 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytical Logit Scaling for High-Resolution Sea Ice Topology Retrieval from Weakly Labeled SAR Imagery
Mar 13, 2026High-resolution sea ice mapping using Synthetic Aperture Radar (SAR) is crucial for Arctic navigation and climate monitoring. However, operational ice charts provide only coarse, region-level polygons (weak labels), forcing automated segmentation models to struggle with pixel-level accuracy and often yielding under-confident, blurred concentration maps. In this paper, we propose a weakly supervised deep learning pipeline that fuses Sentinel-1 SAR and AMSR-2 radiometry data using a U-Net architecture trained with a region-based loss. To overcome the severe under-confidence caused by weak labels, we introduce an Analytical Logit Scaling method applied post-inference. By dynamically calculating the temperature and bias based on the latent space percentiles (2\% and 98\%) of each scene, we force a physical binarization of the predictions. This adaptive scaling acts as a topological extractor, successfully revealing fine-grained sea ice fractures (leads) at a 40-meter resolution without requiring any manual pixel-level annotations. Our approach not only resolves local topology but also perfectly preserves regional macroscopic concentrations, achieving a 78\% accuracy on highly fragmented summer scenes, thereby bridging the gap between weakly supervised learning and high-resolution physical segmentation.
Visual Question Answering on Multiple Remote Sensing Image Modalities
May 21, 2025

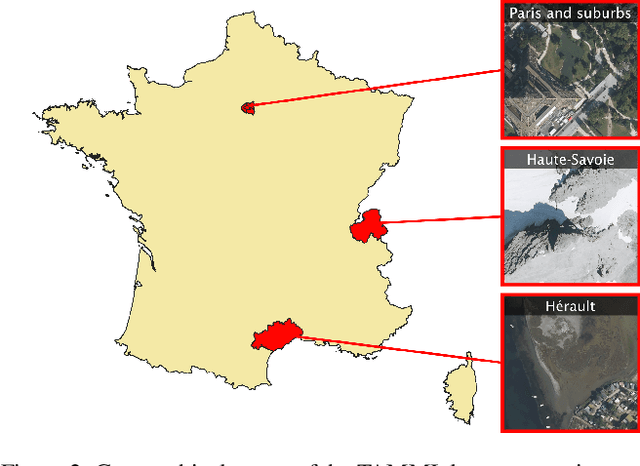

The extraction of visual features is an essential step in Visual Question Answering (VQA). Building a good visual representation of the analyzed scene is indeed one of the essential keys for the system to be able to correctly understand the latter in order to answer complex questions. In many fields such as remote sensing, the visual feature extraction step could benefit significantly from leveraging different image modalities carrying complementary spectral, spatial and contextual information. In this work, we propose to add multiple image modalities to VQA in the particular context of remote sensing, leading to a novel task for the computer vision community. To this end, we introduce a new VQA dataset, named TAMMI (Text and Multi-Modal Imagery) with diverse questions on scenes described by three different modalities (very high resolution RGB, multi-spectral imaging data and synthetic aperture radar). Thanks to an automated pipeline, this dataset can be easily extended according to experimental needs. We also propose the MM-RSVQA (Multi-modal Multi-resolution Remote Sensing Visual Question Answering) model, based on VisualBERT, a vision-language transformer, to effectively combine the multiple image modalities and text through a trainable fusion process. A preliminary experimental study shows promising results of our methodology on this challenging dataset, with an accuracy of 65.56% on the targeted VQA task. This pioneering work paves the way for the community to a new multi-modal multi-resolution VQA task that can be applied in other imaging domains (such as medical imaging) where multi-modality can enrich the visual representation of a scene. The dataset and code are available at https://tammi.sylvainlobry.com/.
SAR Strikes Back: A New Hope for RSVQA
Jan 14, 2025
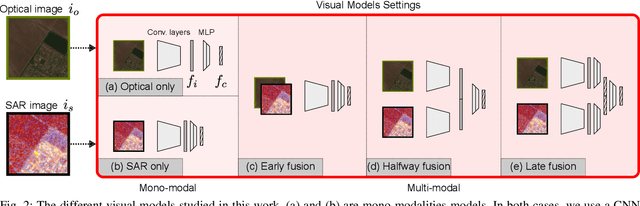


Remote sensing visual question answering (RSVQA) is a task that automatically extracts information from satellite images and processes a question to predict the answer from the images in textual form, helping with the interpretation of the image. While different methods have been proposed to extract information from optical images with different spectral bands and resolutions, no method has been proposed to answer questions from Synthetic Aperture Radar (SAR) images. SAR images capture electromagnetic information from the scene, and are less affected by atmospheric conditions, such as clouds. In this work, our objective is to introduce SAR in the RSVQA task, finding the best way to use this modality. In our research, we carry out a study on different pipelines for the task of RSVQA taking into account information from both SAR and optical data. To this purpose, we also present a dataset that allows for the introduction of SAR images in the RSVQA framework. We propose two different models to include the SAR modality. The first one is an end-to-end method in which we add an additional encoder for the SAR modality. In the second approach, we build on a two-stage framework. First, relevant information is extracted from SAR and, optionally, optical data. This information is then translated into natural language to be used in the second step which only relies on a language model to provide the answer. We find that the second pipeline allows us to obtain good results with SAR images alone. We then try various types of fusion methods to use SAR and optical images together, finding that a fusion at the decision level achieves the best results on the proposed dataset. We show that SAR data offers additional information when fused with the optical modality, particularly for questions related to specific land cover classes, such as water areas.
Can SAR improve RSVQA performance?
Aug 28, 2024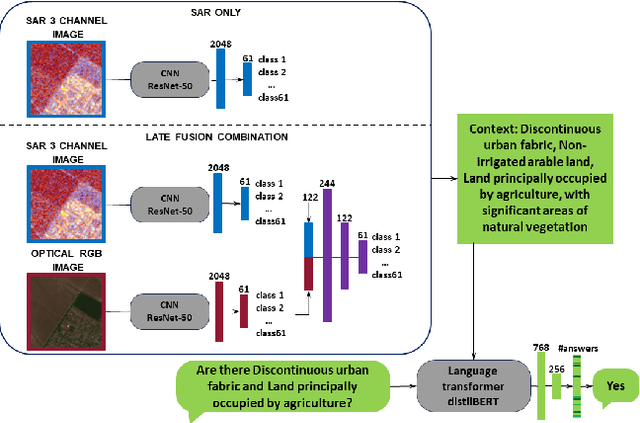



Remote sensing visual question answering (RSVQA) has been involved in several research in recent years, leading to an increase in new methods. RSVQA automatically extracts information from satellite images, so far only optical, and a question to automatically search for the answer in the image and provide it in a textual form. In our research, we study whether Synthetic Aperture Radar (SAR) images can be beneficial to this field. We divide our study into three phases which include classification methods and VQA. In the first one, we explore the classification results of SAR alone and investigate the best method to extract information from SAR data. Then, we study the combination of SAR and optical data. In the last phase, we investigate how SAR images and a combination of different modalities behave in RSVQA compared to a method only using optical images. We conclude that adding the SAR modality leads to improved performances, although further research on using SAR data to automatically answer questions is needed as well as more balanced datasets.
* 6 pages, 4 figures
Segmentation-guided Attention for Visual Question Answering from Remote Sensing Images
Jul 11, 2024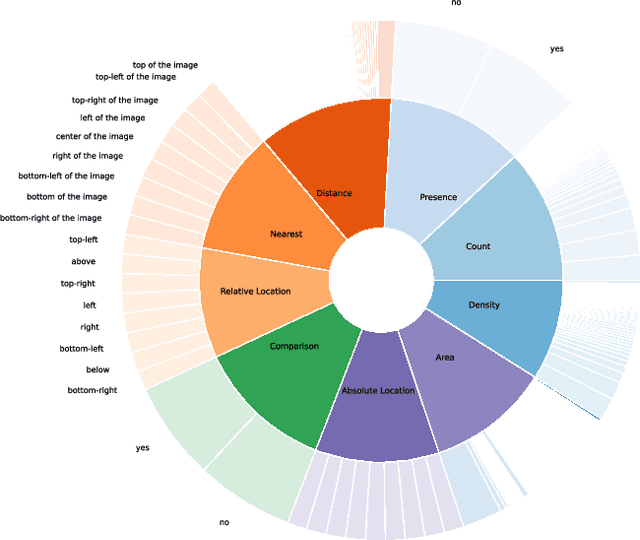

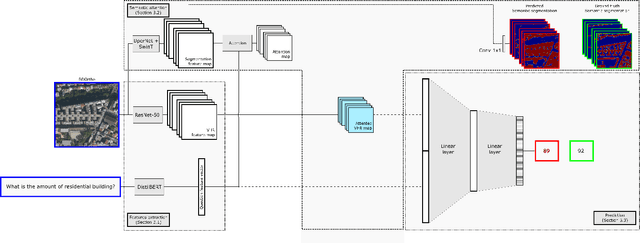

Visual Question Answering for Remote Sensing (RSVQA) is a task that aims at answering natural language questions about the content of a remote sensing image. The visual features extraction is therefore an essential step in a VQA pipeline. By incorporating attention mechanisms into this process, models gain the ability to focus selectively on salient regions of the image, prioritizing the most relevant visual information for a given question. In this work, we propose to embed an attention mechanism guided by segmentation into a RSVQA pipeline. We argue that segmentation plays a crucial role in guiding attention by providing a contextual understanding of the visual information, underlying specific objects or areas of interest. To evaluate this methodology, we provide a new VQA dataset that exploits very high-resolution RGB orthophotos annotated with 16 segmentation classes and question/answer pairs. Our study shows promising results of our new methodology, gaining almost 10% of overall accuracy compared to a classical method on the proposed dataset.