 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Global Diversity and Local Context for Video Summarization
Jan 27, 2022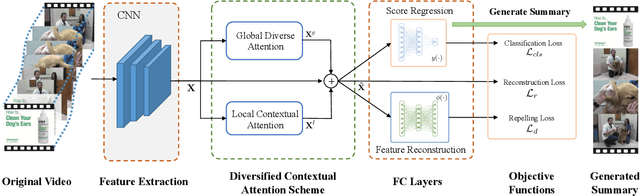

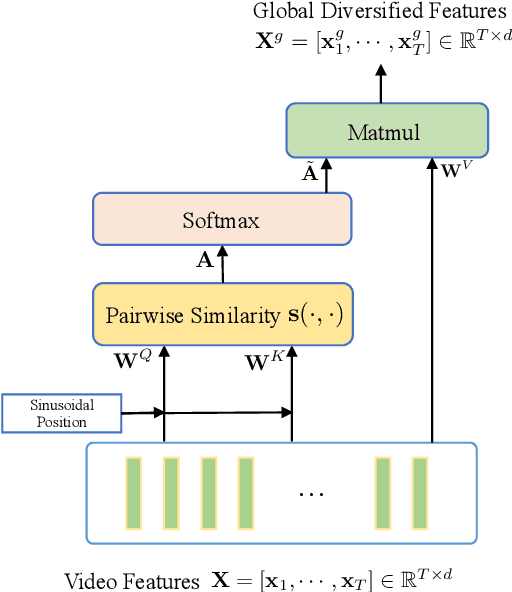
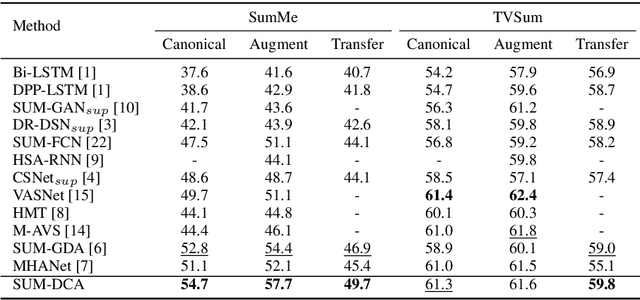
Video summarization aims to automatically generate a diverse and concise summary which is useful in large-scale video processing. Most of methods tend to adopt self attention mechanism across video frames, which fails to model the diversity of video frames. To alleviate this problem, we revisit the pairwise similarity measurement in self attention mechanism and find that the existing inner-product affinity leads to discriminative features rather than diversified features. In light of this phenomenon, we propose global diverse attention by using the squared Euclidean distance instead to compute the affinities. Moreover, we model the local contextual information by proposing local contextual attention to remove the redundancy in the video. By combining these two attention mechanism, a video \textbf{SUM}marization model with Diversified Contextual Attention scheme is developed and named as SUM-DCA. Extensive experiments are conducted on benchmark data sets to verify the effectiveness and the superiority of SUM-DCA in terms of F-score and rank-based evaluation without any bells and whistles.