 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADIN: Souping on a Budget
Jan 31, 2024Model Soups, extending Stochastic Weights Averaging (SWA), combine models fine-tuned with different hyperparameters. Yet, their adoption is hindered by computational challenges due to subset selection issues. In this paper, we propose to speed up model soups by approximating soups performance using averaged ensemble logits performances. Theoretical insights validate the congruence between ensemble logits and weight averaging soups across any mixing ratios. Our Resource ADjusted soups craftINg (RADIN) procedure stands out by allowing flexible evaluation budgets, enabling users to adjust his budget of exploration adapted to his resources while increasing performance at lower budget compared to previous greedy approach (up to 4% on ImageNet).
Prompt Performance Prediction for Generative IR
Jun 15, 2023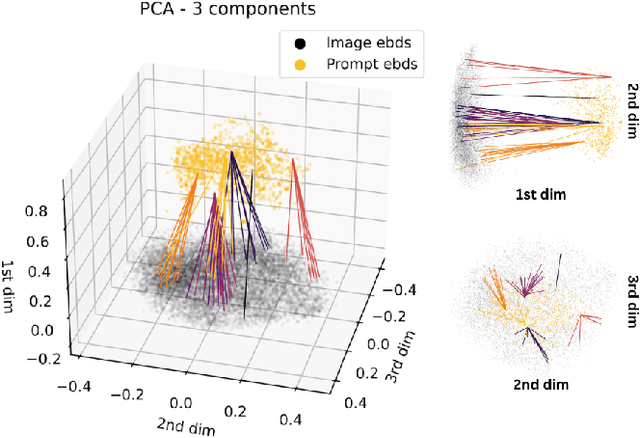

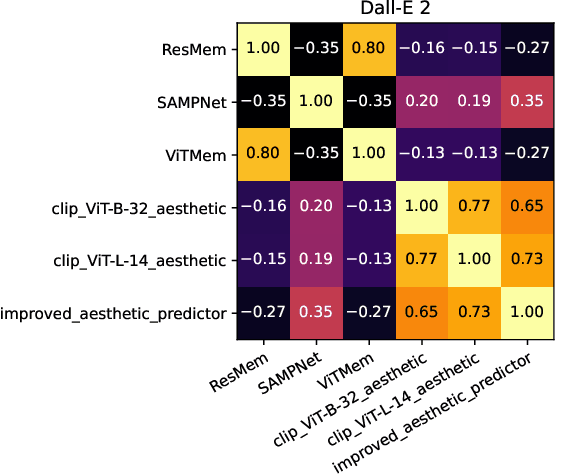
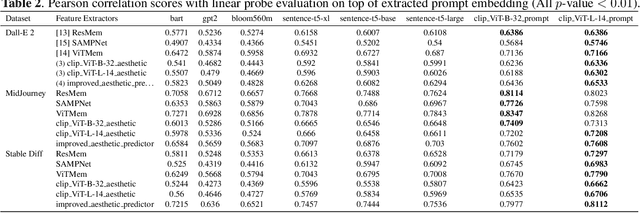
The ability to predict the performance of a query in Information Retrieval (IR) systems has been a longstanding challenge. In this paper, we introduce a novel task called "Prompt Performance Prediction" that aims to predict the performance of a query, referred to as a prompt, before obtaining the actual search results. The context of our task leverages a generative model as an IR engine to evaluate the prompts' performance on image retrieval tasks. We demonstrate the plausibility of our task by measuring the correlation coefficient between predicted and actual performance scores across three datasets containing pairs of prompts and generated images. Our results show promising performance prediction capabilities, suggesting potential applications for optimizing generative IR systems.
Fine-tune your Classifier: Finding Correlations With Temperature
Oct 18, 2022


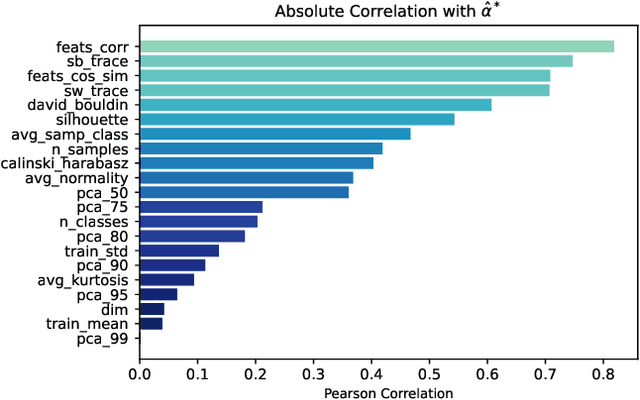
Temperature is a widely used hyperparameter in various tasks involving neural networks, such as classification or metric learning, whose choice can have a direct impact on the model performance. Most of existing works select its value using hyperparameter optimization methods requiring several runs to find the optimal value. We propose to analyze the impact of temperature on classification tasks by describing a dataset as a set of statistics computed on representations on which we can build a heuristic giving us a default value of temperature. We study the correlation between these extracted statistics and the observed optimal temperatures. This preliminary study on more than a hundred combinations of different datasets and features extractors highlights promising results towards the construction of a general heuristic for temperature.
What can we Learn by Predicting Accuracy?
Aug 02, 2022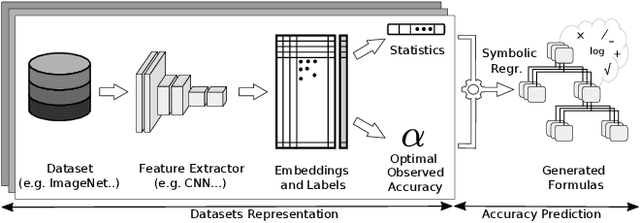
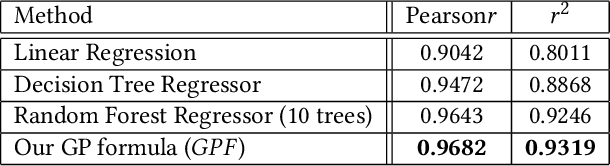
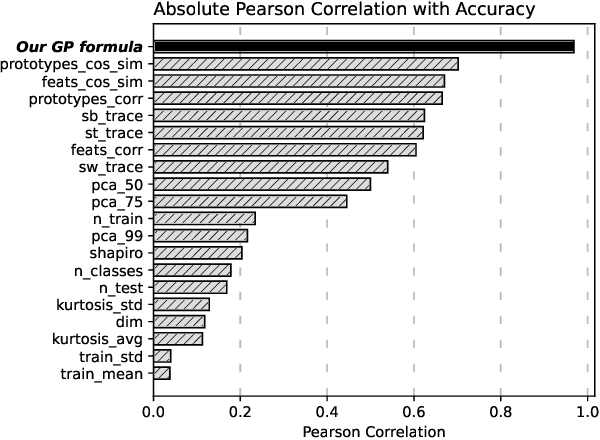
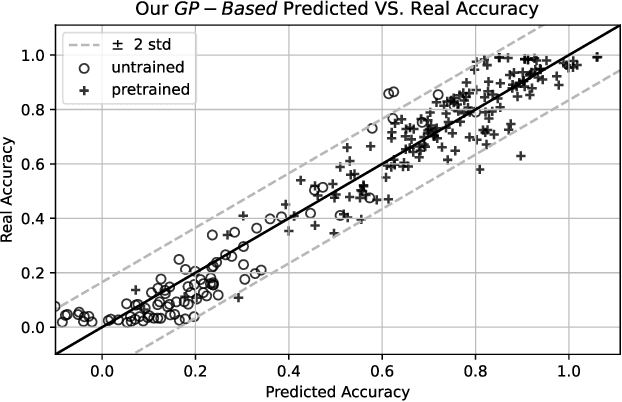
This paper seeks to answer the following question: "What can we learn by predicting accuracy?" Indeed, classification is one of the most popular task in machine learning and many loss functions have been developed to maximize this non-differentiable objective. Unlike past work on loss function design, which was mostly guided by intuition and theory before being validated by experimentation, here we propose to approach this problem in the opposite way : we seek to extract knowledge from experiments. This data-driven approach is similar to that used in physics to discover general laws from data. We used a symbolic regression method to automatically find a mathematical expression that is highly correlated with the accuracy of a linear classifier. The formula discovered on more than 260 datasets has a Pearson correlation of 0.96 and a r2 of 0.93. More interestingly, this formula is highly explainable and confirms insights from various previous papers on loss design. We hope this work will open new perspectives in the search for new heuristics leading to a deeper understanding of machine learning theory.
Learning an Adaptation Function to Assess Image Visual Similarities
Jun 03, 2022



Human perception is routinely assessing the similarity between images, both for decision making and creative thinking. But the underlying cognitive process is not really well understood yet, hence difficult to be mimicked by computer vision systems. State-of-the-art approaches using deep architectures are often based on the comparison of images described as feature vectors learned for image categorization task. As a consequence, such features are powerful to compare semantically related images but not really efficient to compare images visually similar but semantically unrelated. Inspired by previous works on neural features adaptation to psycho-cognitive representations, we focus here on the specific task of learning visual image similarities when analogy matters. We propose to compare different supervised, semi-supervised and self-supervised networks, pre-trained on distinct scales and contents datasets (such as ImageNet-21k, ImageNet-1K or VGGFace2) to conclude which model may be the best to approximate the visual cortex and learn only an adaptation function corresponding to the approximation of the the primate IT cortex through the metric learning framework. Our experiments conducted on the Totally Looks Like image dataset highlight the interest of our method, by increasing the retrieval scores of the best model @1 by 2.25x. This research work was recently accepted for publication at the ICIP 2021 international conference [1]. In this new article, we expand on this previous work by using and comparing new pre-trained feature extractors on other datasets.