 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetail-Preserving Latent Diffusion for Stable Shadow Removal
Dec 23, 2024Achieving high-quality shadow removal with strong generalizability is challenging in scenes with complex global illumination. Due to the limited diversity in shadow removal datasets, current methods are prone to overfitting training data, often leading to reduced performance on unseen cases. To address this, we leverage the rich visual priors of a pre-trained Stable Diffusion (SD) model and propose a two-stage fine-tuning pipeline to adapt the SD model for stable and efficient shadow removal. In the first stage, we fix the VAE and fine-tune the denoiser in latent space, which yields substantial shadow removal but may lose some high-frequency details. To resolve this, we introduce a second stage, called the detail injection stage. This stage selectively extracts features from the VAE encoder to modulate the decoder, injecting fine details into the final results. Experimental results show that our method outperforms state-of-the-art shadow removal techniques. The cross-dataset evaluation further demonstrates that our method generalizes effectively to unseen data, enhancing the applicability of shadow removal methods.
OmniSR: Shadow Removal under Direct and Indirect Lighting
Oct 02, 2024



Shadows can originate from occlusions in both direct and indirect illumination. Although most current shadow removal research focuses on shadows caused by direct illumination, shadows from indirect illumination are often just as pervasive, particularly in indoor scenes. A significant challenge in removing shadows from indirect illumination is obtaining shadow-free images to train the shadow removal network. To overcome this challenge, we propose a novel rendering pipeline for generating shadowed and shadow-free images under direct and indirect illumination, and create a comprehensive synthetic dataset that contains over 30,000 image pairs, covering various object types and lighting conditions. We also propose an innovative shadow removal network that explicitly integrates semantic and geometric priors through concatenation and attention mechanisms. The experiments show that our method outperforms state-of-the-art shadow removal techniques and can effectively generalize to indoor and outdoor scenes under various lighting conditions, enhancing the overall effectiveness and applicability of shadow removal methods.
Class-balanced Open-set Semi-supervised Object Detection for Medical Images
Aug 22, 2024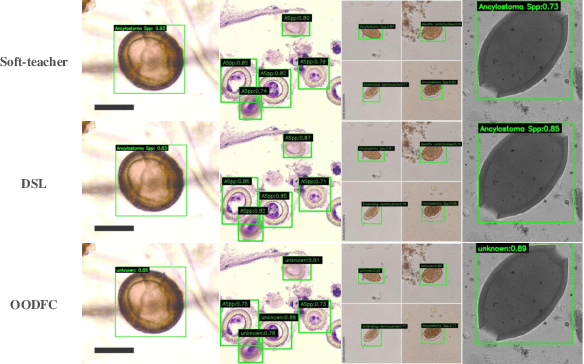
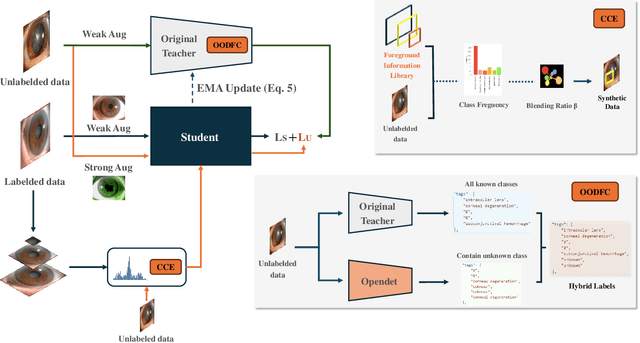
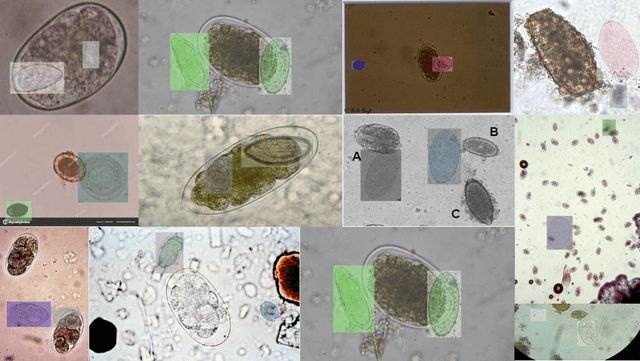
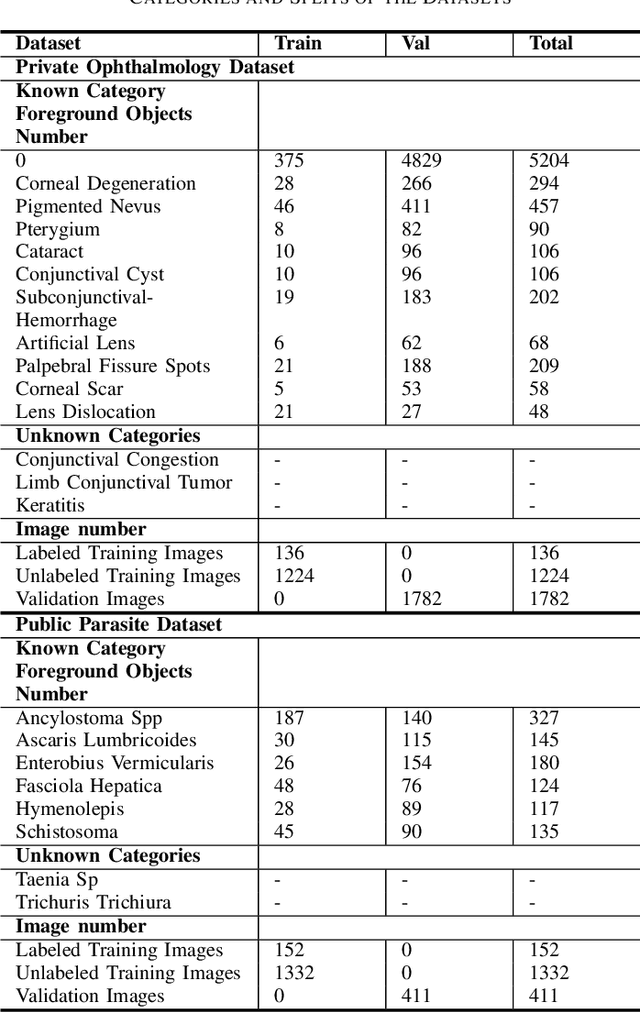
Medical image datasets in the real world are often unlabeled and imbalanced, and Semi-Supervised Object Detection (SSOD) can utilize unlabeled data to improve an object detector. However, existing approaches predominantly assumed that the unlabeled data and test data do not contain out-of-distribution (OOD) classes. The few open-set semi-supervised object detection methods have two weaknesses: first, the class imbalance is not considered; second, the OOD instances are distinguished and simply discarded during pseudo-labeling. In this paper, we consider the open-set semi-supervised object detection problem which leverages unlabeled data that contain OOD classes to improve object detection for medical images. Our study incorporates two key innovations: Category Control Embed (CCE) and out-of-distribution Detection Fusion Classifier (OODFC). CCE is designed to tackle dataset imbalance by constructing a Foreground information Library, while OODFC tackles open-set challenges by integrating the ``unknown'' information into basic pseudo-labels. Our method outperforms the state-of-the-art SSOD performance, achieving a 4.25 mAP improvement on the public Parasite dataset.
TTMFN: Two-stream Transformer-based Multimodal Fusion Network for Survival Prediction
Nov 13, 2023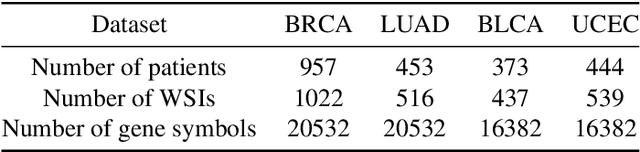
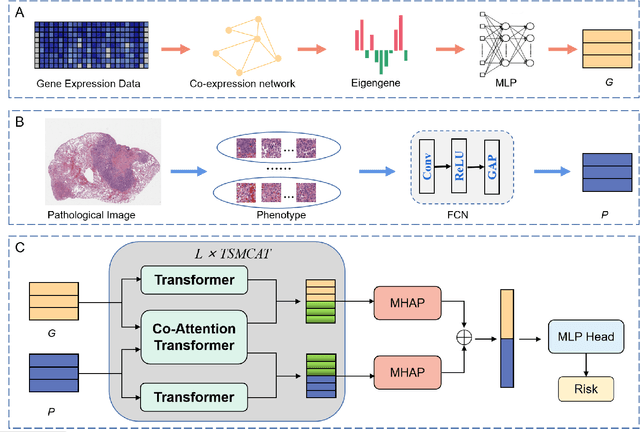
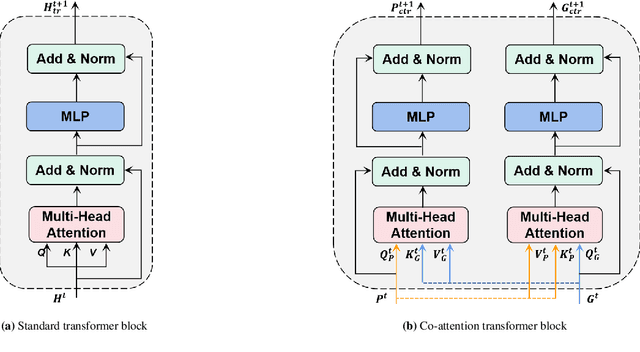
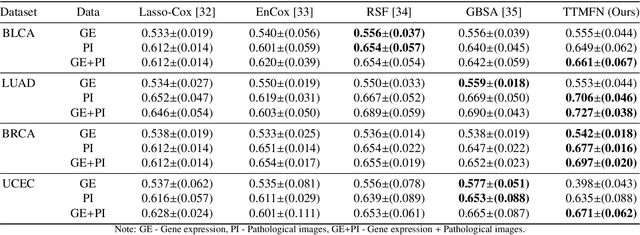
Survival prediction plays a crucial role in assisting clinicians with the development of cancer treatment protocols. Recent evidence shows that multimodal data can help in the diagnosis of cancer disease and improve survival prediction. Currently, deep learning-based approaches have experienced increasing success in survival prediction by integrating pathological images and gene expression data. However, most existing approaches overlook the intra-modality latent information and the complex inter-modality correlations. Furthermore, existing modalities do not fully exploit the immense representational capabilities of neural networks for feature aggregation and disregard the importance of relationships between features. Therefore, it is highly recommended to address these issues in order to enhance the prediction performance by proposing a novel deep learning-based method. We propose a novel framework named Two-stream Transformer-based Multimodal Fusion Network for survival prediction (TTMFN), which integrates pathological images and gene expression data. In TTMFN, we present a two-stream multimodal co-attention transformer module to take full advantage of the complex relationships between different modalities and the potential connections within the modalities. Additionally, we develop a multi-head attention pooling approach to effectively aggregate the feature representations of the two modalities. The experiment results on four datasets from The Cancer Genome Atlas demonstrate that TTMFN can achieve the best performance or competitive results compared to the state-of-the-art methods in predicting the overall survival of patients.
VTP: Volumetric Transformer for Multi-view Multi-person 3D Pose Estimation
May 25, 2022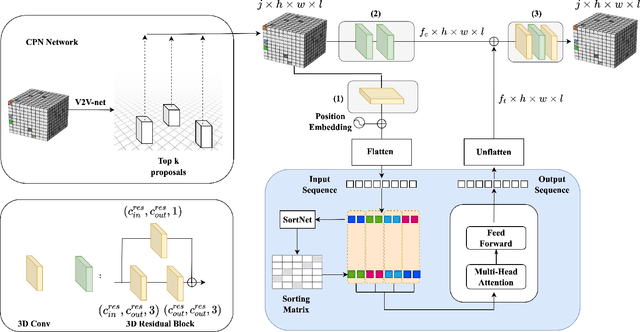
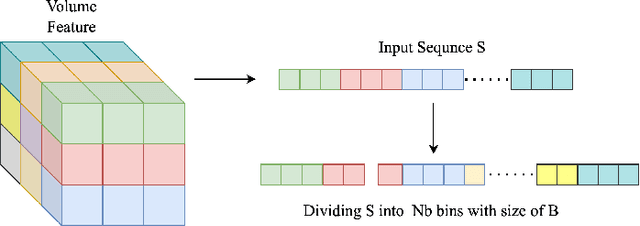
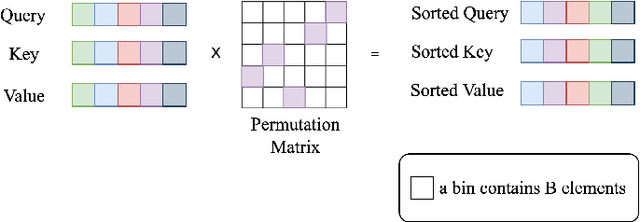
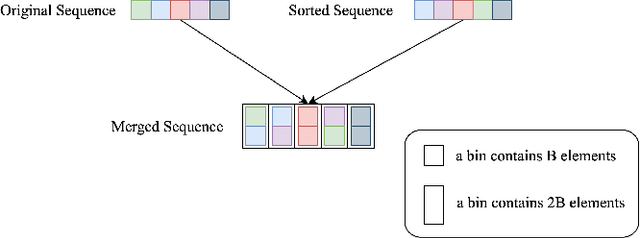
This paper presents Volumetric Transformer Pose estimator (VTP), the first 3D volumetric transformer framework for multi-view multi-person 3D human pose estimation. VTP aggregates features from 2D keypoints in all camera views and directly learns the spatial relationships in the 3D voxel space in an end-to-end fashion. The aggregated 3D features are passed through 3D convolutions before being flattened into sequential embeddings and fed into a transformer. A residual structure is designed to further improve the performance. In addition, the sparse Sinkhorn attention is empowered to reduce the memory cost, which is a major bottleneck for volumetric representations, while also achieving excellent performance. The output of the transformer is again concatenated with 3D convolutional features by a residual design. The proposed VTP framework integrates the high performance of the transformer with volumetric representations, which can be used as a good alternative to the convolutional backbones. Experiments on the Shelf, Campus and CMU Panoptic benchmarks show promising results in terms of both Mean Per Joint Position Error (MPJPE) and Percentage of Correctly estimated Parts (PCP). Our code will be available.
Resistance-Time Co-Modulated PointNet for Temporal Super-Resolution Simulation of Blood Vessel Flows
Nov 19, 2021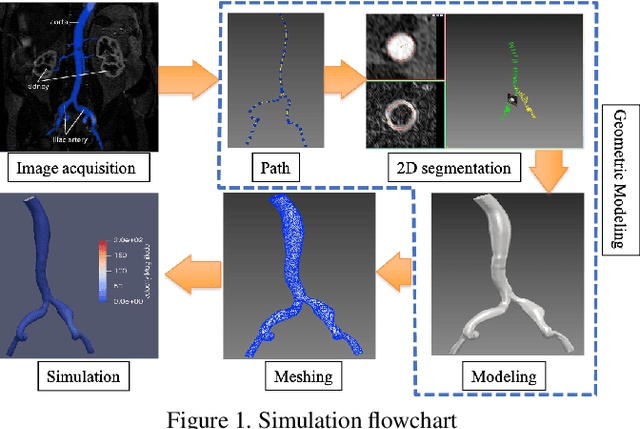
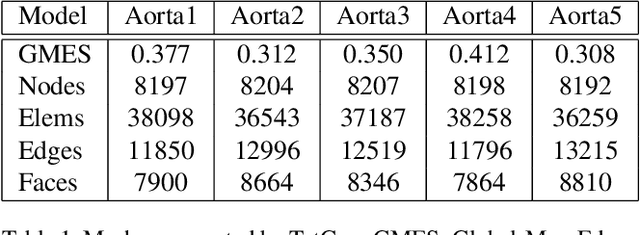
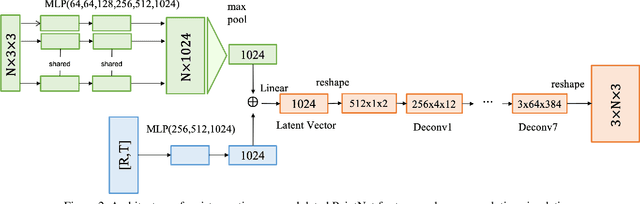
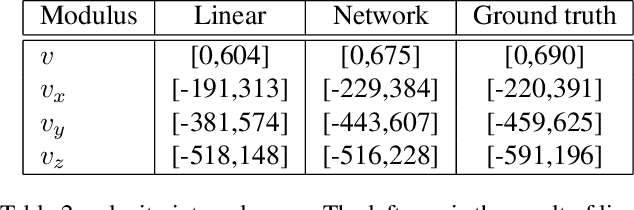
In this paper, a novel deep learning framework is proposed for temporal super-resolution simulation of blood vessel flows, in which a high-temporal-resolution time-varying blood vessel flow simulation is generated from a low-temporal-resolution flow simulation result. In our framework, point-cloud is used to represent the complex blood vessel model, resistance-time aided PointNet model is proposed for extracting the time-space features of the time-varying flow field, and finally we can reconstruct the high-accuracy and high-resolution flow field through the Decoder module. In particular, the amplitude loss and the orientation loss of the velocity are proposed from the vector characteristics of the velocity. And the combination of these two metrics constitutes the final loss function for network training. Several examples are given to illustrate the effective and efficiency of the proposed framework for temporal super-resolution simulation of blood vessel flows.
Track without Appearance: Learn Box and Tracklet Embedding with Local and Global Motion Patterns for Vehicle Tracking
Aug 13, 2021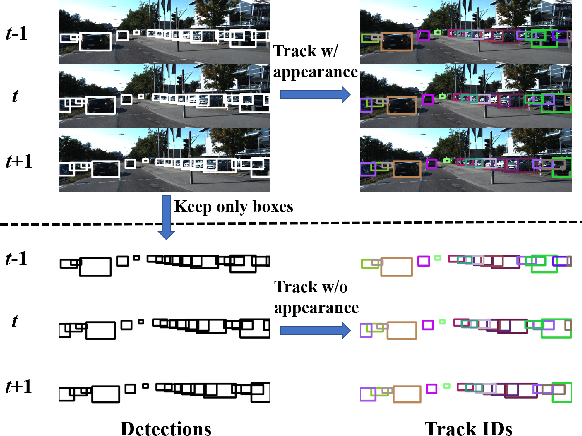
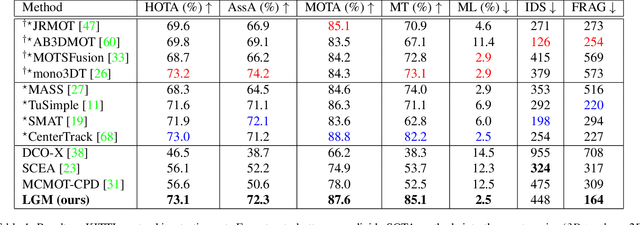

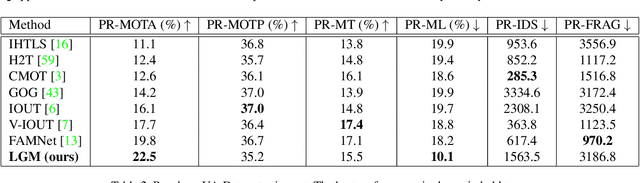
Vehicle tracking is an essential task in the multi-object tracking (MOT) field. A distinct characteristic in vehicle tracking is that the trajectories of vehicles are fairly smooth in both the world coordinate and the image coordinate. Hence, models that capture motion consistencies are of high necessity. However, tracking with the standalone motion-based trackers is quite challenging because targets could get lost easily due to limited information, detection error and occlusion. Leveraging appearance information to assist object re-identification could resolve this challenge to some extent. However, doing so requires extra computation while appearance information is sensitive to occlusion as well. In this paper, we try to explore the significance of motion patterns for vehicle tracking without appearance information. We propose a novel approach that tackles the association issue for long-term tracking with the exclusive fully-exploited motion information. We address the tracklet embedding issue with the proposed reconstruct-to-embed strategy based on deep graph convolutional neural networks (GCN). Comprehensive experiments on the KITTI-car tracking dataset and UA-Detrac dataset show that the proposed method, though without appearance information, could achieve competitive performance with the state-of-the-art (SOTA) trackers. The source code will be available at https://github.com/GaoangW/LGMTracker.
LASOR: Learning Accurate 3D Human Pose and Shape Via Synthetic Occlusion-Aware Data and Neural Mesh Rendering
Aug 01, 2021

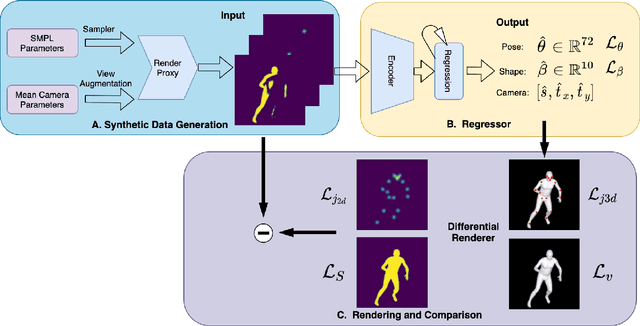
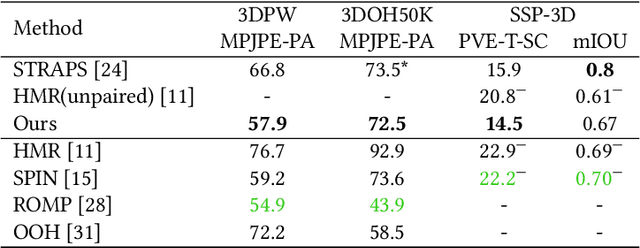
A key challenge in the task of human pose and shape estimation is occlusion, including self-occlusions, object-human occlusions, and inter-person occlusions. The lack of diverse and accurate pose and shape training data becomes a major bottleneck, especially for scenes with occlusions in the wild. In this paper, we focus on the estimation of human pose and shape in the case of inter-person occlusions, while also handling object-human occlusions and self-occlusion. We propose a framework that synthesizes occlusion-aware silhouette and 2D keypoints data and directly regress to the SMPL pose and shape parameters. A neural 3D mesh renderer is exploited to enable silhouette supervision on the fly, which contributes to great improvements in shape estimation. In addition, keypoints-and-silhouette-driven training data in panoramic viewpoints are synthesized to compensate for the lack of viewpoint diversity in any existing dataset. Experimental results show that we are among state-of-the-art on the 3DPW dataset in terms of pose accuracy and evidently outperform the rank-1 method in terms of shape accuracy. Top performance is also achieved on SSP-3D in terms of shape prediction accuracy.
Split and Connect: A Universal Tracklet Booster for Multi-Object Tracking
May 06, 2021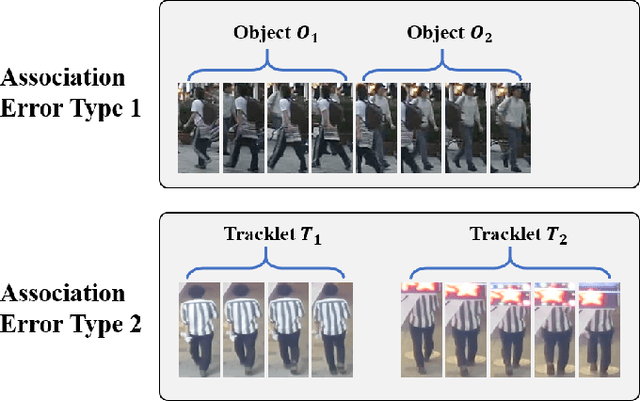
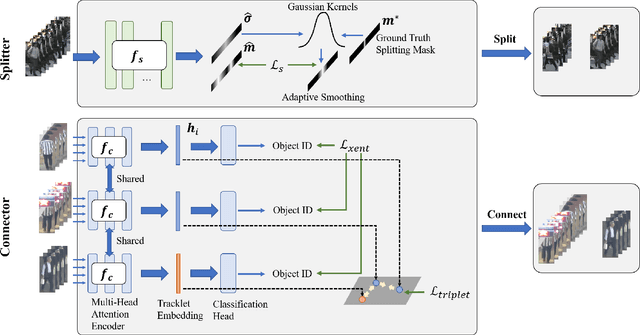

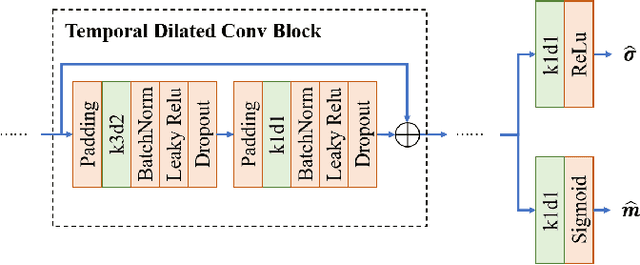
Multi-object tracking (MOT) is an essential task in the computer vision field. With the fast development of deep learning technology in recent years, MOT has achieved great improvement. However, some challenges still remain, such as sensitiveness to occlusion, instability under different lighting conditions, non-robustness to deformable objects, etc. To address such common challenges in most of the existing trackers, in this paper, a tracklet booster algorithm is proposed, which can be built upon any other tracker. The motivation is simple and straightforward: split tracklets on potential ID-switch positions and then connect multiple tracklets into one if they are from the same object. In other words, the tracklet booster consists of two parts, i.e., Splitter and Connector. First, an architecture with stacked temporal dilated convolution blocks is employed for the splitting position prediction via label smoothing strategy with adaptive Gaussian kernels. Then, a multi-head self-attention based encoder is exploited for the tracklet embedding, which is further used to connect tracklets into larger groups. We conduct sufficient experiments on MOT17 and MOT20 benchmark datasets, which demonstrates promising results. Combined with the proposed tracklet booster, existing trackers usually can achieve large improvements on the IDF1 score, which shows the effectiveness of the proposed method.
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Oct 31, 2020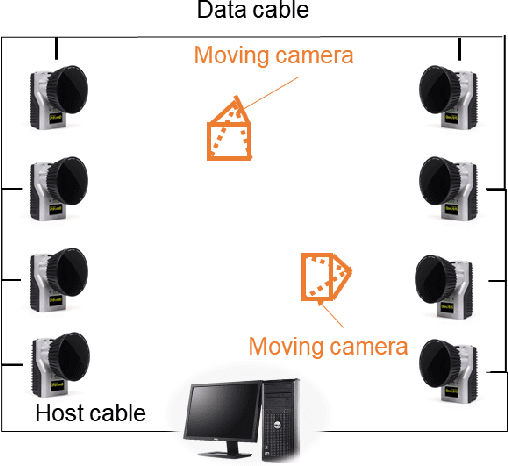


3D human pose estimation (HPE) is crucial in many fields, such as human behavior analysis, augmented reality/virtual reality (AR/VR) applications, and self-driving industry. Videos that contain multiple potentially occluded people captured from freely moving monocular cameras are very common in real-world scenarios, while 3D HPE for such scenarios is quite challenging, partially because there is a lack of such data with accurate 3D ground truth labels in existing datasets. In this paper, we propose a temporal regression network with a gated convolution module to transform 2D joints to 3D and recover the missing occluded joints in the meantime. A simple yet effective localization approach is further conducted to transform the normalized pose to the global trajectory. To verify the effectiveness of our approach, we also collect a new moving camera multi-human (MMHuman) dataset that includes multiple people with heavy occlusion captured by moving cameras. The 3D ground truth joints are provided by accurate motion capture (MoCap) system. From the experiments on static-camera based Human3.6M data and our own collected moving-camera based data, we show that our proposed method outperforms most state-of-the-art 2D-to-3D pose estimation methods, especially for the scenarios with heavy occlusions.