 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroundSet: A Cadastral-Grounded Dataset for Spatial Understanding with Vector Data
Mar 15, 2026Precise spatial understanding in Earth Observation is essential for translating raw aerial imagery into actionable insights for critical applications like urban planning, environmental monitoring and disaster management. However, Multimodal Large Language Models exhibit critical deficiencies in fine-grained spatial understanding within Remote Sensing, primarily due to a reliance on limited or repurposed legacy datasets. To bridge this gap, we introduce a large-scale dataset grounded in verifiable cadastral vector data, comprising 3.8 million annotated objects across 510k high-resolution images with 135 granular semantic categories. We validate this resource through a comprehensive instruction-tuning benchmark spanning seven spatial reasoning tasks. Our evaluation establishes a robust baseline using a standard LLaVA architecture. We show that while current RS-specialized and commercial models (e.g., Gemini) struggle in zero-shot settings, high-fidelity supervision effectively bridges this gap, enabling standard architectures to master fine-grained spatial grounding without complex architectural modifications.
IC-EO: Interpretable Code-based assistant for Earth Observation
Jan 27, 2026Despite recent advances in computer vision, Earth Observation (EO) analysis remains difficult to perform for the laymen, requiring expert knowledge and technical capabilities. Furthermore, many systems return black-box predictions that are difficult to audit or reproduce. Leveraging recent advances in tool LLMs, this study proposes a conversational, code-generating agent that transforms natural-language queries into executable, auditable Python workflows. The agent operates over a unified easily extendable API for classification, segmentation, detection (oriented bounding boxes), spectral indices, and geospatial operators. With our proposed framework, it is possible to control the results at three levels: (i) tool-level performance on public EO benchmarks; (ii) at the agent-level to understand the capacity to generate valid, hallucination-free code; and (iii) at the task-level on specific use cases. In this work, we select two use-cases of interest: land-composition mapping and post-wildfire damage assessment. The proposed agent outperforms general-purpose LLM/VLM baselines (GPT-4o, LLaVA), achieving 64.2% vs. 51.7% accuracy on land-composition and 50% vs. 0% on post-wildfire analysis, while producing results that are transparent and easy to interpret. By outputting verifiable code, the approach turns EO analysis into a transparent, reproducible process.
Atomizer: Generalizing to new modalities by breaking satellite images down to a set of scalars
Jun 16, 2025The growing number of Earth observation satellites has led to increasingly diverse remote sensing data, with varying spatial, spectral, and temporal configurations. Most existing models rely on fixed input formats and modality-specific encoders, which require retraining when new configurations are introduced, limiting their ability to generalize across modalities. We introduce Atomizer, a flexible architecture that represents remote sensing images as sets of scalars, each corresponding to a spectral band value of a pixel. Each scalar is enriched with contextual metadata (acquisition time, spatial resolution, wavelength, and bandwidth), producing an atomic representation that allows a single encoder to process arbitrary modalities without interpolation or resampling. Atomizer uses structured tokenization with Fourier features and non-uniform radial basis functions to encode content and context, and maps tokens into a latent space via cross-attention. Under modality-disjoint evaluations, Atomizer outperforms standard models and demonstrates robust performance across varying resolutions and spatial sizes.
Visual Question Answering on Multiple Remote Sensing Image Modalities
May 21, 2025

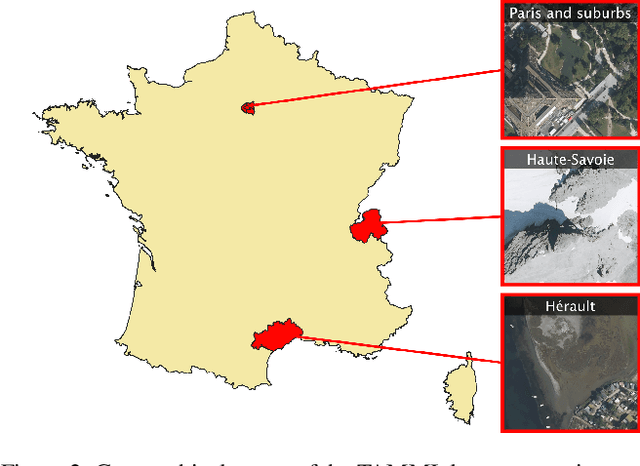

The extraction of visual features is an essential step in Visual Question Answering (VQA). Building a good visual representation of the analyzed scene is indeed one of the essential keys for the system to be able to correctly understand the latter in order to answer complex questions. In many fields such as remote sensing, the visual feature extraction step could benefit significantly from leveraging different image modalities carrying complementary spectral, spatial and contextual information. In this work, we propose to add multiple image modalities to VQA in the particular context of remote sensing, leading to a novel task for the computer vision community. To this end, we introduce a new VQA dataset, named TAMMI (Text and Multi-Modal Imagery) with diverse questions on scenes described by three different modalities (very high resolution RGB, multi-spectral imaging data and synthetic aperture radar). Thanks to an automated pipeline, this dataset can be easily extended according to experimental needs. We also propose the MM-RSVQA (Multi-modal Multi-resolution Remote Sensing Visual Question Answering) model, based on VisualBERT, a vision-language transformer, to effectively combine the multiple image modalities and text through a trainable fusion process. A preliminary experimental study shows promising results of our methodology on this challenging dataset, with an accuracy of 65.56% on the targeted VQA task. This pioneering work paves the way for the community to a new multi-modal multi-resolution VQA task that can be applied in other imaging domains (such as medical imaging) where multi-modality can enrich the visual representation of a scene. The dataset and code are available at https://tammi.sylvainlobry.com/.
SAR Strikes Back: A New Hope for RSVQA
Jan 14, 2025
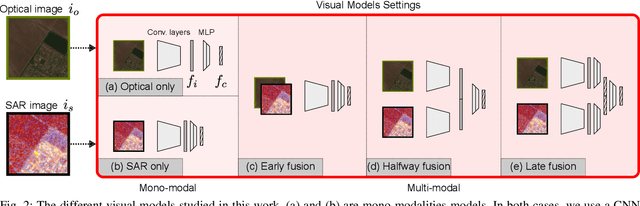


Remote sensing visual question answering (RSVQA) is a task that automatically extracts information from satellite images and processes a question to predict the answer from the images in textual form, helping with the interpretation of the image. While different methods have been proposed to extract information from optical images with different spectral bands and resolutions, no method has been proposed to answer questions from Synthetic Aperture Radar (SAR) images. SAR images capture electromagnetic information from the scene, and are less affected by atmospheric conditions, such as clouds. In this work, our objective is to introduce SAR in the RSVQA task, finding the best way to use this modality. In our research, we carry out a study on different pipelines for the task of RSVQA taking into account information from both SAR and optical data. To this purpose, we also present a dataset that allows for the introduction of SAR images in the RSVQA framework. We propose two different models to include the SAR modality. The first one is an end-to-end method in which we add an additional encoder for the SAR modality. In the second approach, we build on a two-stage framework. First, relevant information is extracted from SAR and, optionally, optical data. This information is then translated into natural language to be used in the second step which only relies on a language model to provide the answer. We find that the second pipeline allows us to obtain good results with SAR images alone. We then try various types of fusion methods to use SAR and optical images together, finding that a fusion at the decision level achieves the best results on the proposed dataset. We show that SAR data offers additional information when fused with the optical modality, particularly for questions related to specific land cover classes, such as water areas.
An LLM Agent for Automatic Geospatial Data Analysis
Oct 24, 2024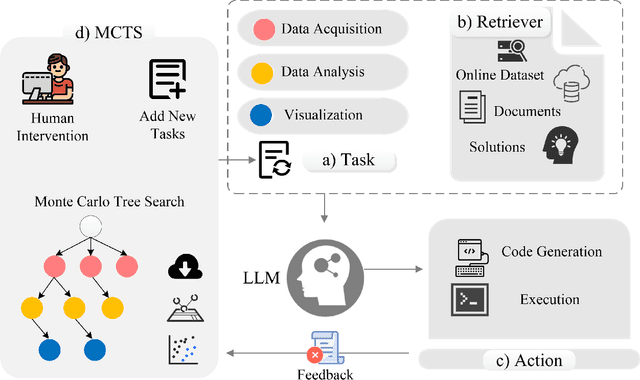
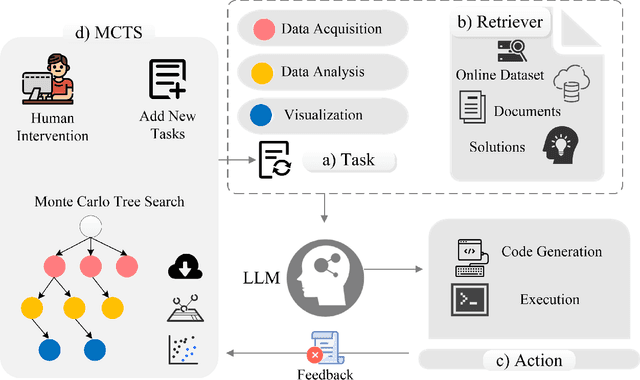

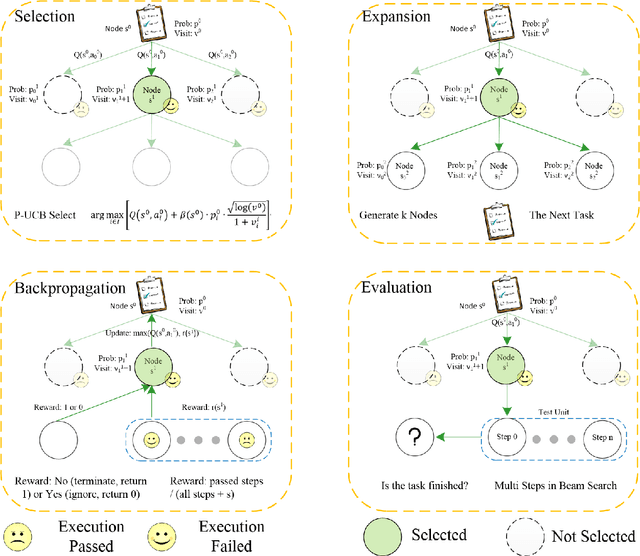
Large language models (LLMs) are being used in data science code generation tasks, but they often struggle with complex sequential tasks, leading to logical errors. Their application to geospatial data processing is particularly challenging due to difficulties in incorporating complex data structures and spatial constraints, effectively utilizing diverse function calls, and the tendency to hallucinate less-used geospatial libraries. To tackle these problems, we introduce GeoAgent, a new interactive framework designed to help LLMs handle geospatial data processing more effectively. GeoAgent pioneers the integration of a code interpreter, static analysis, and Retrieval-Augmented Generation (RAG) techniques within a Monte Carlo Tree Search (MCTS) algorithm, offering a novel approach to geospatial data processing. In addition, we contribute a new benchmark specifically designed to evaluate the LLM-based approach in geospatial tasks. This benchmark leverages a variety of Python libraries and includes both single-turn and multi-turn tasks such as data acquisition, data analysis, and visualization. By offering a comprehensive evaluation among diverse geospatial contexts, this benchmark sets a new standard for developing LLM-based approaches in geospatial data analysis tasks. Our findings suggest that relying solely on knowledge of LLM is insufficient for accurate geospatial task programming, which requires coherent multi-step processes and multiple function calls. Compared to the baseline LLMs, the proposed GeoAgent has demonstrated superior performance, yielding notable improvements in function calls and task completion. In addition, these results offer valuable insights for the future development of LLM agents in automatic geospatial data analysis task programming.
Can SAR improve RSVQA performance?
Aug 28, 2024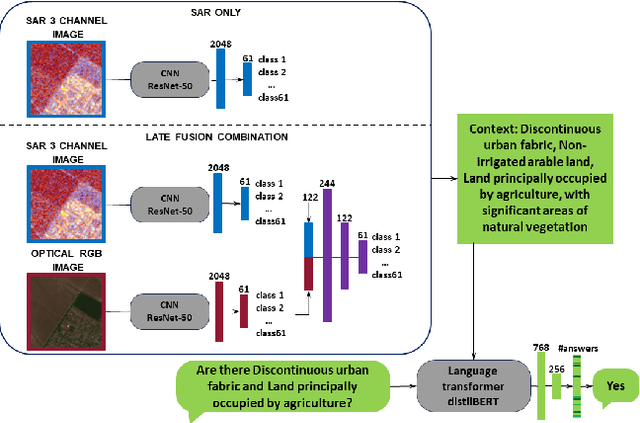



Remote sensing visual question answering (RSVQA) has been involved in several research in recent years, leading to an increase in new methods. RSVQA automatically extracts information from satellite images, so far only optical, and a question to automatically search for the answer in the image and provide it in a textual form. In our research, we study whether Synthetic Aperture Radar (SAR) images can be beneficial to this field. We divide our study into three phases which include classification methods and VQA. In the first one, we explore the classification results of SAR alone and investigate the best method to extract information from SAR data. Then, we study the combination of SAR and optical data. In the last phase, we investigate how SAR images and a combination of different modalities behave in RSVQA compared to a method only using optical images. We conclude that adding the SAR modality leads to improved performances, although further research on using SAR data to automatically answer questions is needed as well as more balanced datasets.
* 6 pages, 4 figures
Segmentation-guided Attention for Visual Question Answering from Remote Sensing Images
Jul 11, 2024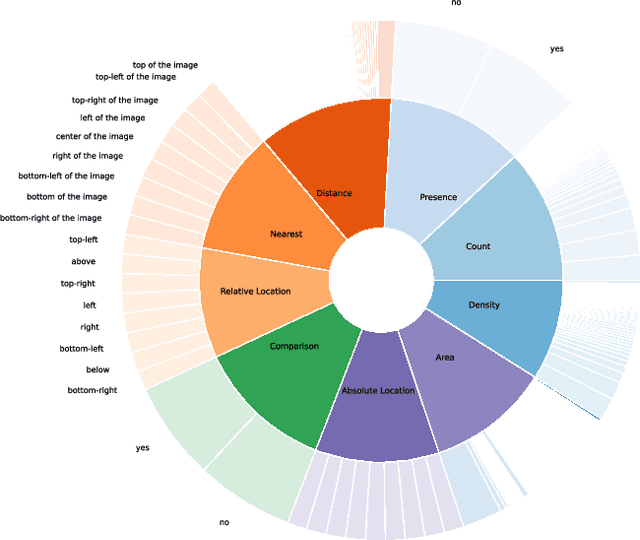

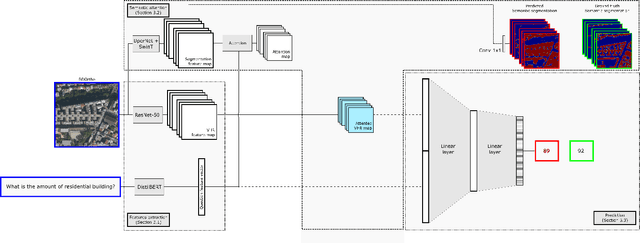

Visual Question Answering for Remote Sensing (RSVQA) is a task that aims at answering natural language questions about the content of a remote sensing image. The visual features extraction is therefore an essential step in a VQA pipeline. By incorporating attention mechanisms into this process, models gain the ability to focus selectively on salient regions of the image, prioritizing the most relevant visual information for a given question. In this work, we propose to embed an attention mechanism guided by segmentation into a RSVQA pipeline. We argue that segmentation plays a crucial role in guiding attention by providing a contextual understanding of the visual information, underlying specific objects or areas of interest. To evaluate this methodology, we provide a new VQA dataset that exploits very high-resolution RGB orthophotos annotated with 16 segmentation classes and question/answer pairs. Our study shows promising results of our new methodology, gaining almost 10% of overall accuracy compared to a classical method on the proposed dataset.
The curse of language biases in remote sensing VQA: the role of spatial attributes, language diversity, and the need for clear evaluation
Nov 28, 2023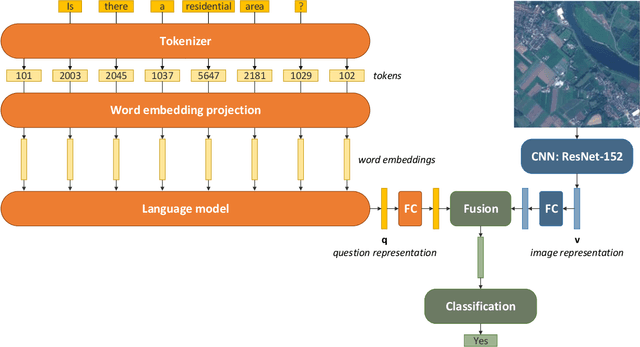

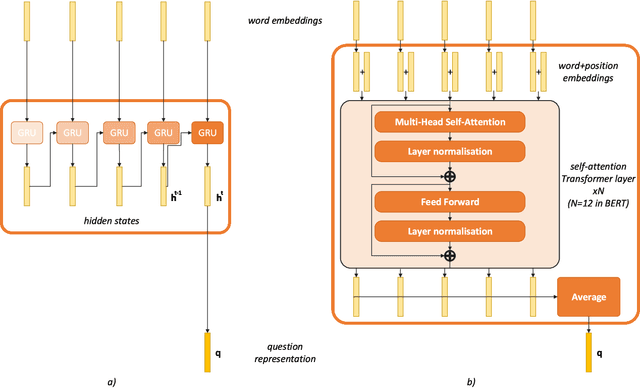

Remote sensing visual question answering (RSVQA) opens new opportunities for the use of overhead imagery by the general public, by enabling human-machine interaction with natural language. Building on the recent advances in natural language processing and computer vision, the goal of RSVQA is to answer a question formulated in natural language about a remote sensing image. Language understanding is essential to the success of the task, but has not yet been thoroughly examined in RSVQA. In particular, the problem of language biases is often overlooked in the remote sensing community, which can impact model robustness and lead to wrong conclusions about the performances of the model. Thus, the present work aims at highlighting the problem of language biases in RSVQA with a threefold analysis strategy: visual blind models, adversarial testing and dataset analysis. This analysis focuses both on model and data. Moreover, we motivate the use of more informative and complementary evaluation metrics sensitive to the issue. The gravity of language biases in RSVQA is then exposed for all of these methods with the training of models discarding the image data and the manipulation of the visual input during inference. Finally, a detailed analysis of question-answer distribution demonstrates the root of the problem in the data itself. Thanks to this analytical study, we observed that biases in remote sensing are more severe than in standard VQA, likely due to the specifics of existing remote sensing datasets for the task, e.g. geographical similarities and sparsity, as well as a simpler vocabulary and question generation strategies. While new, improved and less-biased datasets appear as a necessity for the development of the promising field of RSVQA, we demonstrate that more informed, relative evaluation metrics remain much needed to transparently communicate results of future RSVQA methods.
Deep learning for classification of noisy QR codes
Jul 20, 2023
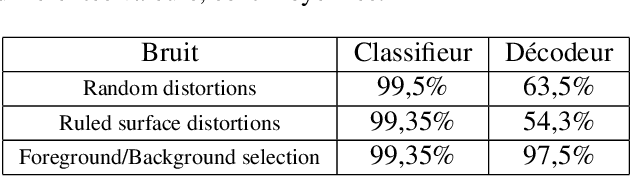


We wish to define the limits of a classical classification model based on deep learning when applied to abstract images, which do not represent visually identifiable objects.QR codes (Quick Response codes) fall into this category of abstract images: one bit corresponding to one encoded character, QR codes were not designed to be decoded manually. To understand the limitations of a deep learning-based model for abstract image classification, we train an image classification model on QR codes generated from information obtained when reading a health pass. We compare a classification model with a classical (deterministic) decoding method in the presence of noise. This study allows us to conclude that a model based on deep learning can be relevant for the understanding of abstract images.