 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHetScene: Heterogeneity-Aware Diffusion for Dense Indoor Scene Generation
May 13, 2026Generating controllable and physically plausible indoor scenes is a pivotal prerequisite for constructing high-fidelity simulation environments for embodied AI. However, existing deeplearning-based methods usually treat all objects as homogeneous instances within a unified generation process. While effective for sparse and simplistic layouts, they struggle to model realistic layouts with dense object arrangements and complex spatial dependencies, leadingto limited scalability and degraded physical plausibility. To deal with these challenges, we revisit indoor layout generation from the perspective of structural heterogeneity and decompose the objects into primary objects and secondary objects according to their distinct roles in shaping a scene. Based on this decomposition, we propose HetScene, a heterogeneous two-stage generation framework that decouples indoor layout synthesis into Structural Layout Generation (SLG) and Contextual Layout Generation (CLG). SLG first generates globally coherent structural layouts with only primary objects conditioned on text descriptions, top-down binary room masks, and spatial relation graphs, establishing a stable global macro-skeleton of large core furniture.
Behavioral Score Diffusion: Model-Free Trajectory Planning via Kernel-Based Score Estimation from Data
Apr 01, 2026Diffusion-based trajectory optimization has emerged as a powerful planning paradigm, but existing methods require either learned score networks trained on large datasets or analytical dynamics models for score computation. We introduce \emph{Behavioral Score Diffusion} (BSD), a training-free and model-free trajectory planner that computes the diffusion score function directly from a library of trajectory data via kernel-weighted estimation. At each denoising step, BSD retrieves relevant trajectories using a triple-kernel weighting scheme -- diffusion proximity, state context, and goal relevance -- and computes a Nadaraya-Watson estimate of the denoised trajectory. The diffusion noise schedule naturally controls kernel bandwidths, creating a multi-scale nonparametric regression: broad averaging of global behavioral patterns at high noise, fine-grained local interpolation at low noise. This coarse-to-fine structure handles nonlinear dynamics without linearization or parametric assumptions. Safety is preserved by applying shielded rollout on kernel-estimated state trajectories, identical to existing model-based approaches. We evaluate BSD on four robotic systems of increasing complexity (3D--6D state spaces) in a parking scenario. BSD with fixed bandwidth achieves 98.5\% of the model-based baseline's average reward across systems while requiring no dynamics model, using only 1{,}000 pre-collected trajectories. BSD substantially outperforms nearest-neighbor retrieval (18--63\% improvement), confirming that the diffusion denoising mechanism is essential for effective data-driven planning.
Fast Non-Episodic Finite-Horizon RL with K-Step Lookahead Thresholding
Jan 31, 2026Online reinforcement learning in non-episodic, finite-horizon MDPs remains underexplored and is challenged by the need to estimate returns to a fixed terminal time. Existing infinite-horizon methods, which often rely on discounted contraction, do not naturally account for this fixed-horizon structure. We introduce a modified Q-function: rather than targeting the full-horizon, we learn a K-step lookahead Q-function that truncates planning to the next K steps. To further improve sample efficiency, we introduce a thresholding mechanism: actions are selected only when their estimated K-step lookahead value exceeds a time-varying threshold. We provide an efficient tabular learning algorithm for this novel objective, proving it achieves fast finite-sample convergence: it achieves minimax optimal constant regret for $K=1$ and $\mathcal{O}(\max((K-1),C_{K-1})\sqrt{SAT\log(T)})$ regret for any $K \geq 2$. We numerically evaluate the performance of our algorithm under the objective of maximizing reward. Our implementation adaptively increases K over time, balancing lookahead depth against estimation variance. Empirical results demonstrate superior cumulative rewards over state-of-the-art tabular RL methods across synthetic MDPs and RL environments: JumpRiverswim, FrozenLake and AnyTrading.
Algorithm-Relative Trajectory Valuation in Policy Gradient Control
Nov 11, 2025We study how trajectory value depends on the learning algorithm in policy-gradient control. Using Trajectory Shapley in an uncertain LQR, we find a negative correlation between Persistence of Excitation (PE) and marginal value under vanilla REINFORCE ($r\approx-0.38$). We prove a variance-mediated mechanism: (i) for fixed energy, higher PE yields lower gradient variance; (ii) near saddles, higher variance increases escape probability, raising marginal contribution. When stabilized (state whitening or Fisher preconditioning), this variance channel is neutralized and information content dominates, flipping the correlation positive ($r\approx+0.29$). Hence, trajectory value is algorithm-relative. Experiments validate the mechanism and show decision-aligned scores (Leave-One-Out) complement Shapley for pruning, while Shapley identifies toxic subsets.
MatTools: Benchmarking Large Language Models for Materials Science Tools
May 16, 2025



Large language models (LLMs) are increasingly applied to materials science questions, including literature comprehension, property prediction, materials discovery and alloy design. At the same time, a wide range of physics-based computational approaches have been developed in which materials properties can be calculated. Here, we propose a benchmark application to evaluate the proficiency of LLMs to answer materials science questions through the generation and safe execution of codes based on such physics-based computational materials science packages. MatTools is built on two complementary components: a materials simulation tool question-answer (QA) benchmark and a real-world tool-usage benchmark. We designed an automated methodology to efficiently collect real-world materials science tool-use examples. The QA benchmark, derived from the pymatgen (Python Materials Genomics) codebase and documentation, comprises 69,225 QA pairs that assess the ability of an LLM to understand materials science tools. The real-world benchmark contains 49 tasks (138 subtasks) requiring the generation of functional Python code for materials property calculations. Our evaluation of diverse LLMs yields three key insights: (1)Generalists outshine specialists;(2)AI knows AI; and (3)Simpler is better. MatTools provides a standardized framework for assessing and improving LLM capabilities for materials science tool applications, facilitating the development of more effective AI systems for materials science and general scientific research.
From Restless to Contextual: A Thresholding Bandit Approach to Improve Finite-horizon Performance
Feb 07, 2025
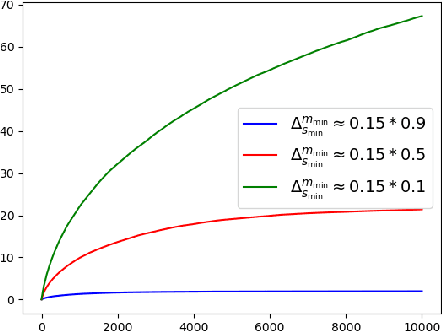
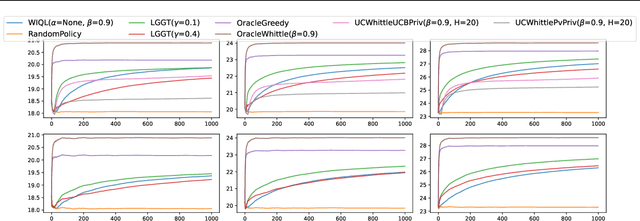
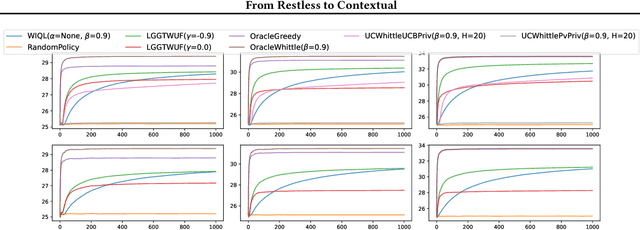
Online restless bandits extend classic contextual bandits by incorporating state transitions and budget constraints, representing each agent as a Markov Decision Process (MDP). This framework is crucial for finite-horizon strategic resource allocation, optimizing limited costly interventions for long-term benefits. However, learning the underlying MDP for each agent poses a major challenge in finite-horizon settings. To facilitate learning, we reformulate the problem as a scalable budgeted thresholding contextual bandit problem, carefully integrating the state transitions into the reward design and focusing on identifying agents with action benefits exceeding a threshold. We establish the optimality of an oracle greedy solution in a simple two-state setting, and propose an algorithm that achieves minimax optimal constant regret in the online multi-state setting with heterogeneous agents and knowledge of outcomes under no intervention. We numerically show that our algorithm outperforms existing online restless bandit methods, offering significant improvements in finite-horizon performance.
Detail-Preserving Latent Diffusion for Stable Shadow Removal
Dec 23, 2024Achieving high-quality shadow removal with strong generalizability is challenging in scenes with complex global illumination. Due to the limited diversity in shadow removal datasets, current methods are prone to overfitting training data, often leading to reduced performance on unseen cases. To address this, we leverage the rich visual priors of a pre-trained Stable Diffusion (SD) model and propose a two-stage fine-tuning pipeline to adapt the SD model for stable and efficient shadow removal. In the first stage, we fix the VAE and fine-tune the denoiser in latent space, which yields substantial shadow removal but may lose some high-frequency details. To resolve this, we introduce a second stage, called the detail injection stage. This stage selectively extracts features from the VAE encoder to modulate the decoder, injecting fine details into the final results. Experimental results show that our method outperforms state-of-the-art shadow removal techniques. The cross-dataset evaluation further demonstrates that our method generalizes effectively to unseen data, enhancing the applicability of shadow removal methods.
OmniSR: Shadow Removal under Direct and Indirect Lighting
Oct 02, 2024



Shadows can originate from occlusions in both direct and indirect illumination. Although most current shadow removal research focuses on shadows caused by direct illumination, shadows from indirect illumination are often just as pervasive, particularly in indoor scenes. A significant challenge in removing shadows from indirect illumination is obtaining shadow-free images to train the shadow removal network. To overcome this challenge, we propose a novel rendering pipeline for generating shadowed and shadow-free images under direct and indirect illumination, and create a comprehensive synthetic dataset that contains over 30,000 image pairs, covering various object types and lighting conditions. We also propose an innovative shadow removal network that explicitly integrates semantic and geometric priors through concatenation and attention mechanisms. The experiments show that our method outperforms state-of-the-art shadow removal techniques and can effectively generalize to indoor and outdoor scenes under various lighting conditions, enhancing the overall effectiveness and applicability of shadow removal methods.
High-quality Surface Reconstruction using Gaussian Surfels
Apr 30, 2024We propose a novel point-based representation, Gaussian surfels, to combine the advantages of the flexible optimization procedure in 3D Gaussian points and the surface alignment property of surfels. This is achieved by directly setting the z-scale of 3D Gaussian points to 0, effectively flattening the original 3D ellipsoid into a 2D ellipse. Such a design provides clear guidance to the optimizer. By treating the local z-axis as the normal direction, it greatly improves optimization stability and surface alignment. While the derivatives to the local z-axis computed from the covariance matrix are zero in this setting, we design a self-supervised normal-depth consistency loss to remedy this issue. Monocular normal priors and foreground masks are incorporated to enhance the quality of the reconstruction, mitigating issues related to highlights and background. We propose a volumetric cutting method to aggregate the information of Gaussian surfels so as to remove erroneous points in depth maps generated by alpha blending. Finally, we apply screened Poisson reconstruction method to the fused depth maps to extract the surface mesh. Experimental results show that our method demonstrates superior performance in surface reconstruction compared to state-of-the-art neural volume rendering and point-based rendering methods.
SAR-to-Optical Image Translation via Thermodynamics-inspired Network
May 23, 2023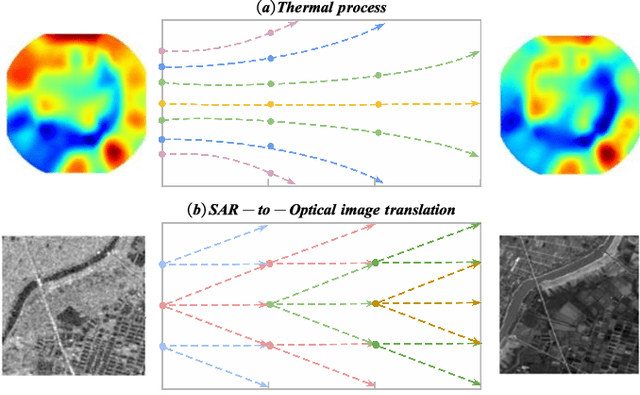
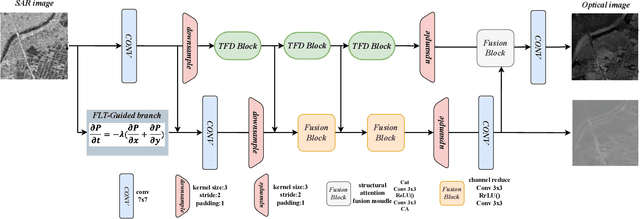
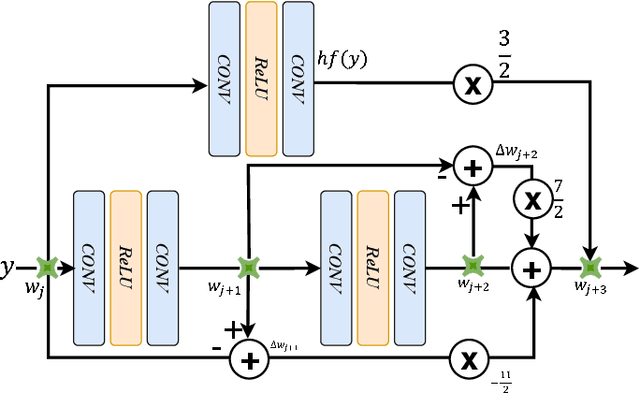
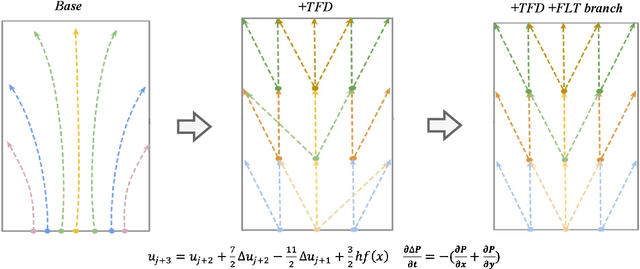
Synthetic aperture radar (SAR) is prevalent in the remote sensing field but is difficult to interpret in human visual perception. Recently, SAR-to-optical (S2O) image conversion methods have provided a prospective solution for interpretation. However, since there is a huge domain difference between optical and SAR images, they suffer from low image quality and geometric distortion in the produced optical images. Motivated by the analogy between pixels during the S2O image translation and molecules in a heat field, Thermodynamics-inspired Network for SAR-to-Optical Image Translation (S2O-TDN) is proposed in this paper. Specifically, we design a Third-order Finite Difference (TFD) residual structure in light of the TFD equation of thermodynamics, which allows us to efficiently extract inter-domain invariant features and facilitate the learning of the nonlinear translation mapping. In addition, we exploit the first law of thermodynamics (FLT) to devise an FLT-guided branch that promotes the state transition of the feature values from the unstable diffusion state to the stable one, aiming to regularize the feature diffusion and preserve image structures during S2O image translation. S2O-TDN follows an explicit design principle derived from thermodynamic theory and enjoys the advantage of explainability. Experiments on the public SEN1-2 dataset show the advantages of the proposed S2O-TDN over the current methods with more delicate textures and higher quantitative results.