Voronoi formulation for volumetric optimization with additional interior generator points. Project page: https://jiayinlu19960224.github.io/vorolight/
Birth of a Painting: Differentiable Brushstroke Reconstruction
Nov 17, 2025Painting embodies a unique form of visual storytelling, where the creation process is as significant as the final artwork. Although recent advances in generative models have enabled visually compelling painting synthesis, most existing methods focus solely on final image generation or patch-based process simulation, lacking explicit stroke structure and failing to produce smooth, realistic shading. In this work, we present a differentiable stroke reconstruction framework that unifies painting, stylized texturing, and smudging to faithfully reproduce the human painting-smudging loop. Given an input image, our framework first optimizes single- and dual-color Bezier strokes through a parallel differentiable paint renderer, followed by a style generation module that synthesizes geometry-conditioned textures across diverse painting styles. We further introduce a differentiable smudge operator to enable natural color blending and shading. Coupled with a coarse-to-fine optimization strategy, our method jointly optimizes stroke geometry, color, and texture under geometric and semantic guidance. Extensive experiments on oil, watercolor, ink, and digital paintings demonstrate that our approach produces realistic and expressive stroke reconstructions, smooth tonal transitions, and richly stylized appearances, offering a unified model for expressive digital painting creation. See our project page for more demos: https://yingjiang96.github.io/DiffPaintWebsite/.
Right-Side-Out: Learning Zero-Shot Sim-to-Real Garment Reversal
Sep 19, 2025Turning garments right-side out is a challenging manipulation task: it is highly dynamic, entails rapid contact changes, and is subject to severe visual occlusion. We introduce Right-Side-Out, a zero-shot sim-to-real framework that effectively solves this challenge by exploiting task structures. We decompose the task into Drag/Fling to create and stabilize an access opening, followed by Insert&Pull to invert the garment. Each step uses a depth-inferred, keypoint-parameterized bimanual primitive that sharply reduces the action space while preserving robustness. Efficient data generation is enabled by our custom-built, high-fidelity, GPU-parallel Material Point Method (MPM) simulator that models thin-shell deformation and provides robust and efficient contact handling for batched rollouts. Built on the simulator, our fully automated pipeline scales data generation by randomizing garment geometry, material parameters, and viewpoints, producing depth, masks, and per-primitive keypoint labels without any human annotations. With a single depth camera, policies trained entirely in simulation deploy zero-shot on real hardware, achieving up to 81.3% success rate. By employing task decomposition and high fidelity simulation, our framework enables tackling highly dynamic, severely occluded tasks without laborious human demonstrations.
VME: A Satellite Imagery Dataset and Benchmark for Detecting Vehicles in the Middle East and Beyond
May 28, 2025Detecting vehicles in satellite images is crucial for traffic management, urban planning, and disaster response. However, current models struggle with real-world diversity, particularly across different regions. This challenge is amplified by geographic bias in existing datasets, which often focus on specific areas and overlook regions like the Middle East. To address this gap, we present the Vehicles in the Middle East (VME) dataset, designed explicitly for vehicle detection in high-resolution satellite images from Middle Eastern countries. Sourced from Maxar, the VME dataset spans 54 cities across 12 countries, comprising over 4,000 image tiles and more than 100,000 vehicles, annotated using both manual and semi-automated methods. Additionally, we introduce the largest benchmark dataset for Car Detection in Satellite Imagery (CDSI), combining images from multiple sources to enhance global car detection. Our experiments demonstrate that models trained on existing datasets perform poorly on Middle Eastern images, while the VME dataset significantly improves detection accuracy in this region. Moreover, state-of-the-art models trained on CDSI achieve substantial improvements in global car detection.
WonderPlay: Dynamic 3D Scene Generation from a Single Image and Actions
May 23, 2025WonderPlay is a novel framework integrating physics simulation with video generation for generating action-conditioned dynamic 3D scenes from a single image. While prior works are restricted to rigid body or simple elastic dynamics, WonderPlay features a hybrid generative simulator to synthesize a wide range of 3D dynamics. The hybrid generative simulator first uses a physics solver to simulate coarse 3D dynamics, which subsequently conditions a video generator to produce a video with finer, more realistic motion. The generated video is then used to update the simulated dynamic 3D scene, closing the loop between the physics solver and the video generator. This approach enables intuitive user control to be combined with the accurate dynamics of physics-based simulators and the expressivity of diffusion-based video generators. Experimental results demonstrate that WonderPlay enables users to interact with various scenes of diverse content, including cloth, sand, snow, liquid, smoke, elastic, and rigid bodies -- all using a single image input. Code will be made public. Project website: https://kyleleey.github.io/WonderPlay/
Integration Flow Models
Apr 28, 2025Ordinary differential equation (ODE) based generative models have emerged as a powerful approach for producing high-quality samples in many applications. However, the ODE-based methods either suffer the discretization error of numerical solvers of ODE, which restricts the quality of samples when only a few NFEs are used, or struggle with training instability. In this paper, we proposed Integration Flow, which directly learns the integral of ODE-based trajectory paths without solving the ODE functions. Moreover, Integration Flow explicitly incorporates the target state $\mathbf{x}_0$ as the anchor state in guiding the reverse-time dynamics. We have theoretically proven this can contribute to both stability and accuracy. To the best of our knowledge, Integration Flow is the first model with a unified structure to estimate ODE-based generative models and the first to show the exact straightness of 1-Rectified Flow without reflow. Through theoretical analysis and empirical evaluations, we show that Integration Flows achieve improved performance when it is applied to existing ODE-based models, such as diffusion models, Rectified Flows, and PFGM++. Specifically, Integration Flow achieves one-step generation on CIFAR10 with FIDs of 2.86 for the Variance Exploding (VE) diffusion model, 3.36 for rectified flow without reflow, and 2.91 for PFGM++; and on ImageNet with FIDs of 4.09 for VE diffusion model, 4.35 for rectified flow without reflow and 4.15 for PFGM++.
Real-time High-fidelity Gaussian Human Avatars with Position-based Interpolation of Spatially Distributed MLPs
Apr 17, 2025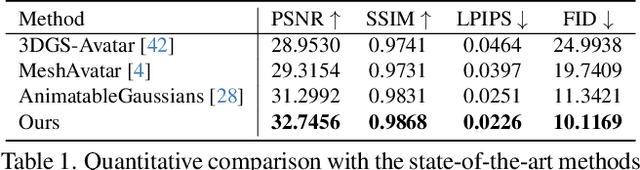


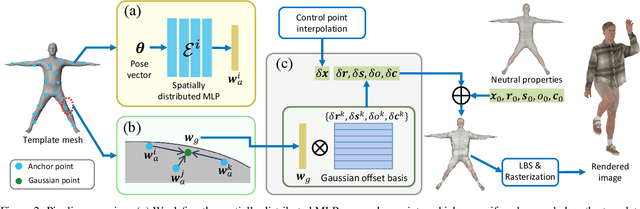
Many works have succeeded in reconstructing Gaussian human avatars from multi-view videos. However, they either struggle to capture pose-dependent appearance details with a single MLP, or rely on a computationally intensive neural network to reconstruct high-fidelity appearance but with rendering performance degraded to non-real-time. We propose a novel Gaussian human avatar representation that can reconstruct high-fidelity pose-dependence appearance with details and meanwhile can be rendered in real time. Our Gaussian avatar is empowered by spatially distributed MLPs which are explicitly located on different positions on human body. The parameters stored in each Gaussian are obtained by interpolating from the outputs of its nearby MLPs based on their distances. To avoid undesired smooth Gaussian property changing during interpolation, for each Gaussian we define a set of Gaussian offset basis, and a linear combination of basis represents the Gaussian property offsets relative to the neutral properties. Then we propose to let the MLPs output a set of coefficients corresponding to the basis. In this way, although Gaussian coefficients are derived from interpolation and change smoothly, the Gaussian offset basis is learned freely without constraints. The smoothly varying coefficients combined with freely learned basis can still produce distinctly different Gaussian property offsets, allowing the ability to learn high-frequency spatial signals. We further use control points to constrain the Gaussians distributed on a surface layer rather than allowing them to be irregularly distributed inside the body, to help the human avatar generalize better when animated under novel poses. Compared to the state-of-the-art method, our method achieves better appearance quality with finer details while the rendering speed is significantly faster under novel views and novel poses.
High-fidelity 3D Object Generation from Single Image with RGBN-Volume Gaussian Reconstruction Model
Apr 02, 2025Recently single-view 3D generation via Gaussian splatting has emerged and developed quickly. They learn 3D Gaussians from 2D RGB images generated from pre-trained multi-view diffusion (MVD) models, and have shown a promising avenue for 3D generation through a single image. Despite the current progress, these methods still suffer from the inconsistency jointly caused by the geometric ambiguity in the 2D images, and the lack of structure of 3D Gaussians, leading to distorted and blurry 3D object generation. In this paper, we propose to fix these issues by GS-RGBN, a new RGBN-volume Gaussian Reconstruction Model designed to generate high-fidelity 3D objects from single-view images. Our key insight is a structured 3D representation can simultaneously mitigate the afore-mentioned two issues. To this end, we propose a novel hybrid Voxel-Gaussian representation, where a 3D voxel representation contains explicit 3D geometric information, eliminating the geometric ambiguity from 2D images. It also structures Gaussians during learning so that the optimization tends to find better local optima. Our 3D voxel representation is obtained by a fusion module that aligns RGB features and surface normal features, both of which can be estimated from 2D images. Extensive experiments demonstrate the superiority of our methods over prior works in terms of high-quality reconstruction results, robust generalization, and good efficiency.