 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Mobile Avatars with Pruned Local Blendshapes
May 03, 2026We propose a method to reconstruct high-fidelity human avatars from multi-view video that can run on mobile devices. Many works can model high-quality Gaussian-based full-body avatars from multi-view video. However, these methods require heavy computation to obtain pose-dependent appearance, making deployment on mobile devices very difficult. Recent methods distill from pretrained models and model pose-dependent nonlinear Gaussian attributes by linearly combining global pose features with blendshapes. Although they can run on mobile devices, they suffer some loss of detail. We observe that nearby Gaussians are often highly correlated within a local region of the body, and can be linearly modeled with less error. Therefore, we use local linear blendshapes in small body parts to capture global nonlinear changes of Gaussian attributes. To further reduce computation and model size, we propose to remove blendshapes for Gaussians whose attributes change little, yielding a minimal blendshape representation. Our method is an end-to-end training method without a pretrained model. To make it run on multiple devices, we implement our method using WebGPU. Experiments show that our method can render high-quality human avatars with better details, and can reach 120 FPS at 2K resolution on mobile devices.
Real-time High-fidelity Gaussian Human Avatars with Position-based Interpolation of Spatially Distributed MLPs
Apr 17, 2025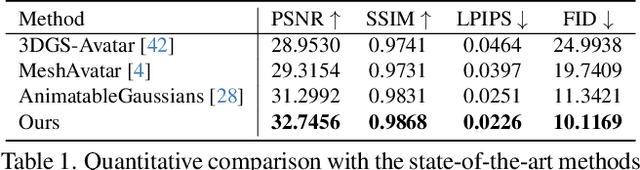


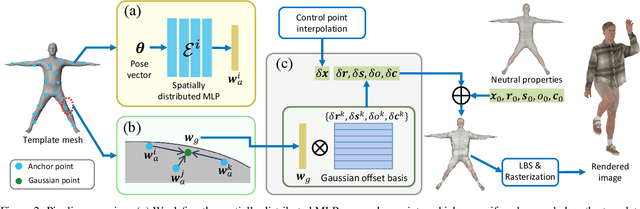
Many works have succeeded in reconstructing Gaussian human avatars from multi-view videos. However, they either struggle to capture pose-dependent appearance details with a single MLP, or rely on a computationally intensive neural network to reconstruct high-fidelity appearance but with rendering performance degraded to non-real-time. We propose a novel Gaussian human avatar representation that can reconstruct high-fidelity pose-dependence appearance with details and meanwhile can be rendered in real time. Our Gaussian avatar is empowered by spatially distributed MLPs which are explicitly located on different positions on human body. The parameters stored in each Gaussian are obtained by interpolating from the outputs of its nearby MLPs based on their distances. To avoid undesired smooth Gaussian property changing during interpolation, for each Gaussian we define a set of Gaussian offset basis, and a linear combination of basis represents the Gaussian property offsets relative to the neutral properties. Then we propose to let the MLPs output a set of coefficients corresponding to the basis. In this way, although Gaussian coefficients are derived from interpolation and change smoothly, the Gaussian offset basis is learned freely without constraints. The smoothly varying coefficients combined with freely learned basis can still produce distinctly different Gaussian property offsets, allowing the ability to learn high-frequency spatial signals. We further use control points to constrain the Gaussians distributed on a surface layer rather than allowing them to be irregularly distributed inside the body, to help the human avatar generalize better when animated under novel poses. Compared to the state-of-the-art method, our method achieves better appearance quality with finer details while the rendering speed is significantly faster under novel views and novel poses.
Interactive Rendering of Relightable and Animatable Gaussian Avatars
Jul 15, 2024



Creating relightable and animatable avatars from multi-view or monocular videos is a challenging task for digital human creation and virtual reality applications. Previous methods rely on neural radiance fields or ray tracing, resulting in slow training and rendering processes. By utilizing Gaussian Splatting, we propose a simple and efficient method to decouple body materials and lighting from sparse-view or monocular avatar videos, so that the avatar can be rendered simultaneously under novel viewpoints, poses, and lightings at interactive frame rates (6.9 fps). Specifically, we first obtain the canonical body mesh using a signed distance function and assign attributes to each mesh vertex. The Gaussians in the canonical space then interpolate from nearby body mesh vertices to obtain the attributes. We subsequently deform the Gaussians to the posed space using forward skinning, and combine the learnable environment light with the Gaussian attributes for shading computation. To achieve fast shadow modeling, we rasterize the posed body mesh from dense viewpoints to obtain the visibility. Our approach is not only simple but also fast enough to allow interactive rendering of avatar animation under environmental light changes. Experiments demonstrate that, compared to previous works, our method can render higher quality results at a faster speed on both synthetic and real datasets.
Pattern Guided UV Recovery for Realistic Video Garment Texturing
Jul 14, 2024



The fast growth of E-Commerce creates a global market worth USD 821 billion for online fashion shopping. What unique about fashion presentation is that, the same design can usually be offered with different cloths textures. However, only real video capturing or manual per-frame editing can be used for virtual showcase on the same design with different textures, both of which are heavily labor intensive. In this paper, we present a pattern-based approach for UV and shading recovery from a captured real video so that the garment's texture can be replaced automatically. The core of our approach is a per-pixel UV regression module via blended-weight multilayer perceptrons (MLPs) driven by the detected discrete correspondences from the cloth pattern. We propose a novel loss on the Jacobian of the UV mapping to create pleasant seams around the folding areas and the boundary of occluded regions while avoiding UV distortion. We also adopts the temporal constraint to ensure consistency and accuracy in UV prediction across adjacent frames. We show that our approach is robust to a variety type of clothes, in the wild illuminations and with challenging motions. We show plausible texture replacement results in our experiment, in which the folding and overlapping of the garment can be greatly preserved. We also show clear qualitative and quantitative improvement compared to the baselines as well. With the one-click setup, we look forward to our approach contributing to the growth of fashion E-commerce.