 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetonymy in vision models undermines attention-based interpretability
May 07, 2026Part-based reasoning is a classical strategy to make a computer vision model directly focus on the object parts that are relevant to the downstream task. In the context of deep learning, this also serves to improve by-design interpretability, often by using part-centric attention mechanisms on top of a latent image representation provided by a standard, black-box model. This approach is based on a locality assumption: that the latent representation of an object part encodes primarily information about the corresponding image region. In this work, we test this basic assumption, measuring intra-object leakage in vision models using part-based attribute annotations. Through a comprehensive experimental evaluation, we show that modern pretrained vision transformers violate the locality assumption and exhibit a strong intra-object leakage, in which each part encodes information from the whole object, a visual metonymy that compromises the faithfulness of attention-based interpretable-by-design methods for part-based reasoning, ultimately rendering them uninterpretable. In addition, we establish an upper bound using a two-stage approach that prevents leakage by design. We then show that this inherently disentangled feature extraction improves attribute-driven part discovery on a variety of tasks, confirming the practical impact of intra-object leakage. Our results uncover a neglected issue affecting the interpretability of part-based representations, such as those in CBMs relying on part-centric concepts, highlighting that two-stage approaches offer a promising way to mitigate it.
Clarity: The Flexibility-Interpretability Trade-Off in Sparsity-aware Concept Bottleneck Models
Jan 29, 2026The widespread adoption of Vision-Language Models (VLMs) across fields has amplified concerns about model interpretability. Distressingly, these models are often treated as black-boxes, with limited or non-existent investigation of their decision making process. Despite numerous post- and ante-hoc interepretability methods, systematic and objective evaluation of the learned representations remains limited, particularly for sparsity-aware methods that are increasingly considered to "induce interpretability". In this work, we focus on Concept Bottleneck Models and investigate how different modeling decisions affect the emerging representations. We introduce the notion of clarity, a measure, capturing the interplay between the downstream performance and the sparsity and precision of the concept representation, while proposing an interpretability assessment framework using datasets with ground truth concept annotations. We consider both VLM- and attribute predictor-based CBMs, and three different sparsity-inducing strategies: per example $\ell_1, \ell_0$ and Bernoulli-based formulations. Our experiments reveal a critical trade-off between flexibility and interpretability, under which a given method can exhibit markedly different behaviors even at comparable performance levels. The code will be made publicly available upon publication.
Spatial Context Improves the Integration of Text with Remote Sensing for Mapping Environmental Variables
Jan 13, 2026Recent developments in natural language processing highlight text as an emerging data source for ecology. Textual resources carry unique information that can be used in complementarity with geospatial data sources, thus providing insights at the local scale into environmental conditions and properties hidden from more traditional data sources. Leveraging textual information in a spatial context presents several challenges. First, the contribution of textual data remains poorly defined in an ecological context, and it is unclear for which tasks it should be incorporated. Unlike ubiquitous satellite imagery or environmental covariates, the availability of textual data is sparse and irregular; its integration with geospatial data is not straightforward. In response to these challenges, this work proposes an attention-based approach that combines aerial imagery and geolocated text within a spatial neighbourhood, i.e. integrating contributions from several nearby observations. Our approach combines vision and text representations with a geolocation encoding, with an attention-based module that dynamically selects spatial neighbours that are useful for predictive tasks.The proposed approach is applied to the EcoWikiRS dataset, which combines high-resolution aerial imagery with sentences extracted from Wikipedia describing local environmental conditions across Switzerland. Our model is evaluated on the task of predicting 103 environmental variables from the SWECO25 data cube. Our approach consistently outperforms single-location or unimodal, i.e. image-only or text-only, baselines. When analysing variables by thematic groups, results show a significant improvement in performance for climatic, edaphic, population and land use/land cover variables, underscoring the benefit of including the spatial context when combining text and image data.
Atomizer: Generalizing to new modalities by breaking satellite images down to a set of scalars
Jun 16, 2025The growing number of Earth observation satellites has led to increasingly diverse remote sensing data, with varying spatial, spectral, and temporal configurations. Most existing models rely on fixed input formats and modality-specific encoders, which require retraining when new configurations are introduced, limiting their ability to generalize across modalities. We introduce Atomizer, a flexible architecture that represents remote sensing images as sets of scalars, each corresponding to a spectral band value of a pixel. Each scalar is enriched with contextual metadata (acquisition time, spatial resolution, wavelength, and bandwidth), producing an atomic representation that allows a single encoder to process arbitrary modalities without interpolation or resampling. Atomizer uses structured tokenization with Fourier features and non-uniform radial basis functions to encode content and context, and maps tokens into a latent space via cross-attention. Under modality-disjoint evaluations, Atomizer outperforms standard models and demonstrates robust performance across varying resolutions and spatial sizes.
Inherently Faithful Attention Maps for Vision Transformers
Jun 10, 2025We introduce an attention-based method that uses learned binary attention masks to ensure that only attended image regions influence the prediction. Context can strongly affect object perception, sometimes leading to biased representations, particularly when objects appear in out-of-distribution backgrounds. At the same time, many image-level object-centric tasks require identifying relevant regions, often requiring context. To address this conundrum, we propose a two-stage framework: stage 1 processes the full image to discover object parts and identify task-relevant regions, while stage 2 leverages input attention masking to restrict its receptive field to these regions, enabling a focused analysis while filtering out potentially spurious information. Both stages are trained jointly, allowing stage 2 to refine stage 1. Extensive experiments across diverse benchmarks demonstrate that our approach significantly improves robustness against spurious correlations and out-of-distribution backgrounds.
EcoWikiRS: Learning Ecological Representation of Satellite Images from Weak Supervision with Species Observations and Wikipedia
Apr 28, 2025The presence of species provides key insights into the ecological properties of a location such as land cover, climatic conditions or even soil properties. We propose a method to predict such ecological properties directly from remote sensing (RS) images by aligning them with species habitat descriptions. We introduce the EcoWikiRS dataset, consisting of high-resolution aerial images, the corresponding geolocated species observations, and, for each species, the textual descriptions of their habitat from Wikipedia. EcoWikiRS offers a scalable way of supervision for RS vision language models (RS-VLMs) for ecology. This is a setting with weak and noisy supervision, where, for instance, some text may describe properties that are specific only to part of the species' niche or is irrelevant to a specific image. We tackle this by proposing WINCEL, a weighted version of the InfoNCE loss. We evaluate our model on the task of ecosystem zero-shot classification by following the habitat definitions from the European Nature Information System (EUNIS). Our results show that our approach helps in understanding RS images in a more ecologically meaningful manner. The code and the dataset are available at https://github.com/eceo-epfl/EcoWikiRS.
Hybrid Phenology Modeling for Predicting Temperature Effects on Tree Dormancy
Jan 28, 2025Biophysical models offer valuable insights into climate-phenology relationships in both natural and agricultural settings. However, there are substantial structural discrepancies across models which require site-specific recalibration, often yielding inconsistent predictions under similar climate scenarios. Machine learning methods offer data-driven solutions, but often lack interpretability and alignment with existing knowledge. We present a phenology model describing dormancy in fruit trees, integrating conventional biophysical models with a neural network to address their structural disparities. We evaluate our hybrid model in an extensive case study predicting cherry tree phenology in Japan, South Korea and Switzerland. Our approach consistently outperforms both traditional biophysical and machine learning models in predicting blooming dates across years. Additionally, the neural network's adaptability facilitates parameter learning for specific tree varieties, enabling robust generalization to new sites without site-specific recalibration. This hybrid model leverages both biophysical constraints and data-driven flexibility, offering a promising avenue for accurate and interpretable phenology modeling.
Applying the maximum entropy principle to multi-species neural networks improves species distribution models
Dec 26, 2024



The rapid expansion of citizen science initiatives has led to a significant growth of biodiversity databases, and particularly presence-only (PO) observations. PO data are invaluable for understanding species distributions and their dynamics, but their use in Species Distribution Models (SDM) is curtailed by sampling biases and the lack of information on absences. Poisson point processes are widely used for SDMs, with Maxent being one of the most popular methods. Maxent maximises the entropy of a probability distribution across sites as a function of predefined transformations of environmental variables, called features. In contrast, neural networks and deep learning have emerged as a promising technique for automatic feature extraction from complex input variables. In this paper, we propose DeepMaxent, which harnesses neural networks to automatically learn shared features among species, using the maximum entropy principle. To do so, it employs a normalised Poisson loss where for each species, presence probabilities across sites are modelled by a neural network. We evaluate DeepMaxent on a benchmark dataset known for its spatial sampling biases, using PO data for calibration and presence-absence (PA) data for validation across six regions with different biological groups and environmental covariates. Our results indicate that DeepMaxent improves model performance over Maxent and other state-of-the-art SDMs across regions and taxonomic groups. The method performs particularly well in regions of uneven sampling, demonstrating substantial potential to improve species distribution modelling. The method opens the possibility to learn more robust environmental features predicting jointly many species and scales to arbitrary large numbers of sites without an increased memory demand.
SenCLIP: Enhancing zero-shot land-use mapping for Sentinel-2 with ground-level prompting
Dec 11, 2024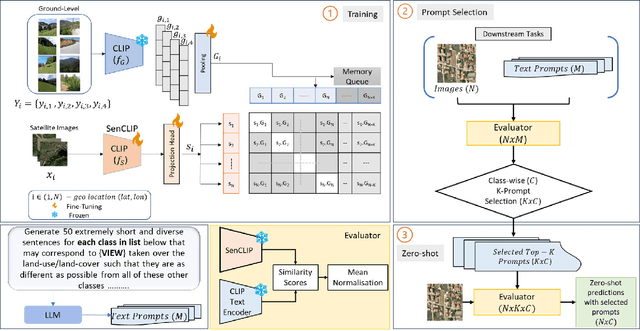
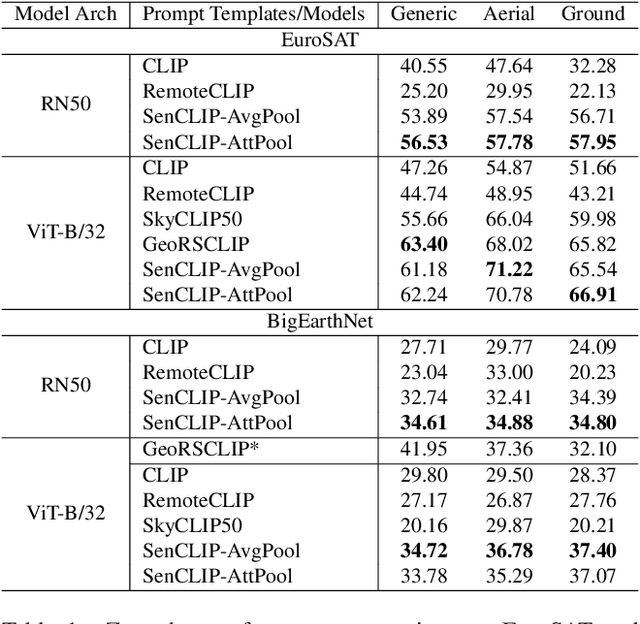
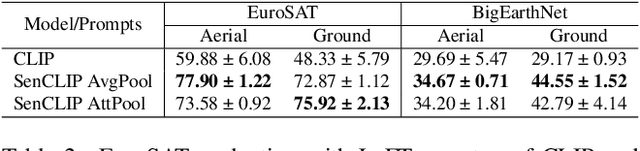
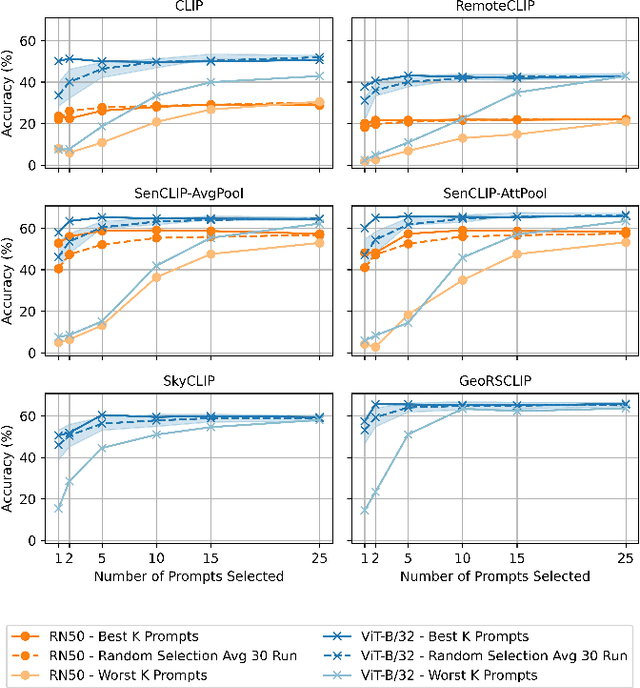
Pre-trained vision-language models (VLMs), such as CLIP, demonstrate impressive zero-shot classification capabilities with free-form prompts and even show some generalization in specialized domains. However, their performance on satellite imagery is limited due to the underrepresentation of such data in their training sets, which predominantly consist of ground-level images. Existing prompting techniques for satellite imagery are often restricted to generic phrases like a satellite image of ..., limiting their effectiveness for zero-shot land-use and land-cover (LULC) mapping. To address these challenges, we introduce SenCLIP, which transfers CLIPs representation to Sentinel-2 imagery by leveraging a large dataset of Sentinel-2 images paired with geotagged ground-level photos from across Europe. We evaluate SenCLIP alongside other SOTA remote sensing VLMs on zero-shot LULC mapping tasks using the EuroSAT and BigEarthNet datasets with both aerial and ground-level prompting styles. Our approach, which aligns ground-level representations with satellite imagery, demonstrates significant improvements in classification accuracy across both prompt styles, opening new possibilities for applying free-form textual descriptions in zero-shot LULC mapping.
Multi-Scale Grouped Prototypes for Interpretable Semantic Segmentation
Sep 14, 2024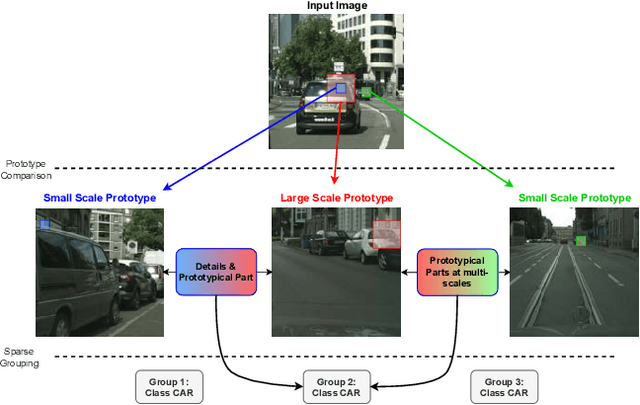
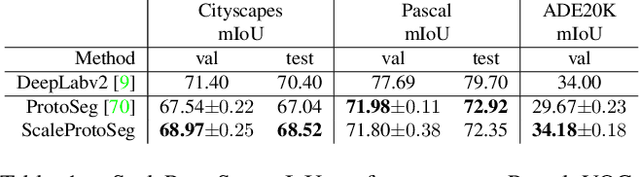
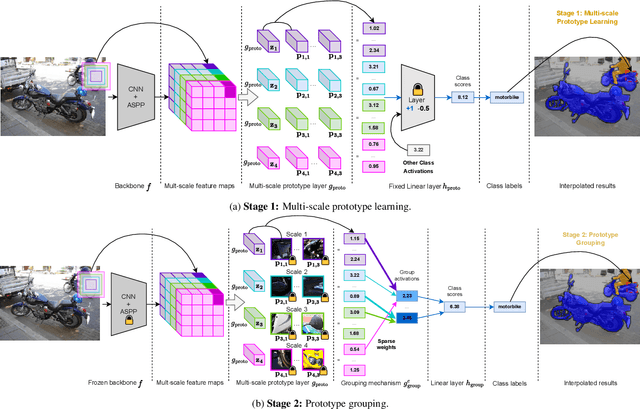

Prototypical part learning is emerging as a promising approach for making semantic segmentation interpretable. The model selects real patches seen during training as prototypes and constructs the dense prediction map based on the similarity between parts of the test image and the prototypes. This improves interpretability since the user can inspect the link between the predicted output and the patterns learned by the model in terms of prototypical information. In this paper, we propose a method for interpretable semantic segmentation that leverages multi-scale image representation for prototypical part learning. First, we introduce a prototype layer that explicitly learns diverse prototypical parts at several scales, leading to multi-scale representations in the prototype activation output. Then, we propose a sparse grouping mechanism that produces multi-scale sparse groups of these scale-specific prototypical parts. This provides a deeper understanding of the interactions between multi-scale object representations while enhancing the interpretability of the segmentation model. The experiments conducted on Pascal VOC, Cityscapes, and ADE20K demonstrate that the proposed method increases model sparsity, improves interpretability over existing prototype-based methods, and narrows the performance gap with the non-interpretable counterpart models. Code is available at github.com/eceo-epfl/ScaleProtoSeg.