 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroundSet: A Cadastral-Grounded Dataset for Spatial Understanding with Vector Data
Mar 15, 2026Precise spatial understanding in Earth Observation is essential for translating raw aerial imagery into actionable insights for critical applications like urban planning, environmental monitoring and disaster management. However, Multimodal Large Language Models exhibit critical deficiencies in fine-grained spatial understanding within Remote Sensing, primarily due to a reliance on limited or repurposed legacy datasets. To bridge this gap, we introduce a large-scale dataset grounded in verifiable cadastral vector data, comprising 3.8 million annotated objects across 510k high-resolution images with 135 granular semantic categories. We validate this resource through a comprehensive instruction-tuning benchmark spanning seven spatial reasoning tasks. Our evaluation establishes a robust baseline using a standard LLaVA architecture. We show that while current RS-specialized and commercial models (e.g., Gemini) struggle in zero-shot settings, high-fidelity supervision effectively bridges this gap, enabling standard architectures to master fine-grained spatial grounding without complex architectural modifications.
Revisiting Cross-Modal Knowledge Distillation: A Disentanglement Approach for RGBD Semantic Segmentation
May 30, 2025Multi-modal RGB and Depth (RGBD) data are predominant in many domains such as robotics, autonomous driving and remote sensing. The combination of these multi-modal data enhances environmental perception by providing 3D spatial context, which is absent in standard RGB images. Although RGBD multi-modal data can be available to train computer vision models, accessing all sensor modalities during the inference stage may be infeasible due to sensor failures or resource constraints, leading to a mismatch between data modalities available during training and inference. Traditional Cross-Modal Knowledge Distillation (CMKD) frameworks, developed to address this task, are typically based on a teacher/student paradigm, where a multi-modal teacher distills knowledge into a single-modality student model. However, these approaches face challenges in teacher architecture choices and distillation process selection, thus limiting their adoption in real-world scenarios. To overcome these issues, we introduce CroDiNo-KD (Cross-Modal Disentanglement: a New Outlook on Knowledge Distillation), a novel cross-modal knowledge distillation framework for RGBD semantic segmentation. Our approach simultaneously learns single-modality RGB and Depth models by exploiting disentanglement representation, contrastive learning and decoupled data augmentation with the aim to structure the internal manifolds of neural network models through interaction and collaboration. We evaluated CroDiNo-KD on three RGBD datasets across diverse domains, considering recent CMKD frameworks as competitors. Our findings illustrate the quality of CroDiNo-KD, and they suggest reconsidering the conventional teacher/student paradigm to distill information from multi-modal data to single-modality neural networks.
Towards a multimodal framework for remote sensing image change retrieval and captioning
Jun 19, 2024



Recently, there has been increasing interest in multimodal applications that integrate text with other modalities, such as images, audio and video, to facilitate natural language interactions with multimodal AI systems. While applications involving standard modalities have been extensively explored, there is still a lack of investigation into specific data modalities such as remote sensing (RS) data. Despite the numerous potential applications of RS data, including environmental protection, disaster monitoring and land planning, available solutions are predominantly focused on specific tasks like classification, captioning and retrieval. These solutions often overlook the unique characteristics of RS data, such as its capability to systematically provide information on the same geographical areas over time. This ability enables continuous monitoring of changes in the underlying landscape. To address this gap, we propose a novel foundation model for bi-temporal RS image pairs, in the context of change detection analysis, leveraging Contrastive Learning and the LEVIR-CC dataset for both captioning and text-image retrieval. By jointly training a contrastive encoder and captioning decoder, our model add text-image retrieval capabilities, in the context of bi-temporal change detection, while maintaining captioning performances that are comparable to the state of the art. We release the source code and pretrained weights at: https://github.com/rogerferrod/RSICRC.
Combining Contrastive Learning and Knowledge Graph Embeddings to develop medical word embeddings for the Italian language
Nov 09, 2022


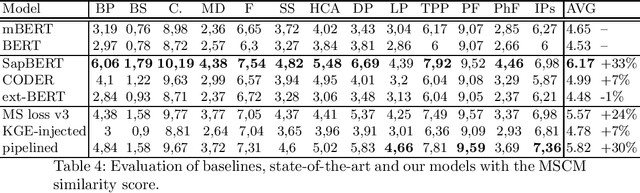
Word embeddings play a significant role in today's Natural Language Processing tasks and applications. While pre-trained models may be directly employed and integrated into existing pipelines, they are often fine-tuned to better fit with specific languages or domains. In this paper, we attempt to improve available embeddings in the uncovered niche of the Italian medical domain through the combination of Contrastive Learning (CL) and Knowledge Graph Embedding (KGE). The main objective is to improve the accuracy of semantic similarity between medical terms, which is also used as an evaluation task. Since the Italian language lacks medical texts and controlled vocabularies, we have developed a specific solution by combining preexisting CL methods (multi-similarity loss, contextualization, dynamic sampling) and the integration of KGEs, creating a new variant of the loss. Although without having outperformed the state-of-the-art, represented by multilingual models, the obtained results are encouraging, providing a significant leap in performance compared to the starting model, while using a significantly lower amount of data.