 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors
Jun 03, 2026Scaling humanoid loco-manipulation requires robot-compatible demonstrations across diverse objects, whole-body motions, and scene geometries, but teleoperation and motion capture are difficult to scale because each collection depends on physical setups, instrumented actors, and robot operation. We present GRAIL, a digital generation pipeline that remains fully virtual until deployment: it composes 3D assets, simulator-ready scenes, and priors from video foundation models (VFMs) to synthesize interactions without rebuilding physical environments or teleoperating the robot. Rather than reconstructing unconstrained in-the-wild videos, GRAIL starts from fully specified 3D configurations in which object geometry, camera parameters, metric scale, environment depth, and a robot-proportioned character are known before video generation and reused during reconstruction. This privileged setup better conditions 4D recovery, allowing model-based object tracking, human motion estimation, and interaction-aware optimization to reconstruct metric 4D human-object interaction (HOI) trajectories with reduced depth ambiguity and morphology mismatch. We retarget the recovered motions to a humanoid robot and train complementary task-general trackers: an object-aware latent adaptor for manipulation and a scene-aware tracker for terrain traversal. GRAIL produces over 20,000 sequences spanning pick-up, object manipulation, sitting, and terrain traversal. Using only GRAIL-generated data, we train egocentric visual policies through a sim-to-real pipeline and deploy them on a Unitree G1 humanoid, achieving 84\% real-world success on diverse object pick-up and 90\% success on stair-climbing.
DressWild: Feed-Forward Pose-Agnostic Garment Sewing Pattern Generation from In-the-Wild Images
Feb 18, 2026Recent advances in garment pattern generation have shown promising progress. However, existing feed-forward methods struggle with diverse poses and viewpoints, while optimization-based approaches are computationally expensive and difficult to scale. This paper focuses on sewing pattern generation for garment modeling and fabrication applications that demand editable, separable, and simulation-ready garments. We propose DressWild, a novel feed-forward pipeline that reconstructs physics-consistent 2D sewing patterns and the corresponding 3D garments from a single in-the-wild image. Given an input image, our method leverages vision-language models (VLMs) to normalize pose variations at the image level, then extract pose-aware, 3D-informed garment features. These features are fused through a transformer-based encoder and subsequently used to predict sewing pattern parameters, which can be directly applied to physical simulation, texture synthesis, and multi-layer virtual try-on. Extensive experiments demonstrate that our approach robustly recovers diverse sewing patterns and the corresponding 3D garments from in-the-wild images without requiring multi-view inputs or iterative optimization, offering an efficient and scalable solution for realistic garment simulation and animation.
GRIP: A General Robotic Incremental Potential Contact Simulation Dataset for Unified Deformable-Rigid Coupled Grasping
Mar 06, 2025Grasping is fundamental to robotic manipulation, and recent advances in large-scale grasping datasets have provided essential training data and evaluation benchmarks, accelerating the development of learning-based methods for robust object grasping. However, most existing datasets exclude deformable bodies due to the lack of scalable, robust simulation pipelines, limiting the development of generalizable models for compliant grippers and soft manipulands. To address these challenges, we present GRIP, a General Robotic Incremental Potential contact simulation dataset for universal grasping. GRIP leverages an optimized Incremental Potential Contact (IPC)-based simulator for multi-environment data generation, achieving up to 48x speedup while ensuring efficient, intersection- and inversion-free simulations for compliant grippers and deformable objects. Our fully automated pipeline generates and evaluates diverse grasp interactions across 1,200 objects and 100,000 grasp poses, incorporating both soft and rigid grippers. The GRIP dataset enables applications such as neural grasp generation and stress field prediction.
Dress-1-to-3: Single Image to Simulation-Ready 3D Outfit with Diffusion Prior and Differentiable Physics
Feb 05, 2025



Recent advances in large models have significantly advanced image-to-3D reconstruction. However, the generated models are often fused into a single piece, limiting their applicability in downstream tasks. This paper focuses on 3D garment generation, a key area for applications like virtual try-on with dynamic garment animations, which require garments to be separable and simulation-ready. We introduce Dress-1-to-3, a novel pipeline that reconstructs physics-plausible, simulation-ready separated garments with sewing patterns and humans from an in-the-wild image. Starting with the image, our approach combines a pre-trained image-to-sewing pattern generation model for creating coarse sewing patterns with a pre-trained multi-view diffusion model to produce multi-view images. The sewing pattern is further refined using a differentiable garment simulator based on the generated multi-view images. Versatile experiments demonstrate that our optimization approach substantially enhances the geometric alignment of the reconstructed 3D garments and humans with the input image. Furthermore, by integrating a texture generation module and a human motion generation module, we produce customized physics-plausible and realistic dynamic garment demonstrations. Project page: https://dress-1-to-3.github.io/
PhysAnimator: Physics-Guided Generative Cartoon Animation
Jan 27, 2025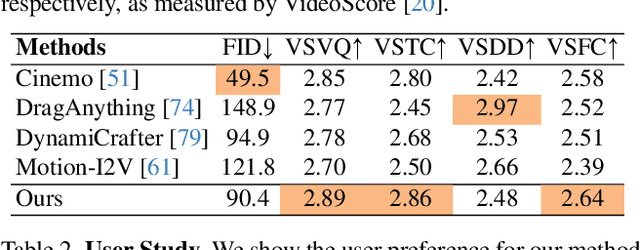
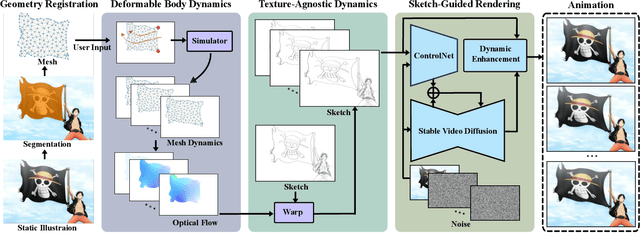

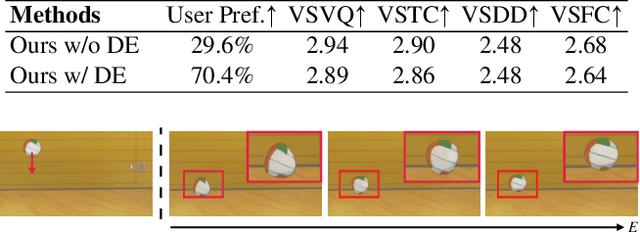
Creating hand-drawn animation sequences is labor-intensive and demands professional expertise. We introduce PhysAnimator, a novel approach for generating physically plausible meanwhile anime-stylized animation from static anime illustrations. Our method seamlessly integrates physics-based simulations with data-driven generative models to produce dynamic and visually compelling animations. To capture the fluidity and exaggeration characteristic of anime, we perform image-space deformable body simulations on extracted mesh geometries. We enhance artistic control by introducing customizable energy strokes and incorporating rigging point support, enabling the creation of tailored animation effects such as wind interactions. Finally, we extract and warp sketches from the simulation sequence, generating a texture-agnostic representation, and employ a sketch-guided video diffusion model to synthesize high-quality animation frames. The resulting animations exhibit temporal consistency and visual plausibility, demonstrating the effectiveness of our method in creating dynamic anime-style animations.
PhysMotion: Physics-Grounded Dynamics From a Single Image
Nov 26, 2024We introduce PhysMotion, a novel framework that leverages principled physics-based simulations to guide intermediate 3D representations generated from a single image and input conditions (e.g., applied force and torque), producing high-quality, physically plausible video generation. By utilizing continuum mechanics-based simulations as a prior knowledge, our approach addresses the limitations of traditional data-driven generative models and result in more consistent physically plausible motions. Our framework begins by reconstructing a feed-forward 3D Gaussian from a single image through geometry optimization. This representation is then time-stepped using a differentiable Material Point Method (MPM) with continuum mechanics-based elastoplasticity models, which provides a strong foundation for realistic dynamics, albeit at a coarse level of detail. To enhance the geometry, appearance and ensure spatiotemporal consistency, we refine the initial simulation using a text-to-image (T2I) diffusion model with cross-frame attention, resulting in a physically plausible video that retains intricate details comparable to the input image. We conduct comprehensive qualitative and quantitative evaluations to validate the efficacy of our method. Our project page is available at: \url{https://supertan0204.github.io/physmotion_website/}.
VideoPhy: Evaluating Physical Commonsense for Video Generation
Jun 05, 2024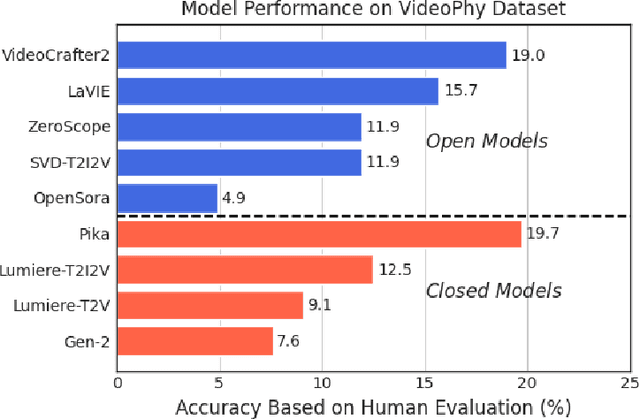


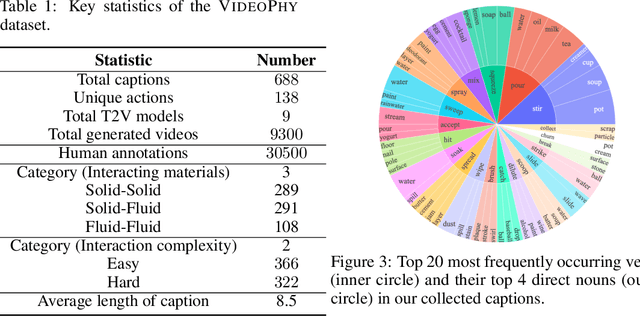
Recent advances in internet-scale video data pretraining have led to the development of text-to-video generative models that can create high-quality videos across a broad range of visual concepts and styles. Due to their ability to synthesize realistic motions and render complex objects, these generative models have the potential to become general-purpose simulators of the physical world. However, it is unclear how far we are from this goal with the existing text-to-video generative models. To this end, we present VideoPhy, a benchmark designed to assess whether the generated videos follow physical commonsense for real-world activities (e.g. marbles will roll down when placed on a slanted surface). Specifically, we curate a list of 688 captions that involve interactions between various material types in the physical world (e.g., solid-solid, solid-fluid, fluid-fluid). We then generate videos conditioned on these captions from diverse state-of-the-art text-to-video generative models, including open models (e.g., VideoCrafter2) and closed models (e.g., Lumiere from Google, Pika). Further, our human evaluation reveals that the existing models severely lack the ability to generate videos adhering to the given text prompts, while also lack physical commonsense. Specifically, the best performing model, Pika, generates videos that adhere to the caption and physical laws for only 19.7% of the instances. VideoPhy thus highlights that the video generative models are far from accurately simulating the physical world. Finally, we also supplement the dataset with an auto-evaluator, VideoCon-Physics, to assess semantic adherence and physical commonsense at scale.
Atlas3D: Physically Constrained Self-Supporting Text-to-3D for Simulation and Fabrication
May 28, 2024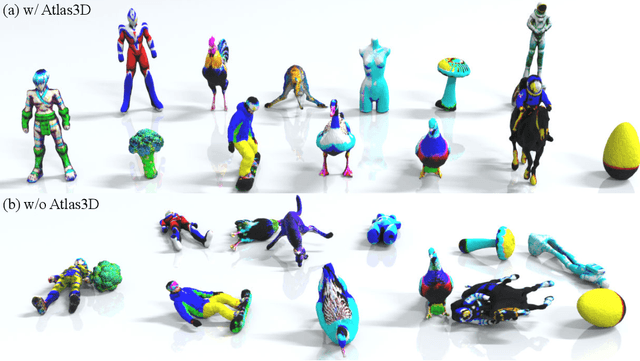

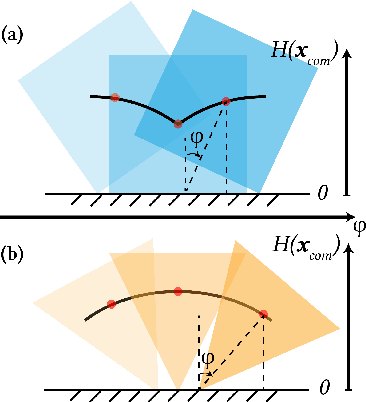

Existing diffusion-based text-to-3D generation methods primarily focus on producing visually realistic shapes and appearances, often neglecting the physical constraints necessary for downstream tasks. Generated models frequently fail to maintain balance when placed in physics-based simulations or 3D printed. This balance is crucial for satisfying user design intentions in interactive gaming, embodied AI, and robotics, where stable models are needed for reliable interaction. Additionally, stable models ensure that 3D-printed objects, such as figurines for home decoration, can stand on their own without requiring additional supports. To fill this gap, we introduce Atlas3D, an automatic and easy-to-implement method that enhances existing Score Distillation Sampling (SDS)-based text-to-3D tools. Atlas3D ensures the generation of self-supporting 3D models that adhere to physical laws of stability under gravity, contact, and friction. Our approach combines a novel differentiable simulation-based loss function with physically inspired regularization, serving as either a refinement or a post-processing module for existing frameworks. We verify Atlas3D's efficacy through extensive generation tasks and validate the resulting 3D models in both simulated and real-world environments.
Sunnie: An Anthropomorphic LLM-Based Conversational Agent for Mental Well-Being Activity Recommendation
May 22, 2024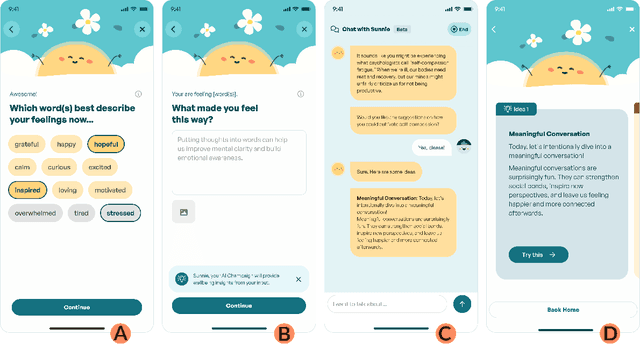

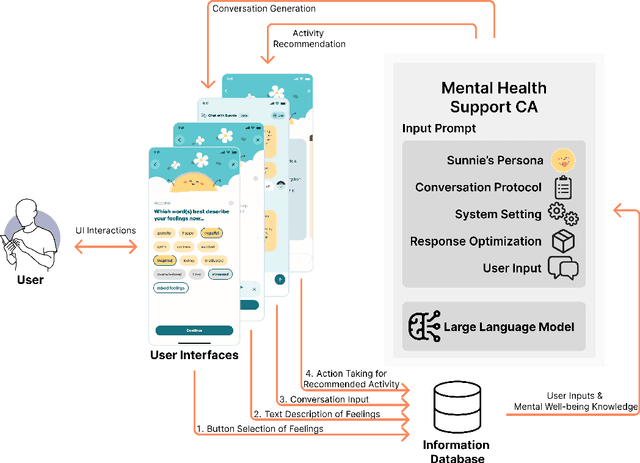
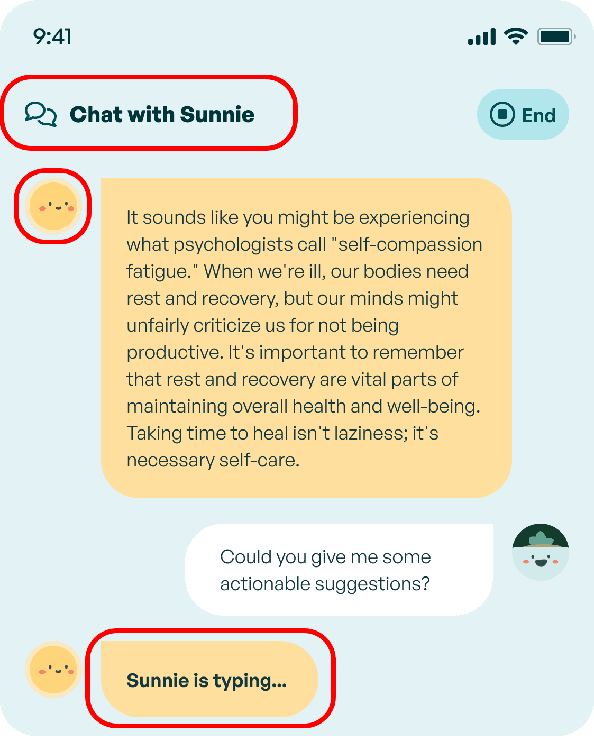
A longstanding challenge in mental well-being support is the reluctance of people to adopt psychologically beneficial activities, often due to a lack of motivation, low perceived trustworthiness, and limited personalization of recommendations. Chatbots have shown promise in promoting positive mental health practices, yet their rigid interaction flows and less human-like conversational experiences present significant limitations. In this work, we explore whether the anthropomorphic design (both LLM's persona design and conversational experience design) can enhance users' perception of the system and their willingness to adopt mental well-being activity recommendations. To this end, we introduce Sunnie, an anthropomorphic LLM-based conversational agent designed to offer personalized guidance for mental well-being support through multi-turn conversation and activity recommendations based on positive psychological theory. An empirical user study comparing the user experience with Sunnie and with a traditional survey-based activity recommendation system suggests that the anthropomorphic characteristics of Sunnie significantly enhance users' perception of the system and the overall usability; nevertheless, users' willingness to adopt activity recommendations did not change significantly.
GarmentDreamer: 3DGS Guided Garment Synthesis with Diverse Geometry and Texture Details
May 20, 2024



Traditional 3D garment creation is labor-intensive, involving sketching, modeling, UV mapping, and texturing, which are time-consuming and costly. Recent advances in diffusion-based generative models have enabled new possibilities for 3D garment generation from text prompts, images, and videos. However, existing methods either suffer from inconsistencies among multi-view images or require additional processes to separate cloth from the underlying human model. In this paper, we propose GarmentDreamer, a novel method that leverages 3D Gaussian Splatting (GS) as guidance to generate wearable, simulation-ready 3D garment meshes from text prompts. In contrast to using multi-view images directly predicted by generative models as guidance, our 3DGS guidance ensures consistent optimization in both garment deformation and texture synthesis. Our method introduces a novel garment augmentation module, guided by normal and RGBA information, and employs implicit Neural Texture Fields (NeTF) combined with Score Distillation Sampling (SDS) to generate diverse geometric and texture details. We validate the effectiveness of our approach through comprehensive qualitative and quantitative experiments, showcasing the superior performance of GarmentDreamer over state-of-the-art alternatives. Our project page is available at: https://xuan-li.github.io/GarmentDreamerDemo/.