 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Temporal Attention based Target Vehicle Trajectory Prediction for Internet of Vehicles
Jan 01, 2025



Forecasting vehicle behavior within complex traffic environments is pivotal within Intelligent Transportation Systems (ITS). Though this technology plays a significant role in alleviating the prevalent operational difficulties in logistics and transportation systems, the precise prediction of vehicle trajectories still poses a substantial challenge. To address this, our study introduces the Spatio Temporal Attention-based methodology for Target Vehicle Trajectory Prediction (STATVTPred). This approach integrates Global Positioning System(GPS) localization technology to track target movement and dynamically predict the vehicle's future path using comprehensive spatio-temporal trajectory data. We map the vehicle trajectory onto a directed graph, after which spatial attributes are extracted via a Graph Attention Networks(GATs). The Transformer technology is employed to yield temporal features from the sequence. These elements are then amalgamated with local road network structure maps to filter and deliver a smooth trajectory sequence, resulting in precise vehicle trajectory prediction.This study validates our proposed STATVTPred method on T-Drive and Chengdu taxi-trajectory datasets. The experimental results demonstrate that STATVTPred achieves 6.38% and 10.55% higher Average Match Rate (AMR) than the Transformer model on the Beijing and Chengdu datasets, respectively. Compared to the LSTM Encoder-Decoder model, STATVTPred boosts AMR by 37.45% and 36.06% on the same datasets. This is expected to establish STATVTPred as a new approach for handling trajectory prediction of targets in logistics and transportation scenarios, thereby enhancing prediction accuracy.
Edge-guided inverse design of digital metamaterials for ultra-high-capacity on-chip multi-dimensional interconnect
Oct 10, 2024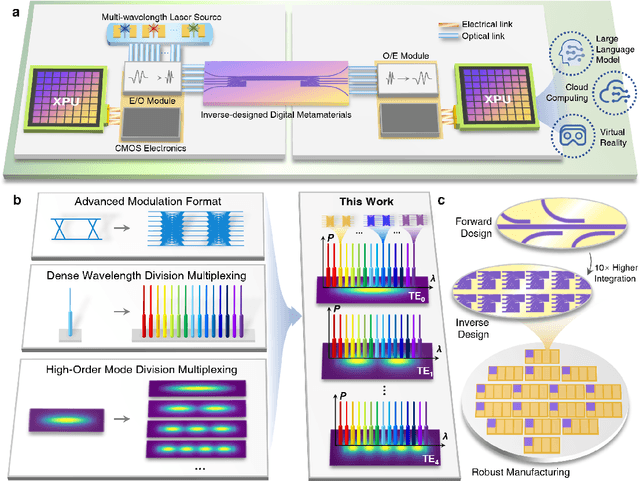
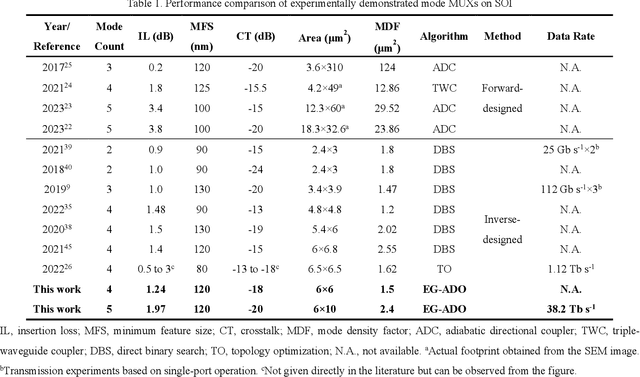
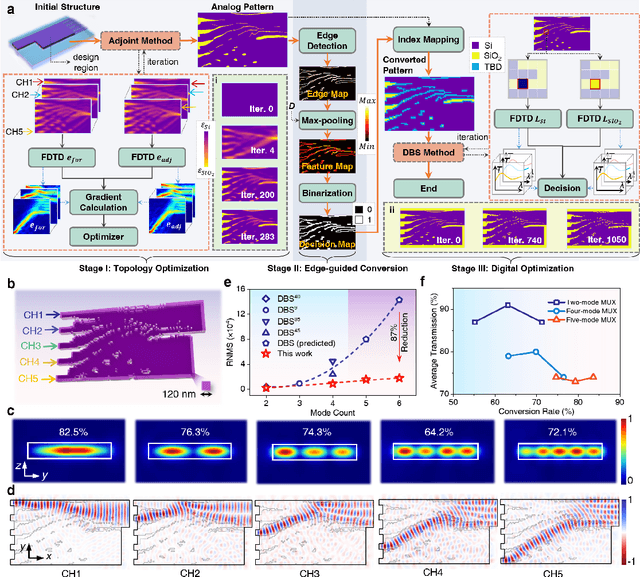
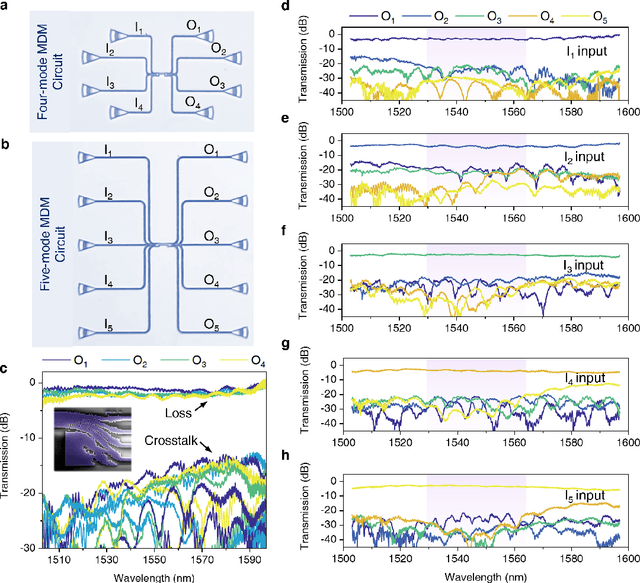
The escalating demands of compute-intensive applications, including artificial intelligence, urgently necessitate the adoption of sophisticated optical on-chip interconnect technologies to overcome critical bottlenecks in scaling future computing systems. This transition requires leveraging the inherent parallelism of wavelength and mode dimensions of light, complemented by high-order modulation formats, to significantly enhance data throughput. Here we experimentally demonstrate a novel synergy of these three dimensions, achieving multi-tens-of-terabits-per-second on-chip interconnects using ultra-broadband, multi-mode digital metamaterials. Employing a highly efficient edge-guided analog-and-digital optimization method, we inversely design foundry-compatible, robust, and multi-port digital metamaterials with an 8xhigher computational efficiency. Using a packaged five-mode multiplexing chip, we demonstrate a single-wavelength interconnect capacity of 1.62 Tbit s-1 and a record-setting multi-dimensional interconnect capacity of 38.2 Tbit s-1 across 5 modes and 88 wavelength channels. A theoretical analysis suggests that further system optimization can enable on-chip interconnects to reach sub-petabit-per-second data transmission rates. This study highlights the transformative potential of optical interconnect technologies to surmount the constraints of electronic links, thus setting the stage for next-generation datacenter and optical compute interconnects.
VTP: Volumetric Transformer for Multi-view Multi-person 3D Pose Estimation
May 25, 2022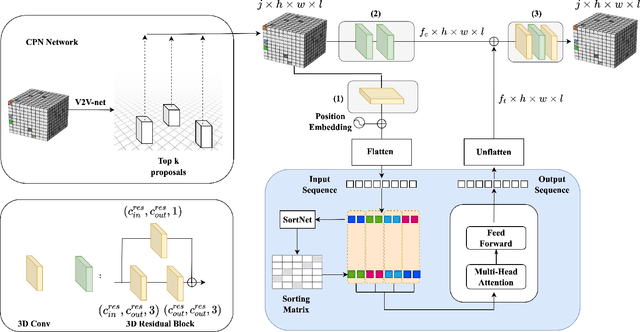
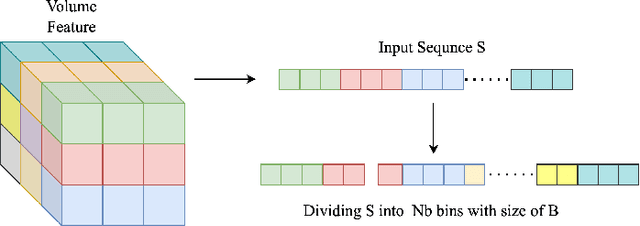
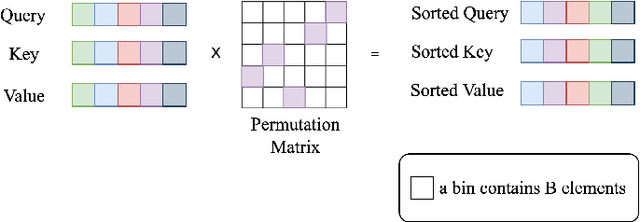
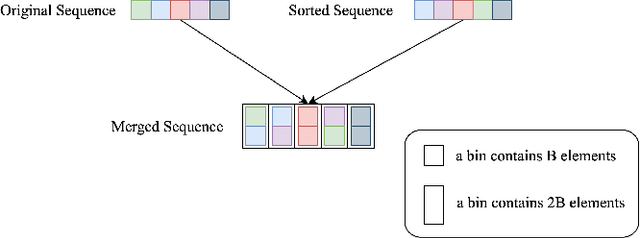
This paper presents Volumetric Transformer Pose estimator (VTP), the first 3D volumetric transformer framework for multi-view multi-person 3D human pose estimation. VTP aggregates features from 2D keypoints in all camera views and directly learns the spatial relationships in the 3D voxel space in an end-to-end fashion. The aggregated 3D features are passed through 3D convolutions before being flattened into sequential embeddings and fed into a transformer. A residual structure is designed to further improve the performance. In addition, the sparse Sinkhorn attention is empowered to reduce the memory cost, which is a major bottleneck for volumetric representations, while also achieving excellent performance. The output of the transformer is again concatenated with 3D convolutional features by a residual design. The proposed VTP framework integrates the high performance of the transformer with volumetric representations, which can be used as a good alternative to the convolutional backbones. Experiments on the Shelf, Campus and CMU Panoptic benchmarks show promising results in terms of both Mean Per Joint Position Error (MPJPE) and Percentage of Correctly estimated Parts (PCP). Our code will be available.
Exploring Global Diversity and Local Context for Video Summarization
Jan 27, 2022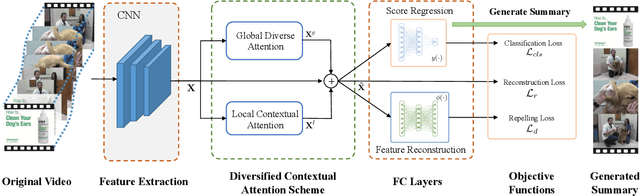

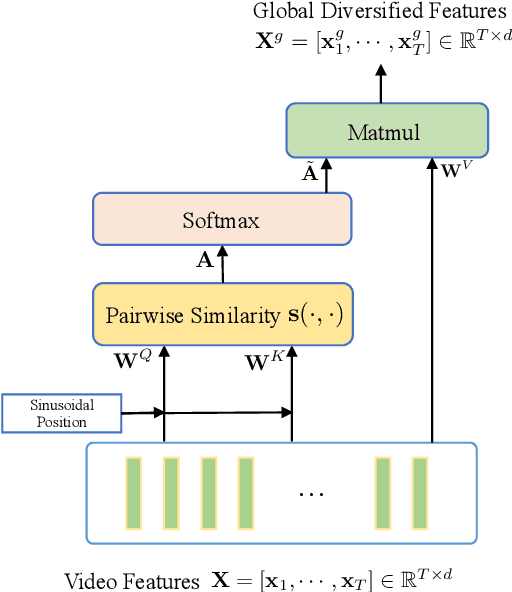
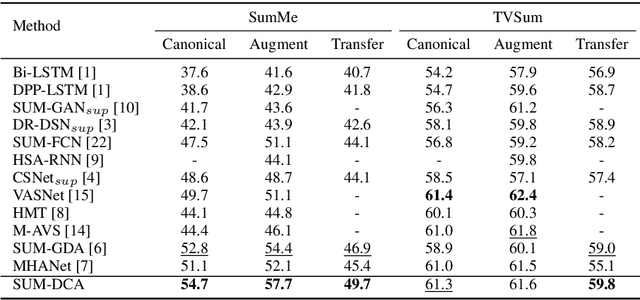
Video summarization aims to automatically generate a diverse and concise summary which is useful in large-scale video processing. Most of methods tend to adopt self attention mechanism across video frames, which fails to model the diversity of video frames. To alleviate this problem, we revisit the pairwise similarity measurement in self attention mechanism and find that the existing inner-product affinity leads to discriminative features rather than diversified features. In light of this phenomenon, we propose global diverse attention by using the squared Euclidean distance instead to compute the affinities. Moreover, we model the local contextual information by proposing local contextual attention to remove the redundancy in the video. By combining these two attention mechanism, a video \textbf{SUM}marization model with Diversified Contextual Attention scheme is developed and named as SUM-DCA. Extensive experiments are conducted on benchmark data sets to verify the effectiveness and the superiority of SUM-DCA in terms of F-score and rank-based evaluation without any bells and whistles.