 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInherently Faithful Attention Maps for Vision Transformers
Jun 10, 2025We introduce an attention-based method that uses learned binary attention masks to ensure that only attended image regions influence the prediction. Context can strongly affect object perception, sometimes leading to biased representations, particularly when objects appear in out-of-distribution backgrounds. At the same time, many image-level object-centric tasks require identifying relevant regions, often requiring context. To address this conundrum, we propose a two-stage framework: stage 1 processes the full image to discover object parts and identify task-relevant regions, while stage 2 leverages input attention masking to restrict its receptive field to these regions, enabling a focused analysis while filtering out potentially spurious information. Both stages are trained jointly, allowing stage 2 to refine stage 1. Extensive experiments across diverse benchmarks demonstrate that our approach significantly improves robustness against spurious correlations and out-of-distribution backgrounds.
Revisiting Cross-Modal Knowledge Distillation: A Disentanglement Approach for RGBD Semantic Segmentation
May 30, 2025Multi-modal RGB and Depth (RGBD) data are predominant in many domains such as robotics, autonomous driving and remote sensing. The combination of these multi-modal data enhances environmental perception by providing 3D spatial context, which is absent in standard RGB images. Although RGBD multi-modal data can be available to train computer vision models, accessing all sensor modalities during the inference stage may be infeasible due to sensor failures or resource constraints, leading to a mismatch between data modalities available during training and inference. Traditional Cross-Modal Knowledge Distillation (CMKD) frameworks, developed to address this task, are typically based on a teacher/student paradigm, where a multi-modal teacher distills knowledge into a single-modality student model. However, these approaches face challenges in teacher architecture choices and distillation process selection, thus limiting their adoption in real-world scenarios. To overcome these issues, we introduce CroDiNo-KD (Cross-Modal Disentanglement: a New Outlook on Knowledge Distillation), a novel cross-modal knowledge distillation framework for RGBD semantic segmentation. Our approach simultaneously learns single-modality RGB and Depth models by exploiting disentanglement representation, contrastive learning and decoupled data augmentation with the aim to structure the internal manifolds of neural network models through interaction and collaboration. We evaluated CroDiNo-KD on three RGBD datasets across diverse domains, considering recent CMKD frameworks as competitors. Our findings illustrate the quality of CroDiNo-KD, and they suggest reconsidering the conventional teacher/student paradigm to distill information from multi-modal data to single-modality neural networks.
Geographical Context Matters: Bridging Fine and Coarse Spatial Information to Enhance Continental Land Cover Mapping
Apr 16, 2025



Land use and land cover mapping from Earth Observation (EO) data is a critical tool for sustainable land and resource management. While advanced machine learning and deep learning algorithms excel at analyzing EO imagery data, they often overlook crucial geospatial metadata information that could enhance scalability and accuracy across regional, continental, and global scales. To address this limitation, we propose BRIDGE-LC (Bi-level Representation Integration for Disentangled GEospatial Land Cover), a novel deep learning framework that integrates multi-scale geospatial information into the land cover classification process. By simultaneously leveraging fine-grained (latitude/longitude) and coarse-grained (biogeographical region) spatial information, our lightweight multi-layer perceptron architecture learns from both during training but only requires fine-grained information for inference, allowing it to disentangle region-specific from region-agnostic land cover features while maintaining computational efficiency. To assess the quality of our framework, we use an open-access in-situ dataset and adopt several competing classification approaches commonly considered for large-scale land cover mapping. We evaluated all approaches through two scenarios: an extrapolation scenario in which training data encompasses samples from all biogeographical regions, and a leave-one-region-out scenario where one region is excluded from training. We also explore the spatial representation learned by our model, highlighting a connection between its internal manifold and the geographical information used during training. Our results demonstrate that integrating geospatial information improves land cover mapping performance, with the most substantial gains achieved by jointly leveraging both fine- and coarse-grained spatial information.
SenCLIP: Enhancing zero-shot land-use mapping for Sentinel-2 with ground-level prompting
Dec 11, 2024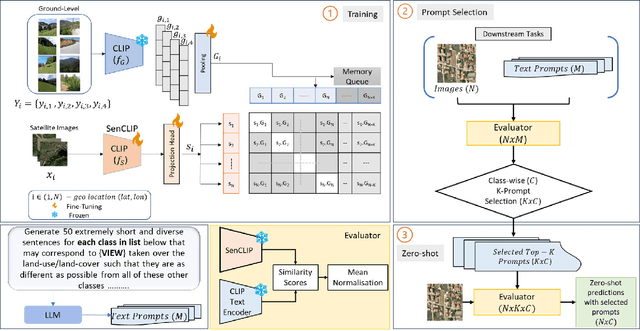
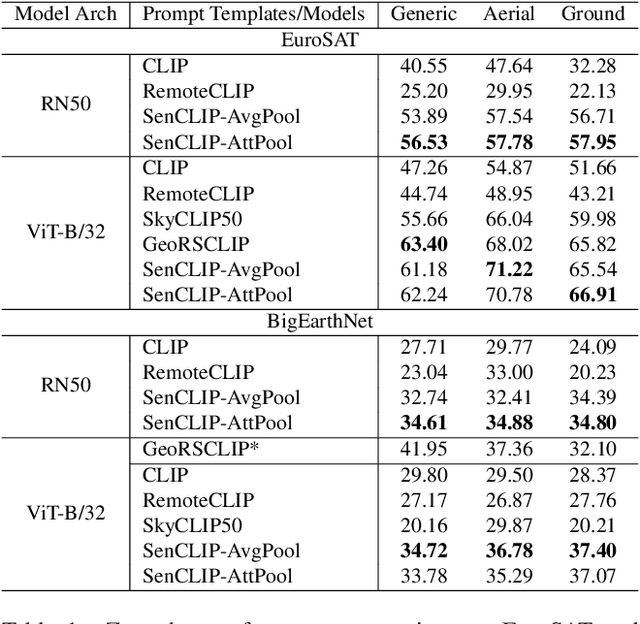
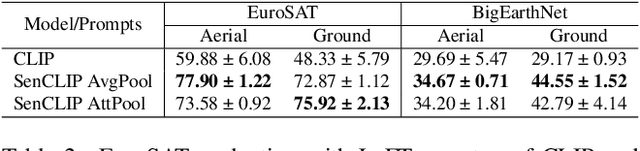
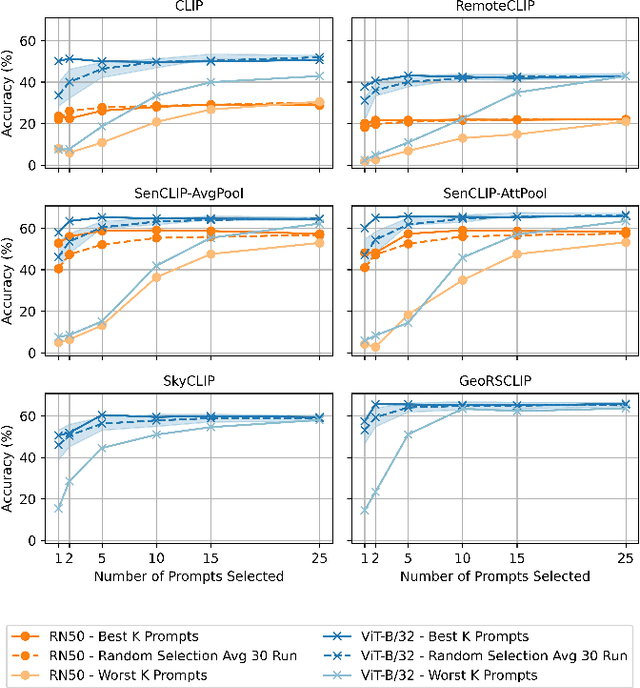
Pre-trained vision-language models (VLMs), such as CLIP, demonstrate impressive zero-shot classification capabilities with free-form prompts and even show some generalization in specialized domains. However, their performance on satellite imagery is limited due to the underrepresentation of such data in their training sets, which predominantly consist of ground-level images. Existing prompting techniques for satellite imagery are often restricted to generic phrases like a satellite image of ..., limiting their effectiveness for zero-shot land-use and land-cover (LULC) mapping. To address these challenges, we introduce SenCLIP, which transfers CLIPs representation to Sentinel-2 imagery by leveraging a large dataset of Sentinel-2 images paired with geotagged ground-level photos from across Europe. We evaluate SenCLIP alongside other SOTA remote sensing VLMs on zero-shot LULC mapping tasks using the EuroSAT and BigEarthNet datasets with both aerial and ground-level prompting styles. Our approach, which aligns ground-level representations with satellite imagery, demonstrates significant improvements in classification accuracy across both prompt styles, opening new possibilities for applying free-form textual descriptions in zero-shot LULC mapping.
DisCoM-KD: Cross-Modal Knowledge Distillation via Disentanglement Representation and Adversarial Learning
Aug 05, 2024



Cross-modal knowledge distillation (CMKD) refers to the scenario in which a learning framework must handle training and test data that exhibit a modality mismatch, more precisely, training and test data do not cover the same set of data modalities. Traditional approaches for CMKD are based on a teacher/student paradigm where a teacher is trained on multi-modal data with the aim to successively distill knowledge from a multi-modal teacher to a single-modal student. Despite the widespread adoption of such paradigm, recent research has highlighted its inherent limitations in the context of cross-modal knowledge transfer.Taking a step beyond the teacher/student paradigm, here we introduce a new framework for cross-modal knowledge distillation, named DisCoM-KD (Disentanglement-learning based Cross-Modal Knowledge Distillation), that explicitly models different types of per-modality information with the aim to transfer knowledge from multi-modal data to a single-modal classifier. To this end, DisCoM-KD effectively combines disentanglement representation learning with adversarial domain adaptation to simultaneously extract, foreach modality, domain-invariant, domain-informative and domain-irrelevant features according to a specific downstream task. Unlike the traditional teacher/student paradigm, our framework simultaneously learns all single-modal classifiers, eliminating the need to learn each student model separately as well as the teacher classifier. We evaluated DisCoM-KD on three standard multi-modal benchmarks and compared its behaviourwith recent SOTA knowledge distillation frameworks. The findings clearly demonstrate the effectiveness of DisCoM-KD over competitors considering mismatch scenarios involving both overlapping and non-overlapping modalities. These results offer insights to reconsider the traditional paradigm for distilling information from multi-modal data to single-modal neural networks.
PDiscoFormer: Relaxing Part Discovery Constraints with Vision Transformers
Jul 05, 2024Computer vision methods that explicitly detect object parts and reason on them are a step towards inherently interpretable models. Existing approaches that perform part discovery driven by a fine-grained classification task make very restrictive assumptions on the geometric properties of the discovered parts; they should be small and compact. Although this prior is useful in some cases, in this paper we show that pre-trained transformer-based vision models, such as self-supervised DINOv2 ViT, enable the relaxation of these constraints. In particular, we find that a total variation (TV) prior, which allows for multiple connected components of any size, substantially outperforms previous work. We test our approach on three fine-grained classification benchmarks: CUB, PartImageNet and Oxford Flowers, and compare our results to previously published methods as well as a re-implementation of the state-of-the-art method PDiscoNet with a transformer-based backbone. We consistently obtain substantial improvements across the board, both on part discovery metrics and the downstream classification task, showing that the strong inductive biases in self-supervised ViT models require to rethink the geometric priors that can be used for unsupervised part discovery.
Semi Supervised Heterogeneous Domain Adaptation via Disentanglement and Pseudo-Labelling
Jun 20, 2024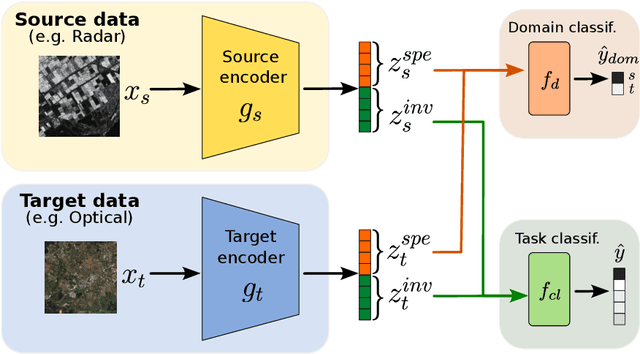

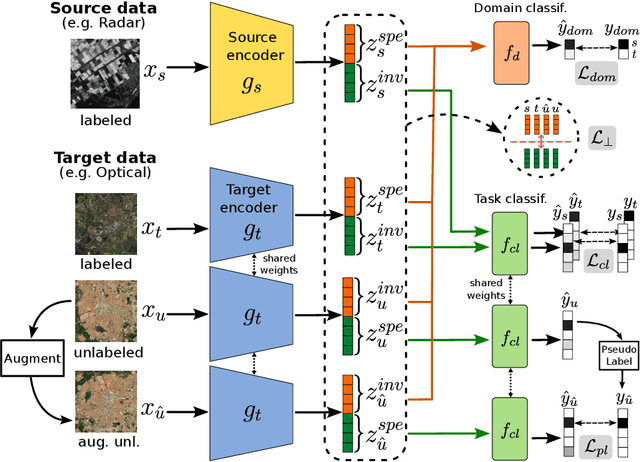
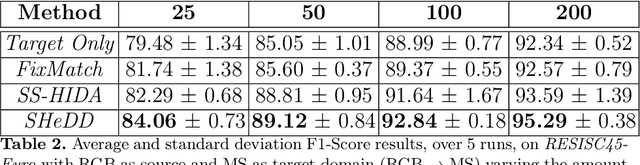
Semi-supervised domain adaptation methods leverage information from a source labelled domain with the goal of generalizing over a scarcely labelled target domain. While this setting already poses challenges due to potential distribution shifts between domains, an even more complex scenario arises when source and target data differs in modality representation (e.g. they are acquired by sensors with different characteristics). For instance, in remote sensing, images may be collected via various acquisition modes (e.g. optical or radar), different spectral characteristics (e.g. RGB or multi-spectral) and spatial resolutions. Such a setting is denoted as Semi-Supervised Heterogeneous Domain Adaptation (SSHDA) and it exhibits an even more severe distribution shift due to modality heterogeneity across domains.To cope with the challenging SSHDA setting, here we introduce SHeDD (Semi-supervised Heterogeneous Domain Adaptation via Disentanglement) an end-to-end neural framework tailored to learning a target domain classifier by leveraging both labelled and unlabelled data from heterogeneous data sources. SHeDD is designed to effectively disentangle domain-invariant representations, relevant for the downstream task, from domain-specific information, that can hinder the cross-modality transfer. Additionally, SHeDD adopts an augmentation-based consistency regularization mechanism that takes advantages of reliable pseudo-labels on the unlabelled target samples to further boost its generalization ability on the target domain. Empirical evaluations on two remote sensing benchmarks, encompassing heterogeneous data in terms of acquisition modes and spectral/spatial resolutions, demonstrate the quality of SHeDD compared to both baseline and state-of-the-art competing approaches. Our code is publicly available here: https://github.com/tanodino/SSHDA/
Towards a multimodal framework for remote sensing image change retrieval and captioning
Jun 19, 2024



Recently, there has been increasing interest in multimodal applications that integrate text with other modalities, such as images, audio and video, to facilitate natural language interactions with multimodal AI systems. While applications involving standard modalities have been extensively explored, there is still a lack of investigation into specific data modalities such as remote sensing (RS) data. Despite the numerous potential applications of RS data, including environmental protection, disaster monitoring and land planning, available solutions are predominantly focused on specific tasks like classification, captioning and retrieval. These solutions often overlook the unique characteristics of RS data, such as its capability to systematically provide information on the same geographical areas over time. This ability enables continuous monitoring of changes in the underlying landscape. To address this gap, we propose a novel foundation model for bi-temporal RS image pairs, in the context of change detection analysis, leveraging Contrastive Learning and the LEVIR-CC dataset for both captioning and text-image retrieval. By jointly training a contrastive encoder and captioning decoder, our model add text-image retrieval capabilities, in the context of bi-temporal change detection, while maintaining captioning performances that are comparable to the state of the art. We release the source code and pretrained weights at: https://github.com/rogerferrod/RSICRC.
Reuse out-of-year data to enhance land cover mappingvia feature disentanglement and contrastive learning
Apr 17, 2024


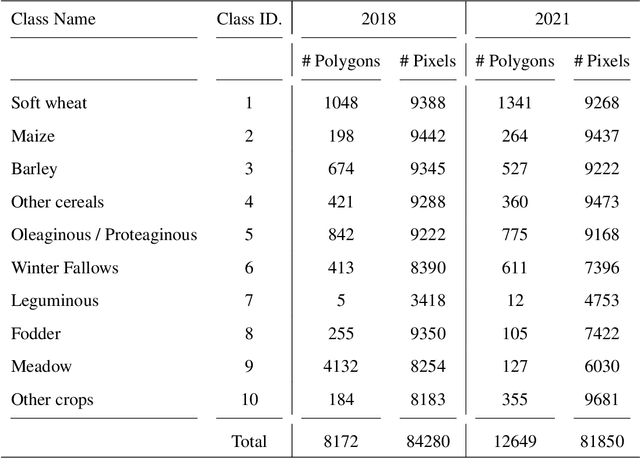
Timely up-to-date land use/land cover (LULC) maps play a pivotal role in supporting agricultural territory management, environmental monitoring and facilitating well-informed and sustainable decision-making. Typically, when creating a land cover (LC) map, precise ground truth data is collected through time-consuming and expensive field campaigns. This data is then utilized in conjunction with satellite image time series (SITS) through advanced machine learning algorithms to get the final map. Unfortunately, each time this process is repeated (e.g., annually over a region to estimate agricultural production or potential biodiversity loss), new ground truth data must be collected, leading to the complete disregard of previously gathered reference data despite the substantial financial and time investment they have required. How to make value of historical data, from the same or similar study sites, to enhance the current LULC mapping process constitutes a significant challenge that could enable the financial and human-resource efforts invested in previous data campaigns to be valued again. Aiming to tackle this important challenge, we here propose a deep learning framework based on recent advances in domain adaptation and generalization to combine remote sensing and reference data coming from two different domains (e.g. historical data and fresh ones) to ameliorate the current LC mapping process. Our approach, namely REFeD (data Reuse with Effective Feature Disentanglement for land cover mapping), leverages a disentanglement strategy, based on contrastive learning, where invariant and specific per-domain features are derived to recover the intrinsic information related to the downstream LC mapping task and alleviate possible distribution shifts between domains. Additionally, REFeD is equipped with an effective supervision scheme where feature disentanglement is further enforced via multiple levels of supervision at different granularities. The experimental assessment over two study areas covering extremely diverse and contrasted landscapes, namely Koumbia (located in the West-Africa region, in Burkina Faso) and Centre Val de Loire (located in centre Europe, France), underlines the quality of our framework and the obtained findings demonstrate that out-of-year information coming from the same (or similar) study site, at different periods of time, can constitute a valuable additional source of information to enhance the LC mapping process.
Hierarchical Concept Discovery Models: A Concept Pyramid Scheme
Oct 03, 2023



Deep Learning algorithms have recently gained significant attention due to their impressive performance. However, their high complexity and un-interpretable mode of operation hinders their confident deployment in real-world safety-critical tasks. This work targets ante hoc interpretability, and specifically Concept Bottleneck Models (CBMs). Our goal is to design a framework that admits a highly interpretable decision making process with respect to human understandable concepts, on multiple levels of granularity. To this end, we propose a novel hierarchical concept discovery formulation leveraging: (i) recent advances in image-text models, and (ii) an innovative formulation for multi-level concept selection via data-driven and sparsity inducing Bayesian arguments. Within this framework, concept information does not solely rely on the similarity between the whole image and general unstructured concepts; instead, we introduce the notion of concept hierarchy to uncover and exploit more granular concept information residing in patch-specific regions of the image scene. As we experimentally show, the proposed construction not only outperforms recent CBM approaches, but also yields a principled framework towards interpetability.