 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Oracle Datasets to Analyze Noise Impact: A Study on Building Function Classification Using Tweets
Mar 28, 2025


Tweets provides valuable semantic context for earth observation tasks and serves as a complementary modality to remote sensing imagery. In building function classification (BFC), tweets are often collected using geographic heuristics and labeled via external databases, an inherently weakly supervised process that introduces both label noise and sentence level feature noise (e.g., irrelevant or uninformative tweets). While label noise has been widely studied, the impact of sentence level feature noise remains underexplored, largely due to the lack of clean benchmark datasets for controlled analysis. In this work, we propose a method for generating a synthetic oracle dataset using LLM, designed to contain only tweets that are both correctly labeled and semantically relevant to their associated buildings. This oracle dataset enables systematic investigation of noise impacts that are otherwise difficult to isolate in real-world data. To assess its utility, we compare model performance using Naive Bayes and mBERT classifiers under three configurations: real vs. synthetic training data, and cross-domain generalization. Results show that noise in real tweets significantly degrades the contextual learning capacity of mBERT, reducing its performance to that of a simple keyword-based model. In contrast, the clean synthetic dataset allows mBERT to learn effectively, outperforming Naive Bayes Bayes by a large margin. These findings highlight that addressing feature noise is more critical than model complexity in this task. Our synthetic dataset offers a novel experimental environment for future noise injection studies and is publicly available on GitHub.
LHRS-Bot-Nova: Improved Multimodal Large Language Model for Remote Sensing Vision-Language Interpretation
Nov 14, 2024

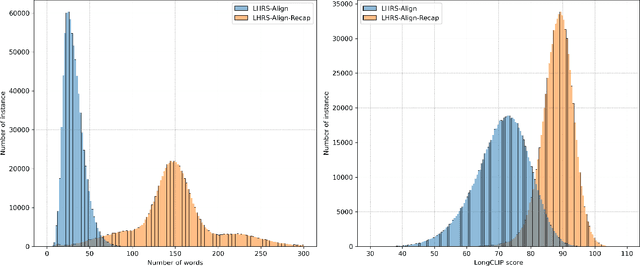

Automatically and rapidly understanding Earth's surface is fundamental to our grasp of the living environment and informed decision-making. This underscores the need for a unified system with comprehensive capabilities in analyzing Earth's surface to address a wide range of human needs. The emergence of multimodal large language models (MLLMs) has great potential in boosting the efficiency and convenience of intelligent Earth observation. These models can engage in human-like conversations, serve as unified platforms for understanding images, follow diverse instructions, and provide insightful feedbacks. In this study, we introduce LHRS-Bot-Nova, an MLLM specialized in understanding remote sensing (RS) images, designed to expertly perform a wide range of RS understanding tasks aligned with human instructions. LHRS-Bot-Nova features an enhanced vision encoder and a novel bridge layer, enabling efficient visual compression and better language-vision alignment. To further enhance RS-oriented vision-language alignment, we propose a large-scale RS image-caption dataset, generated through feature-guided image recaptioning. Additionally, we introduce an instruction dataset specifically designed to improve spatial recognition abilities. Extensive experiments demonstrate superior performance of LHRS-Bot-Nova across various RS image understanding tasks. We also evaluate different MLLM performances in complex RS perception and instruction following using a complicated multi-choice question evaluation benchmark, providing a reliable guide for future model selection and improvement. Data, code, and models will be available at https://github.com/NJU-LHRS/LHRS-Bot.
Contrastive Pretraining for Visual Concept Explanations of Socioeconomic Outcomes
Apr 15, 2024



Predicting socioeconomic indicators from satellite imagery with deep learning has become an increasingly popular research direction. Post-hoc concept-based explanations can be an important step towards broader adoption of these models in policy-making as they enable the interpretation of socioeconomic outcomes based on visual concepts that are intuitive to humans. In this paper, we study the interplay between representation learning using an additional task-specific contrastive loss and post-hoc concept explainability for socioeconomic studies. Our results on two different geographical locations and tasks indicate that the task-specific pretraining imposes a continuous ordering of the latent space embeddings according to the socioeconomic outcomes. This improves the model's interpretability as it enables the latent space of the model to associate urban concepts with continuous intervals of socioeconomic outcomes. Further, we illustrate how analyzing the model's conceptual sensitivity for the intervals of socioeconomic outcomes can shed light on new insights for urban studies.
Building Footprint Extraction with Graph Convolutional Network
May 08, 2023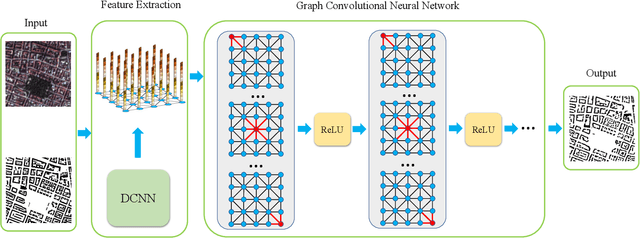


Building footprint information is an essential ingredient for 3-D reconstruction of urban models. The automatic generation of building footprints from satellite images presents a considerable challenge due to the complexity of building shapes. Recent developments in deep convolutional neural networks (DCNNs) have enabled accurate pixel-level labeling tasks. One central issue remains, which is the precise delineation of boundaries. Deep architectures generally fail to produce fine-grained segmentation with accurate boundaries due to progressive downsampling. In this work, we have proposed a end-to-end framework to overcome this issue, which uses the graph convolutional network (GCN) for building footprint extraction task. Our proposed framework outperforms state-of-the-art methods.
MH-DETR: Video Moment and Highlight Detection with Cross-modal Transformer
Apr 29, 2023



With the increasing demand for video understanding, video moment and highlight detection (MHD) has emerged as a critical research topic. MHD aims to localize all moments and predict clip-wise saliency scores simultaneously. Despite progress made by existing DETR-based methods, we observe that these methods coarsely fuse features from different modalities, which weakens the temporal intra-modal context and results in insufficient cross-modal interaction. To address this issue, we propose MH-DETR (Moment and Highlight Detection Transformer) tailored for MHD. Specifically, we introduce a simple yet efficient pooling operator within the uni-modal encoder to capture global intra-modal context. Moreover, to obtain temporally aligned cross-modal features, we design a plug-and-play cross-modal interaction module between the encoder and decoder, seamlessly integrating visual and textual features. Comprehensive experiments on QVHighlights, Charades-STA, Activity-Net, and TVSum datasets show that MH-DETR outperforms existing state-of-the-art methods, demonstrating its effectiveness and superiority. Our code is available at https://github.com/YoucanBaby/MH-DETR.
ReforesTree: A Dataset for Estimating Tropical Forest Carbon Stock with Deep Learning and Aerial Imagery
Jan 26, 2022
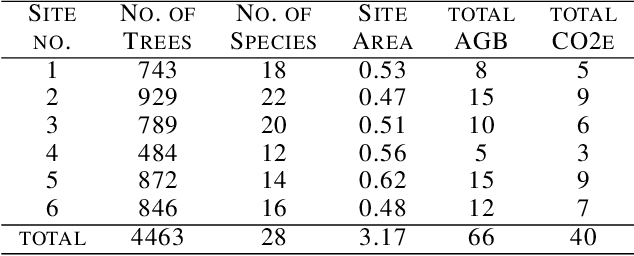
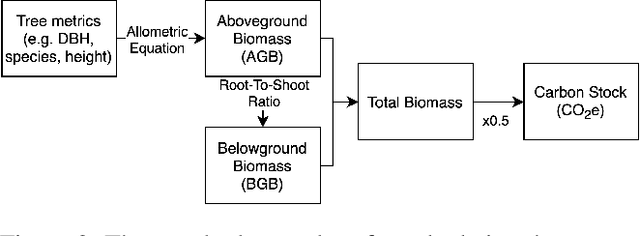
Forest biomass is a key influence for future climate, and the world urgently needs highly scalable financing schemes, such as carbon offsetting certifications, to protect and restore forests. Current manual forest carbon stock inventory methods of measuring single trees by hand are time, labour, and cost-intensive and have been shown to be subjective. They can lead to substantial overestimation of the carbon stock and ultimately distrust in forest financing. The potential for impact and scale of leveraging advancements in machine learning and remote sensing technologies is promising but needs to be of high quality in order to replace the current forest stock protocols for certifications. In this paper, we present ReforesTree, a benchmark dataset of forest carbon stock in six agro-forestry carbon offsetting sites in Ecuador. Furthermore, we show that a deep learning-based end-to-end model using individual tree detection from low cost RGB-only drone imagery is accurately estimating forest carbon stock within official carbon offsetting certification standards. Additionally, our baseline CNN model outperforms state-of-the-art satellite-based forest biomass and carbon stock estimates for this type of small-scale, tropical agro-forestry sites. We present this dataset to encourage machine learning research in this area to increase accountability and transparency of monitoring, verification and reporting (MVR) in carbon offsetting projects, as well as scaling global reforestation financing through accurate remote sensing.
SEN12MS-CR-TS: A Remote Sensing Data Set for Multi-modal Multi-temporal Cloud Removal
Jan 24, 2022


About half of all optical observations collected via spaceborne satellites are affected by haze or clouds. Consequently, cloud coverage affects the remote sensing practitioner's capabilities of a continuous and seamless monitoring of our planet. This work addresses the challenge of optical satellite image reconstruction and cloud removal by proposing a novel multi-modal and multi-temporal data set called SEN12MS-CR-TS. We propose two models highlighting the benefits and use cases of SEN12MS-CR-TS: First, a multi-modal multi-temporal 3D-Convolution Neural Network that predicts a cloud-free image from a sequence of cloudy optical and radar images. Second, a sequence-to-sequence translation model that predicts a cloud-free time series from a cloud-covered time series. Both approaches are evaluated experimentally, with their respective models trained and tested on SEN12MS-CR-TS. The conducted experiments highlight the contribution of our data set to the remote sensing community as well as the benefits of multi-modal and multi-temporal information to reconstruct noisy information. Our data set is available at https://patrickTUM.github.io/cloud_removal
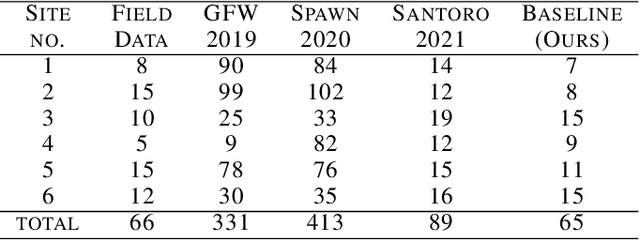
Change Detection Meets Visual Question Answering
Dec 12, 2021
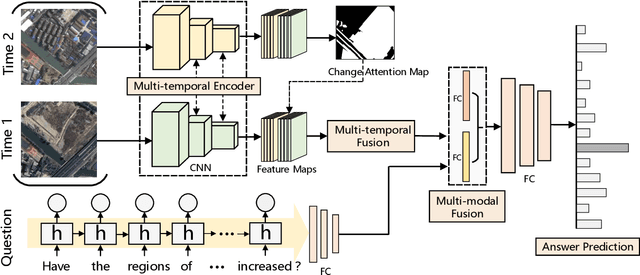

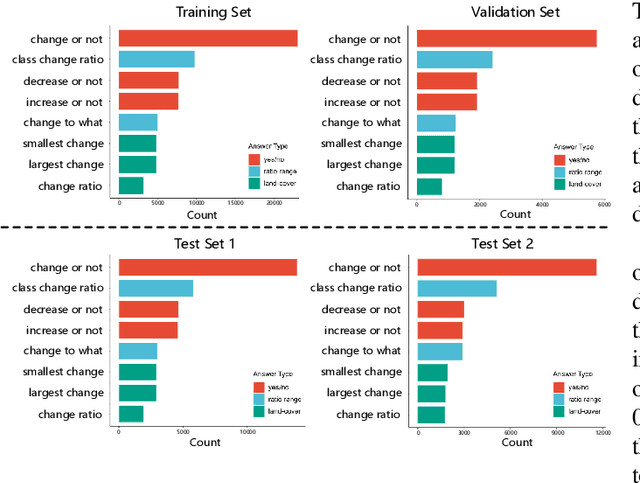
The Earth's surface is continually changing, and identifying changes plays an important role in urban planning and sustainability. Although change detection techniques have been successfully developed for many years, these techniques are still limited to experts and facilitators in related fields. In order to provide every user with flexible access to change information and help them better understand land-cover changes, we introduce a novel task: change detection-based visual question answering (CDVQA) on multi-temporal aerial images. In particular, multi-temporal images can be queried to obtain high level change-based information according to content changes between two input images. We first build a CDVQA dataset including multi-temporal image-question-answer triplets using an automatic question-answer generation method. Then, a baseline CDVQA framework is devised in this work, and it contains four parts: multi-temporal feature encoding, multi-temporal fusion, multi-modal fusion, and answer prediction. In addition, we also introduce a change enhancing module to multi-temporal feature encoding, aiming at incorporating more change-related information. Finally, effects of different backbones and multi-temporal fusion strategies are studied on the performance of CDVQA task. The experimental results provide useful insights for developing better CDVQA models, which are important for future research on this task. We will make our dataset and code publicly available.
Tackling the Overestimation of Forest Carbon with Deep Learning and Aerial Imagery
Aug 19, 2021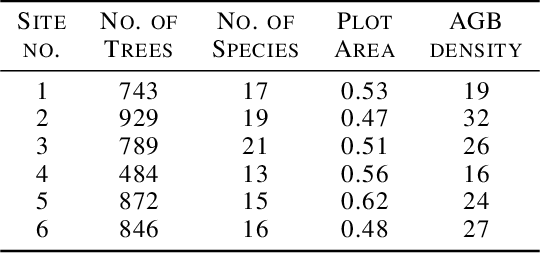
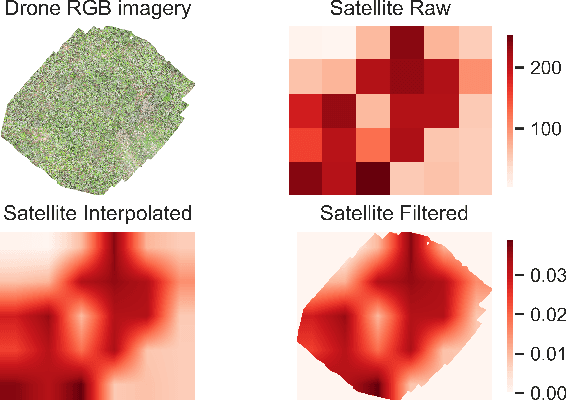
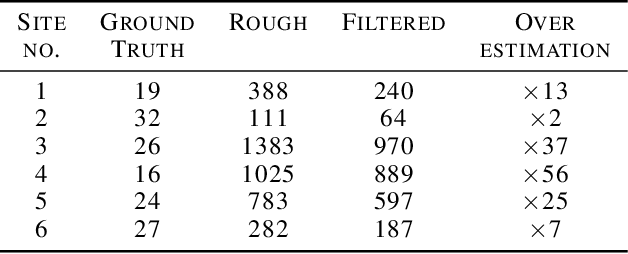
Forest carbon offsets are increasingly popular and can play a significant role in financing climate mitigation, forest conservation, and reforestation. Measuring how much carbon is stored in forests is, however, still largely done via expensive, time-consuming, and sometimes unaccountable field measurements. To overcome these limitations, many verification bodies are leveraging machine learning (ML) algorithms to estimate forest carbon from satellite or aerial imagery. Aerial imagery allows for tree species or family classification, which improves the satellite imagery-based forest type classification. However, aerial imagery is significantly more expensive to collect and it is unclear by how much the higher resolution improves the forest carbon estimation. This proposal paper describes the first systematic comparison of forest carbon estimation from aerial imagery, satellite imagery, and ground-truth field measurements via deep learning-based algorithms for a tropical reforestation project. Our initial results show that forest carbon estimates from satellite imagery can overestimate above-ground biomass by up to 10-times for tropical reforestation projects. The significant difference between aerial and satellite-derived forest carbon measurements shows the potential for aerial imagery-based ML algorithms and raises the importance to extend this study to a global benchmark between options for carbon measurements.
SCIDA: Self-Correction Integrated Domain Adaptation from Single- to Multi-label Aerial Images
Aug 15, 2021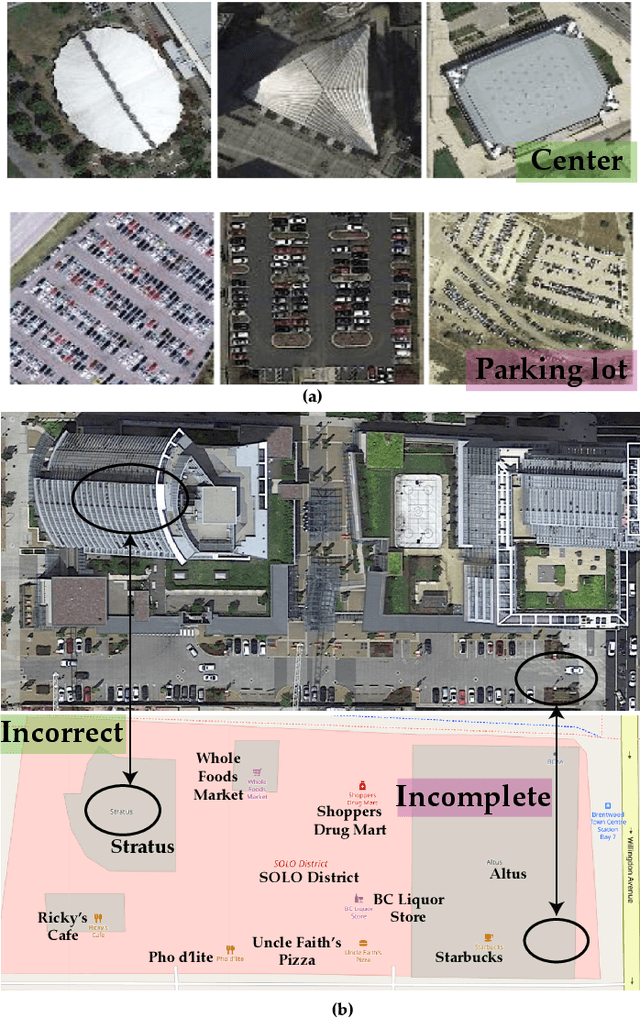
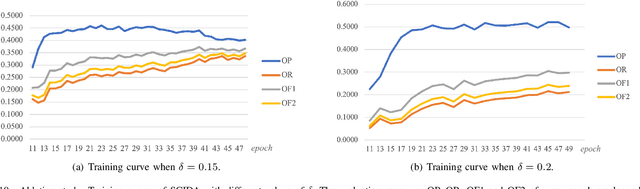
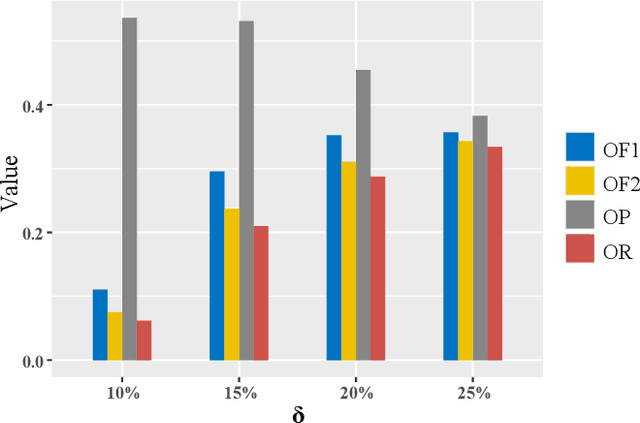
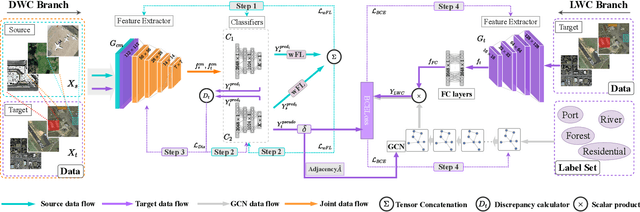
Most publicly available datasets for image classification are with single labels, while images are inherently multi-labeled in our daily life. Such an annotation gap makes many pre-trained single-label classification models fail in practical scenarios. This annotation issue is more concerned for aerial images: Aerial data collected from sensors naturally cover a relatively large land area with multiple labels, while annotated aerial datasets, which are publicly available (e.g., UCM, AID), are single-labeled. As manually annotating multi-label aerial images would be time/labor-consuming, we propose a novel self-correction integrated domain adaptation (SCIDA) method for automatic multi-label learning. SCIDA is weakly supervised, i.e., automatically learning the multi-label image classification model from using massive, publicly available single-label images. To achieve this goal, we propose a novel Label-Wise self-Correction (LWC) module to better explore underlying label correlations. This module also makes the unsupervised domain adaptation (UDA) from single- to multi-label data possible. For model training, the proposed model only uses single-label information yet requires no prior knowledge of multi-labeled data; and it predicts labels for multi-label aerial images. In our experiments, trained with single-labeled MAI-AID-s and MAI-UCM-s datasets, the proposed model is tested directly on our collected Multi-scene Aerial Image (MAI) dataset.