 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwenCLIP: Boosting Medical Vision-Language Pretraining via LLM Embeddings and Prompt tuning
Nov 17, 2025Contrastive Language-Image Pretraining (CLIP) has demonstrated strong generalization for vision-language tasks in computer vision and medical domains, yet its text encoder accepts only up to 77 tokens, which limits its ability to represent long and information-rich radiology reports. Recent adaptations using domain-specific encoders, such as PubMedBERT or ClinicalBERT, mitigate this issue by leveraging medical corpora, but remain constrained by their limited input length (typically 512 tokens) and relatively shallow semantic understanding. To address these limitations, we propose QwenCLIP, a vision-language framework that replaces CLIP's text encoder with a large language model (LLM)-based embedding module (e.g., Qwen3-Embedding) and introduces learnable prompts to enhance cross-modal alignment. By leveraging the extended context window and richer representations of LLMs, QwenCLIP captures comprehensive medical semantics from long-form clinical text, substantially improving medical image-text alignment and downstream performance on radiology benchmarks. Our code is publicly available at https://github.com/Wxy-24/QwenCLIP.
A Semantically-Aware Relevance Measure for Content-Based Medical Image Retrieval Evaluation
Jun 16, 2025Performance evaluation for Content-Based Image Retrieval (CBIR) remains a crucial but unsolved problem today especially in the medical domain. Various evaluation metrics have been discussed in the literature to solve this problem. Most of the existing metrics (e.g., precision, recall) are adapted from classification tasks which require manual labels as ground truth. However, such labels are often expensive and unavailable in specific thematic domains. Furthermore, medical images are usually associated with (radiological) case reports or annotated with descriptive captions in literature figures, such text contains information that can help to assess CBIR.Several researchers have argued that the medical concepts hidden in the text can serve as the basis for CBIR evaluation purpose. However, these works often consider these medical concepts as independent and isolated labels while in fact the subtle relationships between various concepts are neglected. In this work, we introduce the use of knowledge graphs to measure the distance between various medical concepts and propose a novel relevance measure for the evaluation of CBIR by defining an approximate matching-based relevance score between two sets of medical concepts which allows us to indirectly measure the similarity between medical images.We quantitatively demonstrate the effectiveness and feasibility of our relevance measure using a public dataset.
Visual Question Answering on Multiple Remote Sensing Image Modalities
May 21, 2025

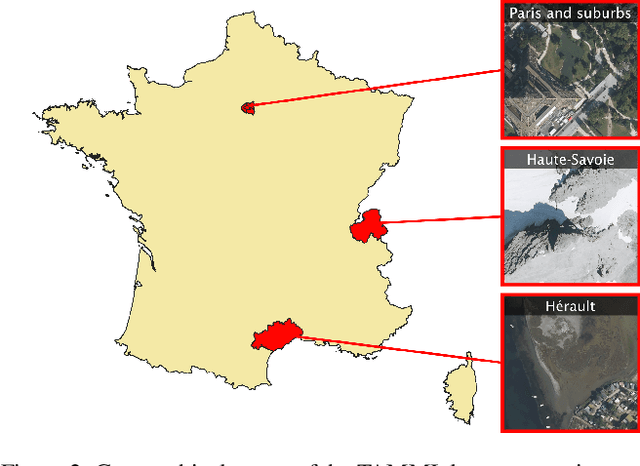

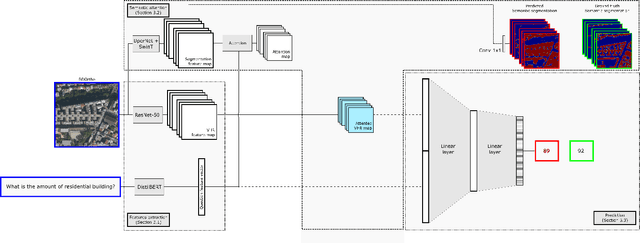
The extraction of visual features is an essential step in Visual Question Answering (VQA). Building a good visual representation of the analyzed scene is indeed one of the essential keys for the system to be able to correctly understand the latter in order to answer complex questions. In many fields such as remote sensing, the visual feature extraction step could benefit significantly from leveraging different image modalities carrying complementary spectral, spatial and contextual information. In this work, we propose to add multiple image modalities to VQA in the particular context of remote sensing, leading to a novel task for the computer vision community. To this end, we introduce a new VQA dataset, named TAMMI (Text and Multi-Modal Imagery) with diverse questions on scenes described by three different modalities (very high resolution RGB, multi-spectral imaging data and synthetic aperture radar). Thanks to an automated pipeline, this dataset can be easily extended according to experimental needs. We also propose the MM-RSVQA (Multi-modal Multi-resolution Remote Sensing Visual Question Answering) model, based on VisualBERT, a vision-language transformer, to effectively combine the multiple image modalities and text through a trainable fusion process. A preliminary experimental study shows promising results of our methodology on this challenging dataset, with an accuracy of 65.56% on the targeted VQA task. This pioneering work paves the way for the community to a new multi-modal multi-resolution VQA task that can be applied in other imaging domains (such as medical imaging) where multi-modality can enrich the visual representation of a scene. The dataset and code are available at https://tammi.sylvainlobry.com/.
An LLM Agent for Automatic Geospatial Data Analysis
Oct 24, 2024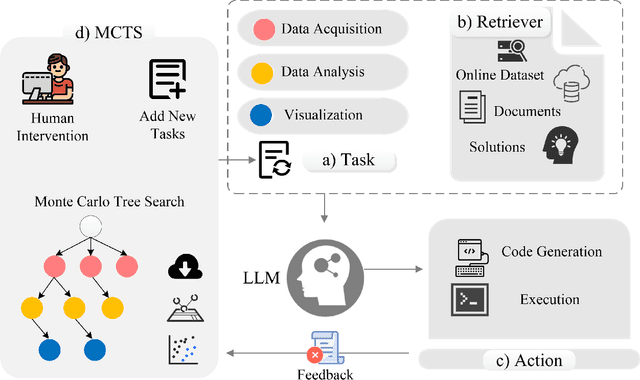

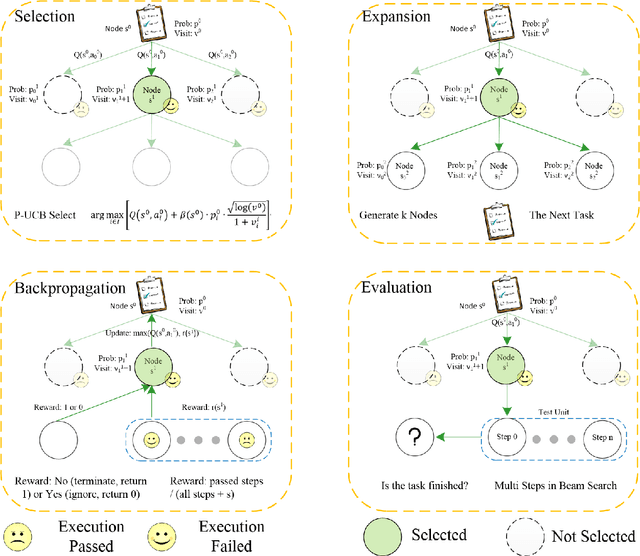
Large language models (LLMs) are being used in data science code generation tasks, but they often struggle with complex sequential tasks, leading to logical errors. Their application to geospatial data processing is particularly challenging due to difficulties in incorporating complex data structures and spatial constraints, effectively utilizing diverse function calls, and the tendency to hallucinate less-used geospatial libraries. To tackle these problems, we introduce GeoAgent, a new interactive framework designed to help LLMs handle geospatial data processing more effectively. GeoAgent pioneers the integration of a code interpreter, static analysis, and Retrieval-Augmented Generation (RAG) techniques within a Monte Carlo Tree Search (MCTS) algorithm, offering a novel approach to geospatial data processing. In addition, we contribute a new benchmark specifically designed to evaluate the LLM-based approach in geospatial tasks. This benchmark leverages a variety of Python libraries and includes both single-turn and multi-turn tasks such as data acquisition, data analysis, and visualization. By offering a comprehensive evaluation among diverse geospatial contexts, this benchmark sets a new standard for developing LLM-based approaches in geospatial data analysis tasks. Our findings suggest that relying solely on knowledge of LLM is insufficient for accurate geospatial task programming, which requires coherent multi-step processes and multiple function calls. Compared to the baseline LLMs, the proposed GeoAgent has demonstrated superior performance, yielding notable improvements in function calls and task completion. In addition, these results offer valuable insights for the future development of LLM agents in automatic geospatial data analysis task programming.
Lymphoid Infiltration Assessment of the Tumor Margins in H&E Slides
Jul 23, 2024



Lymphoid infiltration at tumor margins is a key prognostic marker in solid tumors, playing a crucial role in guiding immunotherapy decisions. Current assessment methods, heavily reliant on immunohistochemistry (IHC), face challenges in tumor margin delineation and are affected by tissue preservation conditions. In contrast, we propose a Hematoxylin and Eosin (H&E) staining-based approach, underpinned by an advanced lymphocyte segmentation model trained on a public dataset for the precise detection of CD3+ and CD20+ lymphocytes. In our colorectal cancer study, we demonstrate that our H&E-based method offers a compelling alternative to traditional IHC, achieving comparable results in many cases. Our method's validity is further explored through a Turing test, involving blinded assessments by a pathologist of anonymized curves from H&E and IHC slides. This approach invites the medical community to consider Turing tests as a standard for evaluating medical applications involving expert human evaluation, thereby opening new avenues for enhancing cancer management and immunotherapy planning.
Segmentation-guided Attention for Visual Question Answering from Remote Sensing Images
Jul 11, 2024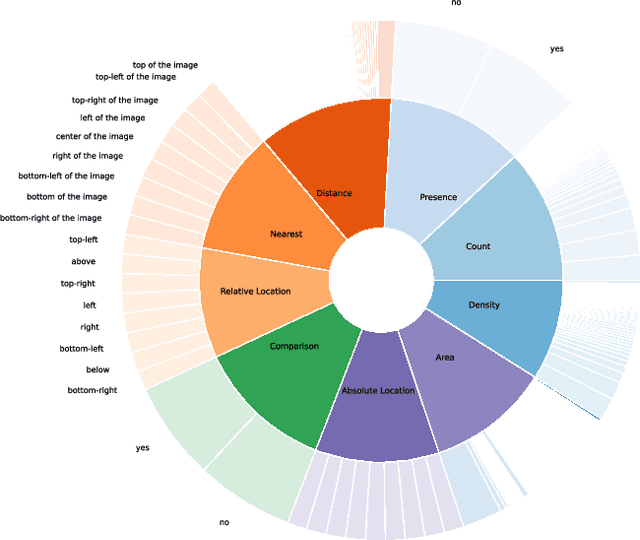


Visual Question Answering for Remote Sensing (RSVQA) is a task that aims at answering natural language questions about the content of a remote sensing image. The visual features extraction is therefore an essential step in a VQA pipeline. By incorporating attention mechanisms into this process, models gain the ability to focus selectively on salient regions of the image, prioritizing the most relevant visual information for a given question. In this work, we propose to embed an attention mechanism guided by segmentation into a RSVQA pipeline. We argue that segmentation plays a crucial role in guiding attention by providing a contextual understanding of the visual information, underlying specific objects or areas of interest. To evaluate this methodology, we provide a new VQA dataset that exploits very high-resolution RGB orthophotos annotated with 16 segmentation classes and question/answer pairs. Our study shows promising results of our new methodology, gaining almost 10% of overall accuracy compared to a classical method on the proposed dataset.
Optimizing Lymphocyte Detection in Breast Cancer Whole Slide Imaging through Data-Centric Strategies
May 22, 2024
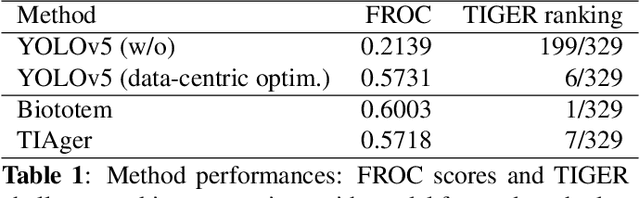


Efficient and precise quantification of lymphocytes in histopathology slides is imperative for the characterization of the tumor microenvironment and immunotherapy response insights. We developed a data-centric optimization pipeline that attain great lymphocyte detection performance using an off-the-shelf YOLOv5 model, without any architectural modifications. Our contribution that rely on strategic dataset augmentation strategies, includes novel biological upsampling and custom visual cohesion transformations tailored to the unique properties of tissue imagery, and enables to dramatically improve model performances. Our optimization reveals a pivotal realization: given intensive customization, standard computational pathology models can achieve high-capability biomarker development, without increasing the architectural complexity. We showcase the interest of this approach in the context of breast cancer where our strategies lead to good lymphocyte detection performances, echoing a broadly impactful paradigm shift. Furthermore, our data curation techniques enable crucial histological analysis benchmarks, highlighting improved generalizable potential.
A Hierarchical Transformer Encoder to Improve Entire Neoplasm Segmentation on Whole Slide Image of Hepatocellular Carcinoma
Jul 11, 2023



In digital histopathology, entire neoplasm segmentation on Whole Slide Image (WSI) of Hepatocellular Carcinoma (HCC) plays an important role, especially as a preprocessing filter to automatically exclude healthy tissue, in histological molecular correlations mining and other downstream histopathological tasks. The segmentation task remains challenging due to HCC's inherent high-heterogeneity and the lack of dependency learning in large field of view. In this article, we propose a novel deep learning architecture with a hierarchical Transformer encoder, HiTrans, to learn the global dependencies within expanded 4096$\times$4096 WSI patches. HiTrans is designed to encode and decode the patches with larger reception fields and the learned global dependencies, compared to the state-of-the-art Fully Convolutional Neural networks (FCNN). Empirical evaluations verified that HiTrans leads to better segmentation performance by taking into account regional and global dependency information.
Fine-tune your Classifier: Finding Correlations With Temperature
Oct 18, 2022


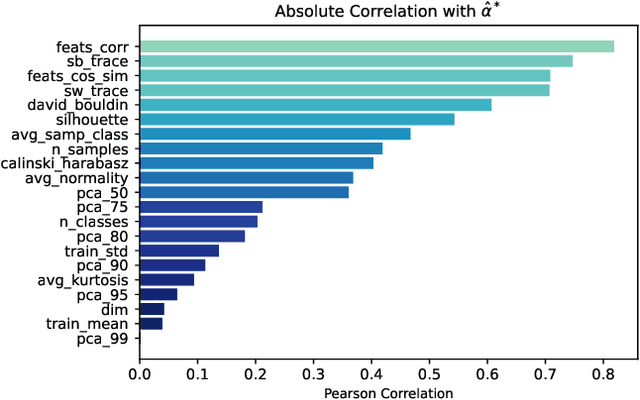
Temperature is a widely used hyperparameter in various tasks involving neural networks, such as classification or metric learning, whose choice can have a direct impact on the model performance. Most of existing works select its value using hyperparameter optimization methods requiring several runs to find the optimal value. We propose to analyze the impact of temperature on classification tasks by describing a dataset as a set of statistics computed on representations on which we can build a heuristic giving us a default value of temperature. We study the correlation between these extracted statistics and the observed optimal temperatures. This preliminary study on more than a hundred combinations of different datasets and features extractors highlights promising results towards the construction of a general heuristic for temperature.
Learning an Adaptation Function to Assess Image Visual Similarities
Jun 03, 2022



Human perception is routinely assessing the similarity between images, both for decision making and creative thinking. But the underlying cognitive process is not really well understood yet, hence difficult to be mimicked by computer vision systems. State-of-the-art approaches using deep architectures are often based on the comparison of images described as feature vectors learned for image categorization task. As a consequence, such features are powerful to compare semantically related images but not really efficient to compare images visually similar but semantically unrelated. Inspired by previous works on neural features adaptation to psycho-cognitive representations, we focus here on the specific task of learning visual image similarities when analogy matters. We propose to compare different supervised, semi-supervised and self-supervised networks, pre-trained on distinct scales and contents datasets (such as ImageNet-21k, ImageNet-1K or VGGFace2) to conclude which model may be the best to approximate the visual cortex and learn only an adaptation function corresponding to the approximation of the the primate IT cortex through the metric learning framework. Our experiments conducted on the Totally Looks Like image dataset highlight the interest of our method, by increasing the retrieval scores of the best model @1 by 2.25x. This research work was recently accepted for publication at the ICIP 2021 international conference [1]. In this new article, we expand on this previous work by using and comparing new pre-trained feature extractors on other datasets.