 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegRap2025: A Benchmark of Gross Tumor Volume and Lymph Node Clinical Target Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Jan 28, 2026Accurate delineation of Gross Tumor Volume (GTV), Lymph Node Clinical Target Volume (LN CTV), and Organ-at-Risk (OAR) from Computed Tomography (CT) scans is essential for precise radiotherapy planning in Nasopharyngeal Carcinoma (NPC). Building upon SegRap2023, which focused on OAR and GTV segmentation using single-center paired non-contrast CT (ncCT) and contrast-enhanced CT (ceCT) scans, the SegRap2025 challenge aims to enhance the generalizability and robustness of segmentation models across imaging centers and modalities. SegRap2025 comprises two tasks: Task01 addresses GTV segmentation using paired CT from the SegRap2023 dataset, with an additional external testing set to evaluate cross-center generalization, and Task02 focuses on LN CTV segmentation using multi-center training data and an unseen external testing set, where each case contains paired CT scans or a single modality, emphasizing both cross-center and cross-modality robustness. This paper presents the challenge setup and provides a comprehensive analysis of the solutions submitted by ten participating teams. For GTV segmentation task, the top-performing models achieved average Dice Similarity Coefficient (DSC) of 74.61% and 56.79% on the internal and external testing cohorts, respectively. For LN CTV segmentation task, the highest average DSC values reached 60.24%, 60.50%, and 57.23% on paired CT, ceCT-only, and ncCT-only subsets, respectively. SegRap2025 establishes a large-scale multi-center, multi-modality benchmark for evaluating the generalization and robustness in radiotherapy target segmentation, providing valuable insights toward clinically applicable automated radiotherapy planning systems. The benchmark is available at: https://hilab-git.github.io/SegRap2025_Challenge.
Real Garment Benchmark (RGBench): A Comprehensive Benchmark for Robotic Garment Manipulation featuring a High-Fidelity Scalable Simulator
Nov 12, 2025While there has been significant progress to use simulated data to learn robotic manipulation of rigid objects, applying its success to deformable objects has been hindered by the lack of both deformable object models and realistic non-rigid body simulators. In this paper, we present Real Garment Benchmark (RGBench), a comprehensive benchmark for robotic manipulation of garments. It features a diverse set of over 6000 garment mesh models, a new high-performance simulator, and a comprehensive protocol to evaluate garment simulation quality with carefully measured real garment dynamics. Our experiments demonstrate that our simulator outperforms currently available cloth simulators by a large margin, reducing simulation error by 20% while maintaining a speed of 3 times faster. We will publicly release RGBench to accelerate future research in robotic garment manipulation. Website: https://rgbench.github.io/
SpikeSMOKE: Spiking Neural Networks for Monocular 3D Object Detection with Cross-Scale Gated Coding
Jun 09, 2025Low energy consumption for 3D object detection is an important research area because of the increasing energy consumption with their wide application in fields such as autonomous driving. The spiking neural networks (SNNs) with low-power consumption characteristics can provide a novel solution for this research. Therefore, we apply SNNs to monocular 3D object detection and propose the SpikeSMOKE architecture in this paper, which is a new attempt for low-power monocular 3D object detection. As we all know, discrete signals of SNNs will generate information loss and limit their feature expression ability compared with the artificial neural networks (ANNs).In order to address this issue, inspired by the filtering mechanism of biological neuronal synapses, we propose a cross-scale gated coding mechanism(CSGC), which can enhance feature representation by combining cross-scale fusion of attentional methods and gated filtering mechanisms.In addition, to reduce the computation and increase the speed of training, we present a novel light-weight residual block that can maintain spiking computing paradigm and the highest possible detection performance. Compared to the baseline SpikeSMOKE under the 3D Object Detection, the proposed SpikeSMOKE with CSGC can achieve 11.78 (+2.82, Easy), 10.69 (+3.2, Moderate), and 10.48 (+3.17, Hard) on the KITTI autonomous driving dataset by AP|R11 at 0.7 IoU threshold, respectively. It is important to note that the results of SpikeSMOKE can significantly reduce energy consumption compared to the results on SMOKE. For example,the energy consumption can be reduced by 72.2% on the hard category, while the detection performance is reduced by only 4%. SpikeSMOKE-L (lightweight) can further reduce the amount of parameters by 3 times and computation by 10 times compared to SMOKE.
GarmageNet: A Dataset and Scalable Representation for Generic Garment Modeling
Apr 02, 2025

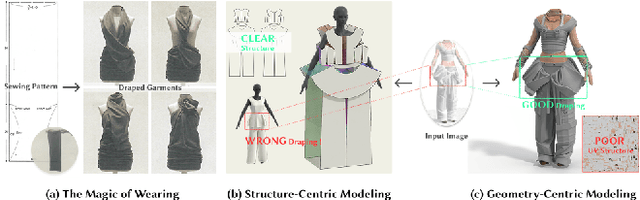
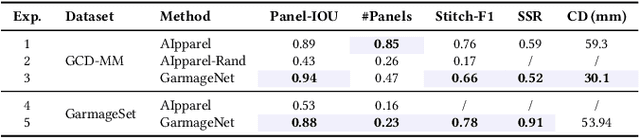
High-fidelity garment modeling remains challenging due to the lack of large-scale, high-quality datasets and efficient representations capable of handling non-watertight, multi-layer geometries. In this work, we introduce Garmage, a neural-network-and-CG-friendly garment representation that seamlessly encodes the accurate geometry and sewing pattern of complex multi-layered garments as a structured set of per-panel geometry images. As a dual-2D-3D representation, Garmage achieves an unprecedented integration of 2D image-based algorithms with 3D modeling workflows, enabling high fidelity, non-watertight, multi-layered garment geometries with direct compatibility for industrial-grade simulations.Built upon this representation, we present GarmageNet, a novel generation framework capable of producing detailed multi-layered garments with body-conforming initial geometries and intricate sewing patterns, based on user prompts or existing in-the-wild sewing patterns. Furthermore, we introduce a robust stitching algorithm that recovers per-vertex stitches, ensuring seamless integration into flexible simulation pipelines for downstream editing of sewing patterns, material properties, and dynamic simulations. Finally, we release an industrial-standard, large-scale, high-fidelity garment dataset featuring detailed annotations, vertex-wise correspondences, and a robust pipeline for converting unstructured production sewing patterns into GarmageNet standard structural assets, paving the way for large-scale, industrial-grade garment generation systems.
Temporal Information Reconstruction and Non-Aligned Residual in Spiking Neural Networks for Speech Classification
Dec 31, 2024
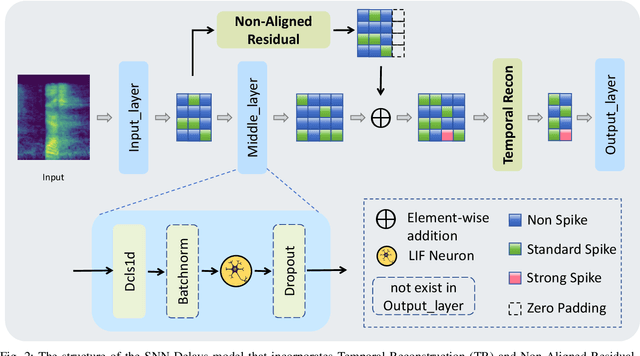
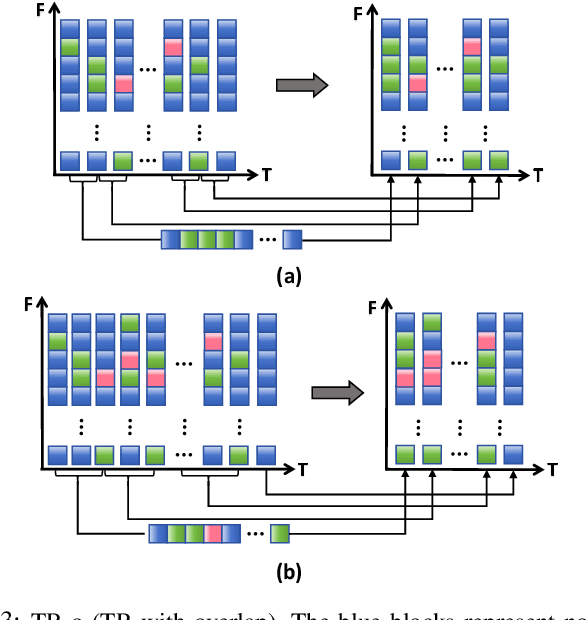
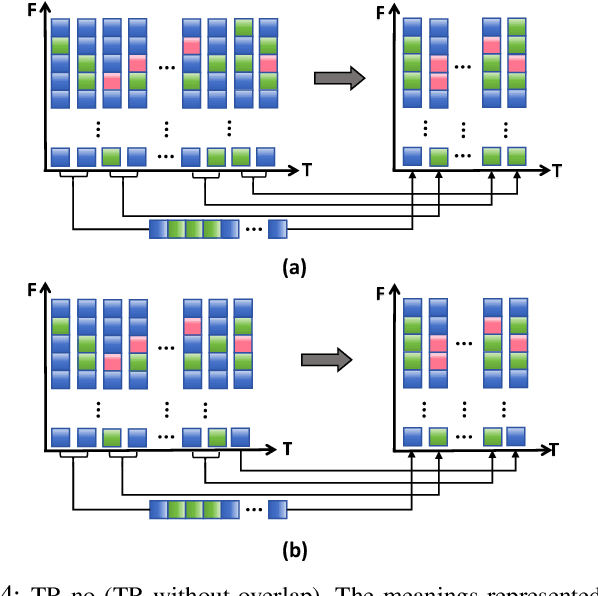
Recently, it can be noticed that most models based on spiking neural networks (SNNs) only use a same level temporal resolution to deal with speech classification problems, which makes these models cannot learn the information of input data at different temporal scales. Additionally, owing to the different time lengths of the data before and after the sub-modules of many models, the effective residual connections cannot be applied to optimize the training processes of these models.To solve these problems, on the one hand, we reconstruct the temporal dimension of the audio spectrum to propose a novel method named as Temporal Reconstruction (TR) by referring the hierarchical processing process of the human brain for understanding speech. Then, the reconstructed SNN model with TR can learn the information of input data at different temporal scales and model more comprehensive semantic information from audio data because it enables the networks to learn the information of input data at different temporal resolutions. On the other hand, we propose the Non-Aligned Residual (NAR) method by analyzing the audio data, which allows the residual connection can be used in two audio data with different time lengths. We have conducted plentiful experiments on the Spiking Speech Commands (SSC), the Spiking Heidelberg Digits (SHD), and the Google Speech Commands v0.02 (GSC) datasets. According to the experiment results, we have achieved the state-of-the-art (SOTA) result 81.02\% on SSC for the test classification accuracy of all SNN models, and we have obtained the SOTA result 96.04\% on SHD for the classification accuracy of all models.
Design2GarmentCode: Turning Design Concepts to Tangible Garments Through Program Synthesis
Dec 12, 2024



Sewing patterns, the essential blueprints for fabric cutting and tailoring, act as a crucial bridge between design concepts and producible garments. However, existing uni-modal sewing pattern generation models struggle to effectively encode complex design concepts with a multi-modal nature and correlate them with vectorized sewing patterns that possess precise geometric structures and intricate sewing relations. In this work, we propose a novel sewing pattern generation approach Design2GarmentCode based on Large Multimodal Models (LMMs), to generate parametric pattern-making programs from multi-modal design concepts. LMM offers an intuitive interface for interpreting diverse design inputs, while pattern-making programs could serve as well-structured and semantically meaningful representations of sewing patterns, and act as a robust bridge connecting the cross-domain pattern-making knowledge embedded in LMMs with vectorized sewing patterns. Experimental results demonstrate that our method can flexibly handle various complex design expressions such as images, textual descriptions, designer sketches, or their combinations, and convert them into size-precise sewing patterns with correct stitches. Compared to previous methods, our approach significantly enhances training efficiency, generation quality, and authoring flexibility. Our code and data will be publicly available.
FashionR2R: Texture-preserving Rendered-to-Real Image Translation with Diffusion Models
Oct 18, 2024



Modeling and producing lifelike clothed human images has attracted researchers' attention from different areas for decades, with the complexity from highly articulated and structured content. Rendering algorithms decompose and simulate the imaging process of a camera, while are limited by the accuracy of modeled variables and the efficiency of computation. Generative models can produce impressively vivid human images, however still lacking in controllability and editability. This paper studies photorealism enhancement of rendered images, leveraging generative power from diffusion models on the controlled basis of rendering. We introduce a novel framework to translate rendered images into their realistic counterparts, which consists of two stages: Domain Knowledge Injection (DKI) and Realistic Image Generation (RIG). In DKI, we adopt positive (real) domain finetuning and negative (rendered) domain embedding to inject knowledge into a pretrained Text-to-image (T2I) diffusion model. In RIG, we generate the realistic image corresponding to the input rendered image, with a Texture-preserving Attention Control (TAC) to preserve fine-grained clothing textures, exploiting the decoupled features encoded in the UNet structure. Additionally, we introduce SynFashion dataset, featuring high-quality digital clothing images with diverse textures. Extensive experimental results demonstrate the superiority and effectiveness of our method in rendered-to-real image translation.
NeuroMoCo: A Neuromorphic Momentum Contrast Learning Method for Spiking Neural Networks
Jun 10, 2024



Recently, brain-inspired spiking neural networks (SNNs) have attracted great research attention owing to their inherent bio-interpretability, event-triggered properties and powerful perception of spatiotemporal information, which is beneficial to handling event-based neuromorphic datasets. In contrast to conventional static image datasets, event-based neuromorphic datasets present heightened complexity in feature extraction due to their distinctive time series and sparsity characteristics, which influences their classification accuracy. To overcome this challenge, a novel approach termed Neuromorphic Momentum Contrast Learning (NeuroMoCo) for SNNs is introduced in this paper by extending the benefits of self-supervised pre-training to SNNs to effectively stimulate their potential. This is the first time that self-supervised learning (SSL) based on momentum contrastive learning is realized in SNNs. In addition, we devise a novel loss function named MixInfoNCE tailored to their temporal characteristics to further increase the classification accuracy of neuromorphic datasets, which is verified through rigorous ablation experiments. Finally, experiments on DVS-CIFAR10, DVS128Gesture and N-Caltech101 have shown that NeuroMoCo of this paper establishes new state-of-the-art (SOTA) benchmarks: 83.6% (Spikformer-2-256), 98.62% (Spikformer-2-256), and 84.4% (SEW-ResNet-18), respectively.
GarmentDreamer: 3DGS Guided Garment Synthesis with Diverse Geometry and Texture Details
May 20, 2024



Traditional 3D garment creation is labor-intensive, involving sketching, modeling, UV mapping, and texturing, which are time-consuming and costly. Recent advances in diffusion-based generative models have enabled new possibilities for 3D garment generation from text prompts, images, and videos. However, existing methods either suffer from inconsistencies among multi-view images or require additional processes to separate cloth from the underlying human model. In this paper, we propose GarmentDreamer, a novel method that leverages 3D Gaussian Splatting (GS) as guidance to generate wearable, simulation-ready 3D garment meshes from text prompts. In contrast to using multi-view images directly predicted by generative models as guidance, our 3DGS guidance ensures consistent optimization in both garment deformation and texture synthesis. Our method introduces a novel garment augmentation module, guided by normal and RGBA information, and employs implicit Neural Texture Fields (NeTF) combined with Score Distillation Sampling (SDS) to generate diverse geometric and texture details. We validate the effectiveness of our approach through comprehensive qualitative and quantitative experiments, showcasing the superior performance of GarmentDreamer over state-of-the-art alternatives. Our project page is available at: https://xuan-li.github.io/GarmentDreamerDemo/.
High-quality Surface Reconstruction using Gaussian Surfels
Apr 30, 2024We propose a novel point-based representation, Gaussian surfels, to combine the advantages of the flexible optimization procedure in 3D Gaussian points and the surface alignment property of surfels. This is achieved by directly setting the z-scale of 3D Gaussian points to 0, effectively flattening the original 3D ellipsoid into a 2D ellipse. Such a design provides clear guidance to the optimizer. By treating the local z-axis as the normal direction, it greatly improves optimization stability and surface alignment. While the derivatives to the local z-axis computed from the covariance matrix are zero in this setting, we design a self-supervised normal-depth consistency loss to remedy this issue. Monocular normal priors and foreground masks are incorporated to enhance the quality of the reconstruction, mitigating issues related to highlights and background. We propose a volumetric cutting method to aggregate the information of Gaussian surfels so as to remove erroneous points in depth maps generated by alpha blending. Finally, we apply screened Poisson reconstruction method to the fused depth maps to extract the surface mesh. Experimental results show that our method demonstrates superior performance in surface reconstruction compared to state-of-the-art neural volume rendering and point-based rendering methods.