 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Persona Thinking for Bias Mitigation in Large Language Models
Jan 21, 2026Large Language Models (LLMs) exhibit significant social biases that can perpetuate harmful stereotypes and unfair outcomes. In this paper, we propose Multi-Persona Thinking (MPT), a novel inference-time framework that leverages dialectical reasoning from multiple perspectives to reduce bias. MPT guides models to adopt contrasting social identities (e.g., male and female) along with a neutral viewpoint, and then engages these personas iteratively to expose and correct biases. Through a dialectical reasoning process, the framework transforms the potential weakness of persona assignment into a strength for bias mitigation. We evaluate MPT on two widely used bias benchmarks across both open-source and closed-source models of varying scales. Our results demonstrate substantial improvements over existing prompting-based strategies: MPT achieves the lowest bias while maintaining core reasoning ability.
TriFlow: A Progressive Multi-Agent Framework for Intelligent Trip Planning
Dec 12, 2025



Real-world trip planning requires transforming open-ended user requests into executable itineraries under strict spatial, temporal, and budgetary constraints while aligning with user preferences. Existing LLM-based agents struggle with constraint satisfaction, tool coordination, and efficiency, often producing infeasible or costly plans. To address these limitations, we present TriFlow, a progressive multi-agent framework that unifies structured reasoning and language-based flexibility through a three-stage pipeline of retrieval, planning, and governance. By this design, TriFlow progressively narrows the search space, assembles constraint-consistent itineraries via rule-LLM collaboration, and performs bounded iterative refinement to ensure global feasibility and personalisation. Evaluations on TravelPlanner and TripTailor benchmarks demonstrated state-of-the-art results, achieving 91.1% and 97% final pass rates, respectively, with over 10x runtime efficiency improvement compared to current SOTA.
Action-aware Dynamic Pruning for Efficient Vision-Language-Action Manipulation
Sep 26, 2025Robotic manipulation with Vision-Language-Action models requires efficient inference over long-horizon multi-modal context, where attention to dense visual tokens dominates computational cost. Existing methods optimize inference speed by reducing visual redundancy within VLA models, but they overlook the varying redundancy across robotic manipulation stages. We observe that the visual token redundancy is higher in coarse manipulation phase than in fine-grained operations, and is strongly correlated with the action dynamic. Motivated by this observation, we propose \textbf{A}ction-aware \textbf{D}ynamic \textbf{P}runing (\textbf{ADP}), a multi-modal pruning framework that integrates text-driven token selection with action-aware trajectory gating. Our method introduces a gating mechanism that conditions the pruning signal on recent action trajectories, using past motion windows to adaptively adjust token retention ratios in accordance with dynamics, thereby balancing computational efficiency and perceptual precision across different manipulation stages. Extensive experiments on the LIBERO suites and diverse real-world scenarios demonstrate that our method significantly reduces FLOPs and action inference latency (\textit{e.g.} $1.35 \times$ speed up on OpenVLA-OFT) while maintaining competitive success rates (\textit{e.g.} 25.8\% improvements with OpenVLA) compared to baselines, thereby providing a simple plug-in path to efficient robot policies that advances the efficiency and performance frontier of robotic manipulation. Our project website is: \href{https://vla-adp.github.io/}{ADP.com}.
FoldNet: Learning Generalizable Closed-Loop Policy for Garment Folding via Keypoint-Driven Asset and Demonstration Synthesis
May 14, 2025



Due to the deformability of garments, generating a large amount of high-quality data for robotic garment manipulation tasks is highly challenging. In this paper, we present a synthetic garment dataset that can be used for robotic garment folding. We begin by constructing geometric garment templates based on keypoints and applying generative models to generate realistic texture patterns. Leveraging these keypoint annotations, we generate folding demonstrations in simulation and train folding policies via closed-loop imitation learning. To improve robustness, we propose KG-DAgger, which uses a keypoint-based strategy to generate demonstration data for recovering from failures. KG-DAgger significantly improves the model performance, boosting the real-world success rate by 25\%. After training with 15K trajectories (about 2M image-action pairs), the model achieves a 75\% success rate in the real world. Experiments in both simulation and real-world settings validate the effectiveness of our proposed framework.
RoboHanger: Learning Generalizable Robotic Hanger Insertion for Diverse Garments
Dec 02, 2024



For the task of hanging clothes, learning how to insert a hanger into a garment is crucial but has been seldom explored in robotics. In this work, we address the problem of inserting a hanger into various unseen garments that are initially laid out flat on a table. This task is challenging due to its long-horizon nature, the high degrees of freedom of the garments, and the lack of data. To simplify the learning process, we first propose breaking the task into several stages. Then, we formulate each stage as a policy learning problem and propose low-dimensional action parameterization. To overcome the challenge of limited data, we build our own simulator and create 144 synthetic clothing assets to effectively collect high-quality training data. Our approach uses single-view depth images and object masks as input, which mitigates the Sim2Real appearance gap and achieves high generalization capabilities for new garments. Extensive experiments in both simulation and the real world validate our proposed method. By training on various garments in the simulator, our method achieves a 75\% success rate with 8 different unseen garments in the real world.
An LLM Agent for Automatic Geospatial Data Analysis
Oct 24, 2024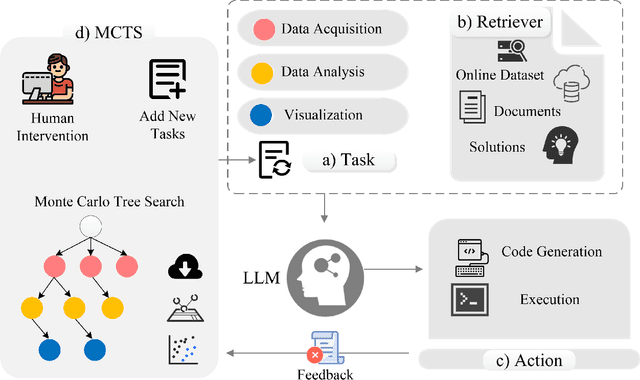
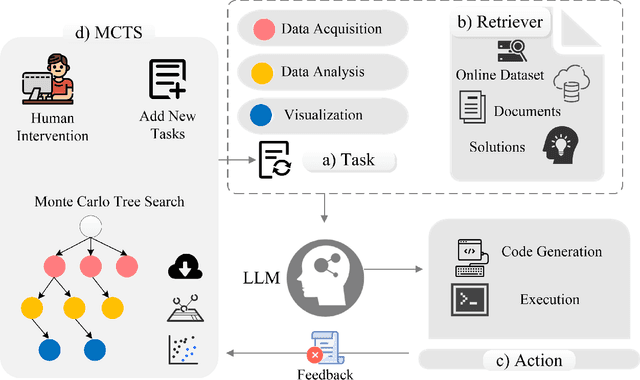

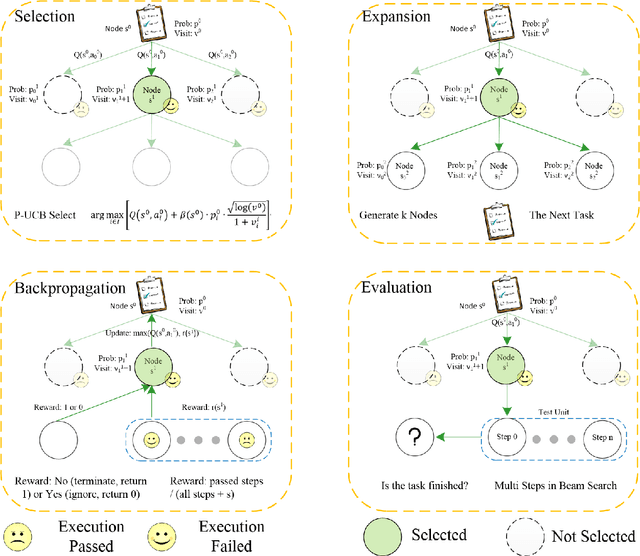
Large language models (LLMs) are being used in data science code generation tasks, but they often struggle with complex sequential tasks, leading to logical errors. Their application to geospatial data processing is particularly challenging due to difficulties in incorporating complex data structures and spatial constraints, effectively utilizing diverse function calls, and the tendency to hallucinate less-used geospatial libraries. To tackle these problems, we introduce GeoAgent, a new interactive framework designed to help LLMs handle geospatial data processing more effectively. GeoAgent pioneers the integration of a code interpreter, static analysis, and Retrieval-Augmented Generation (RAG) techniques within a Monte Carlo Tree Search (MCTS) algorithm, offering a novel approach to geospatial data processing. In addition, we contribute a new benchmark specifically designed to evaluate the LLM-based approach in geospatial tasks. This benchmark leverages a variety of Python libraries and includes both single-turn and multi-turn tasks such as data acquisition, data analysis, and visualization. By offering a comprehensive evaluation among diverse geospatial contexts, this benchmark sets a new standard for developing LLM-based approaches in geospatial data analysis tasks. Our findings suggest that relying solely on knowledge of LLM is insufficient for accurate geospatial task programming, which requires coherent multi-step processes and multiple function calls. Compared to the baseline LLMs, the proposed GeoAgent has demonstrated superior performance, yielding notable improvements in function calls and task completion. In addition, these results offer valuable insights for the future development of LLM agents in automatic geospatial data analysis task programming.
ScissorBot: Learning Generalizable Scissor Skill for Paper Cutting via Simulation, Imitation, and Sim2Real
Sep 21, 2024



This paper tackles the challenging robotic task of generalizable paper cutting using scissors. In this task, scissors attached to a robot arm are driven to accurately cut curves drawn on the paper, which is hung with the top edge fixed. Due to the frequent paper-scissor contact and consequent fracture, the paper features continual deformation and changing topology, which is diffult for accurate modeling. To ensure effective execution, we customize an action primitive sequence for imitation learning to constrain its action space, thus alleviating potential compounding errors. Finally, by integrating sim-to-real techniques to bridge the gap between simulation and reality, our policy can be effectively deployed on the real robot. Experimental results demonstrate that our method surpasses all baselines in both simulation and real-world benchmarks and achieves performance comparable to human operation with a single hand under the same conditions.
NDDEs: A Deep Neural Network Framework for Solving Forward and Inverse Problems in Delay Differential Equations
Aug 17, 2024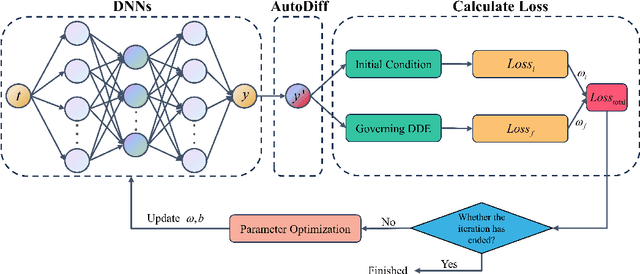

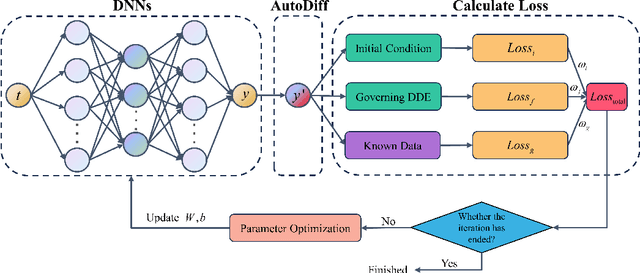

This article proposes a solution framework for delay differential equations (DDEs) based on deep neural networks (DNNs) - the neural delay differential equations (NDDEs), aimed at solving the forward and inverse problems of delay differential equations. This framework embeds the delay differential equations into the neural networks to accommodate the diverse requirements of DDEs in terms of initial conditions, control equations, and known data. NDDEs adjust the network parameters through automatic differentiation and optimization algorithms to minimize the loss function, thereby obtaining numerical solutions to the delay differential equations without the grid dependence and discretization errors typical of traditional numerical methods. In addressing inverse problems, the NDDE framework can utilize observational data to perform precise estimation of single or multiple delay parameters. The results of multiple numerical experiments have shown that NDDEs demonstrate high precision in both forward and inverse problems, proving their effectiveness and promising potential in dealing with delayed differential equation issues.
SCSA: Exploring the Synergistic Effects Between Spatial and Channel Attention
Jul 06, 2024Channel and spatial attentions have respectively brought significant improvements in extracting feature dependencies and spatial structure relations for various downstream vision tasks. While their combination is more beneficial for leveraging their individual strengths, the synergy between channel and spatial attentions has not been fully explored, lacking in fully harness the synergistic potential of multi-semantic information for feature guidance and mitigation of semantic disparities. Our study attempts to reveal the synergistic relationship between spatial and channel attention at multiple semantic levels, proposing a novel Spatial and Channel Synergistic Attention module (SCSA). Our SCSA consists of two parts: the Shareable Multi-Semantic Spatial Attention (SMSA) and the Progressive Channel-wise Self-Attention (PCSA). SMSA integrates multi-semantic information and utilizes a progressive compression strategy to inject discriminative spatial priors into PCSA's channel self-attention, effectively guiding channel recalibration. Additionally, the robust feature interactions based on the self-attention mechanism in PCSA further mitigate the disparities in multi-semantic information among different sub-features within SMSA. We conduct extensive experiments on seven benchmark datasets, including classification on ImageNet-1K, object detection on MSCOCO 2017, segmentation on ADE20K, and four other complex scene detection datasets. Our results demonstrate that our proposed SCSA not only surpasses the current state-of-the-art attention but also exhibits enhanced generalization capabilities across various task scenarios. The code and models are available at: https://github.com/HZAI-ZJNU/SCSA.
Combining Optimal Transport and Embedding-Based Approaches for More Expressiveness in Unsupervised Graph Alignment
Jun 19, 2024



Unsupervised graph alignment finds the one-to-one node correspondence between a pair of attributed graphs by only exploiting graph structure and node features. One category of existing works first computes the node representation and then matches nodes with close embeddings, which is intuitive but lacks a clear objective tailored for graph alignment in the unsupervised setting. The other category reduces the problem to optimal transport (OT) via Gromov-Wasserstein (GW) learning with a well-defined objective but leaves a large room for exploring the design of transport cost. We propose a principled approach to combine their advantages motivated by theoretical analysis of model expressiveness. By noticing the limitation of discriminative power in separating matched and unmatched node pairs, we improve the cost design of GW learning with feature transformation, which enables feature interaction across dimensions. Besides, we propose a simple yet effective embedding-based heuristic inspired by the Weisfeiler-Lehman test and add its prior knowledge to OT for more expressiveness when handling non-Euclidean data. Moreover, we are the first to guarantee the one-to-one matching constraint by reducing the problem to maximum weight matching. The algorithm design effectively combines our OT and embedding-based predictions via stacking, an ensemble learning strategy. We propose a model framework named \texttt{CombAlign} integrating all the above modules to refine node alignment progressively. Through extensive experiments, we demonstrate significant improvements in alignment accuracy compared to state-of-the-art approaches and validate the effectiveness of the proposed modules.