 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing Image Super-Resolution for Imbalanced Textures: A Texture-Aware Diffusion Framework
Apr 15, 2026Generative diffusion priors have recently achieved state-of-the-art performance in natural image super-resolution, demonstrating a powerful capability to synthesize photorealistic details. However, their direct application to remote sensing image super-resolution (RSISR) reveals significant shortcomings. Unlike natural images, remote sensing images exhibit a unique texture distribution where ground objects are globally stochastic yet locally clustered, leading to highly imbalanced textures. This imbalance severely hinders the model's spatial perception. To address this, we propose TexADiff, a novel framework that begins by estimating a Relative Texture Density Map (RTDM) to represent the texture distribution. TexADiff then leverages this RTDM in three synergistic ways: as an explicit spatial conditioning to guide the diffusion process, as a loss modulation term to prioritize texture-rich regions, and as a dynamic adapter for the sampling schedule. These modifications are designed to endow the model with explicit texture-aware capabilities. Experiments demonstrate that TexADiff achieves superior or competitive quantitative metrics. Furthermore, qualitative results show that our model generates faithful high-frequency details while effectively suppressing texture hallucinations. This improved reconstruction quality also results in significant gains in downstream task performance. The source code of our method can be found at https://github.com/ZezFuture/TexAdiff.
FarSLIP: Discovering Effective CLIP Adaptation for Fine-Grained Remote Sensing Understanding
Nov 18, 2025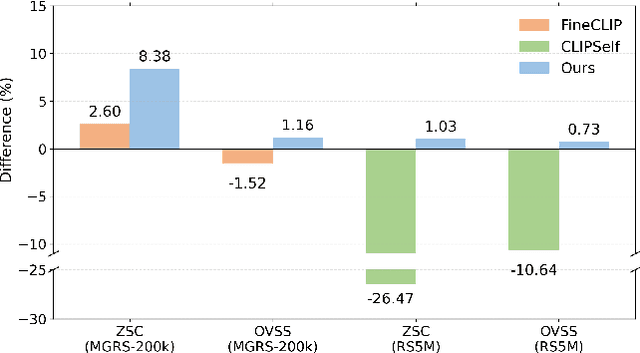
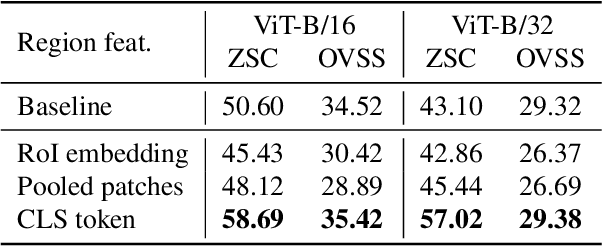
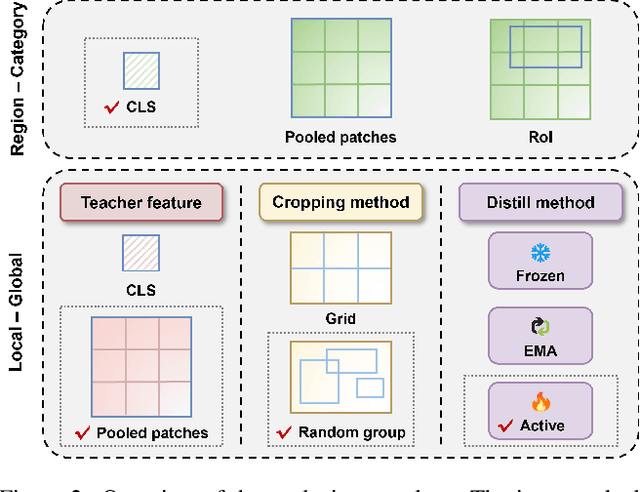
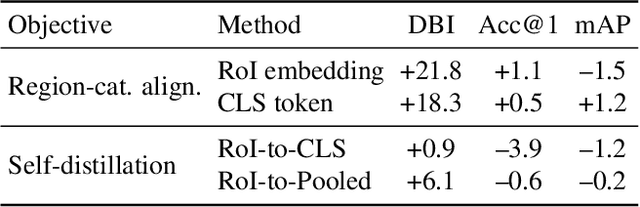
As CLIP's global alignment limits its ability to capture fine-grained details, recent efforts have focused on enhancing its region-text alignment. However, current remote sensing (RS)-specific CLIP variants still inherit this limited spatial awareness. We identify two key limitations behind this: (1) current RS image-text datasets generate global captions from object-level labels, leaving the original object-level supervision underutilized; (2) despite the success of region-text alignment methods in general domain, their direct application to RS data often leads to performance degradation. To address these, we construct the first multi-granularity RS image-text dataset, MGRS-200k, featuring rich object-level textual supervision for RS region-category alignment. We further investigate existing fine-grained CLIP tuning strategies and find that current explicit region-text alignment methods, whether in a direct or indirect way, underperform due to severe degradation of CLIP's semantic coherence. Building on these, we propose FarSLIP, a Fine-grained Aligned RS Language-Image Pretraining framework. Rather than the commonly used patch-to-CLS self-distillation, FarSLIP employs patch-to-patch distillation to align local and global visual cues, which improves feature discriminability while preserving semantic coherence. Additionally, to effectively utilize region-text supervision, it employs simple CLS token-based region-category alignment rather than explicit patch-level alignment, further enhancing spatial awareness. FarSLIP features improved fine-grained vision-language alignment in RS domain and sets a new state of the art not only on RS open-vocabulary semantic segmentation, but also on image-level tasks such as zero-shot classification and image-text retrieval. Our dataset, code, and models are available at https://github.com/NJU-LHRS/FarSLIP.
LHRS-Bot-Nova: Improved Multimodal Large Language Model for Remote Sensing Vision-Language Interpretation
Nov 14, 2024


Automatically and rapidly understanding Earth's surface is fundamental to our grasp of the living environment and informed decision-making. This underscores the need for a unified system with comprehensive capabilities in analyzing Earth's surface to address a wide range of human needs. The emergence of multimodal large language models (MLLMs) has great potential in boosting the efficiency and convenience of intelligent Earth observation. These models can engage in human-like conversations, serve as unified platforms for understanding images, follow diverse instructions, and provide insightful feedbacks. In this study, we introduce LHRS-Bot-Nova, an MLLM specialized in understanding remote sensing (RS) images, designed to expertly perform a wide range of RS understanding tasks aligned with human instructions. LHRS-Bot-Nova features an enhanced vision encoder and a novel bridge layer, enabling efficient visual compression and better language-vision alignment. To further enhance RS-oriented vision-language alignment, we propose a large-scale RS image-caption dataset, generated through feature-guided image recaptioning. Additionally, we introduce an instruction dataset specifically designed to improve spatial recognition abilities. Extensive experiments demonstrate superior performance of LHRS-Bot-Nova across various RS image understanding tasks. We also evaluate different MLLM performances in complex RS perception and instruction following using a complicated multi-choice question evaluation benchmark, providing a reliable guide for future model selection and improvement. Data, code, and models will be available at https://github.com/NJU-LHRS/LHRS-Bot.
LHRS-Bot: Empowering Remote Sensing with VGI-Enhanced Large Multimodal Language Model
Feb 07, 2024
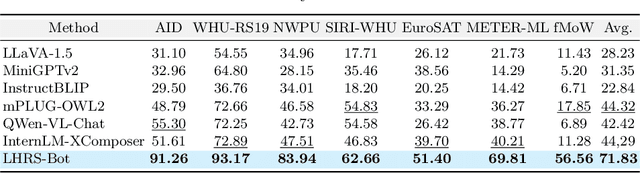


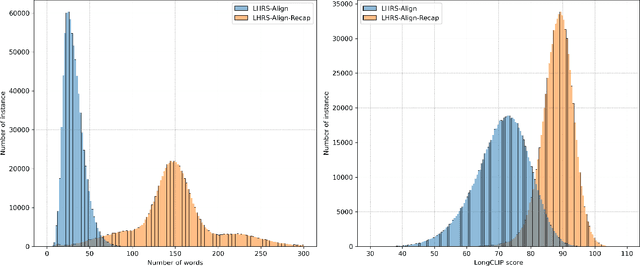
The revolutionary capabilities of large language models (LLMs) have paved the way for multimodal large language models (MLLMs) and fostered diverse applications across various specialized domains. In the remote sensing (RS) field, however, the diverse geographical landscapes and varied objects in RS imagery are not adequately considered in recent MLLM endeavors. To bridge this gap, we construct a large-scale RS image-text dataset, LHRS-Align, and an informative RS-specific instruction dataset, LHRS-Instruct, leveraging the extensive volunteered geographic information (VGI) and globally available RS images. Building on this foundation, we introduce LHRS-Bot, an MLLM tailored for RS image understanding through a novel multi-level vision-language alignment strategy and a curriculum learning method. Comprehensive experiments demonstrate that LHRS-Bot exhibits a profound understanding of RS images and the ability to perform nuanced reasoning within the RS domain.
CMID: A Unified Self-Supervised Learning Framework for Remote Sensing Image Understanding
Apr 19, 2023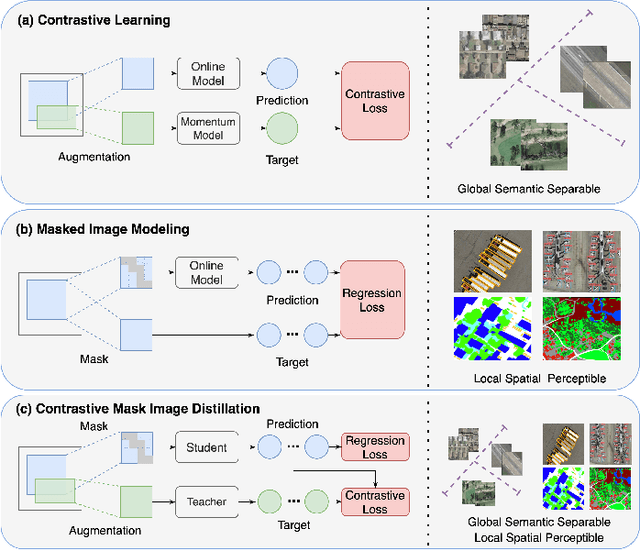
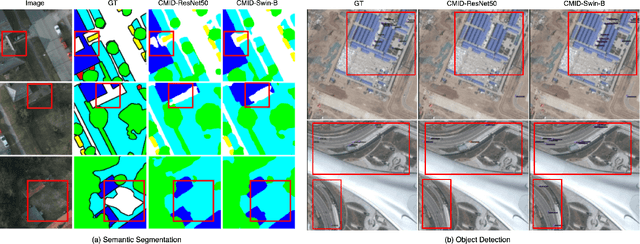
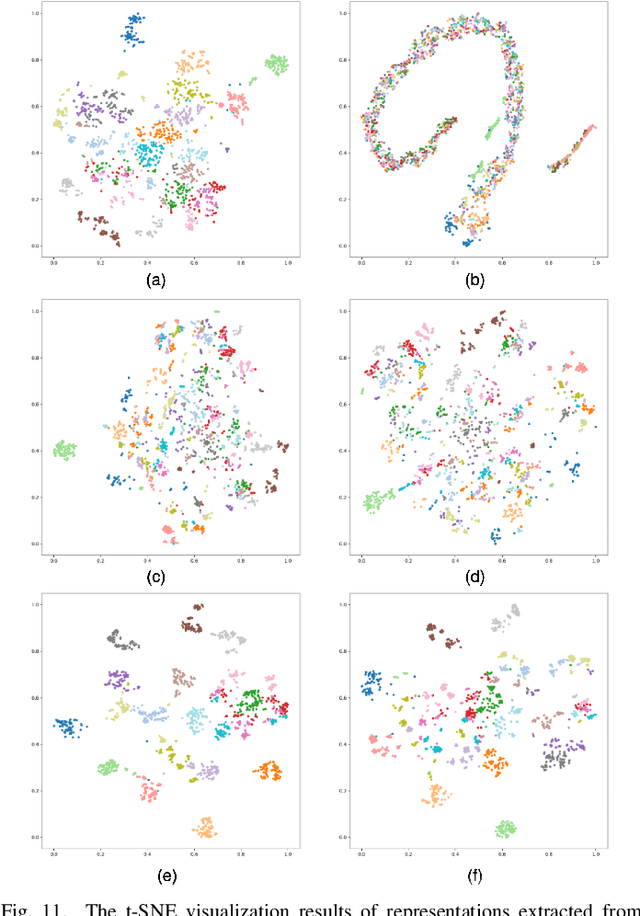
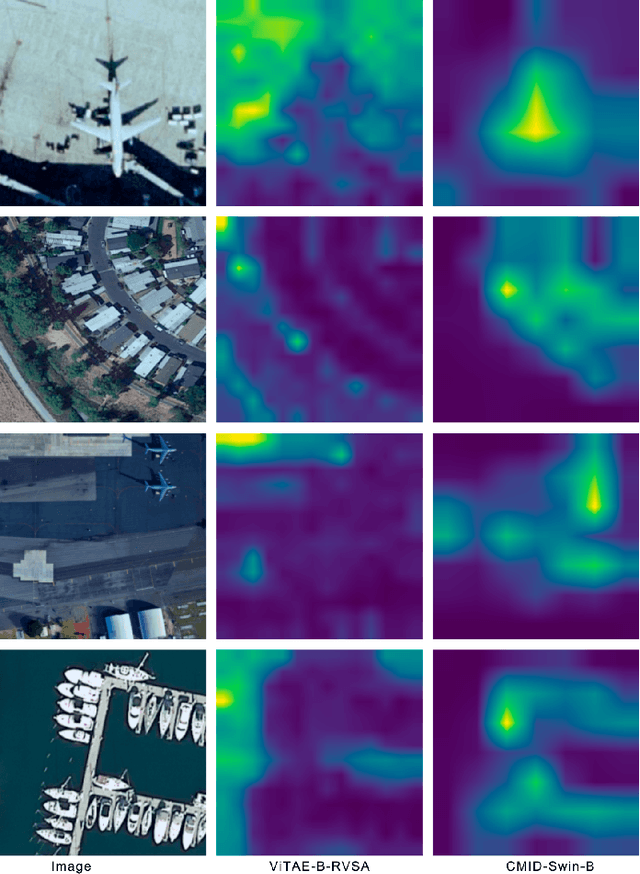
Self-supervised learning (SSL) has gained widespread attention in the remote sensing (RS) and earth observation (EO) communities owing to its ability to learn task-agnostic representations without human-annotated labels. Nevertheless, most existing RS SSL methods are limited to learning either global semantic separable or local spatial perceptible representations. We argue that this learning strategy is suboptimal in the realm of RS, since the required representations for different RS downstream tasks are often varied and complex. In this study, we proposed a unified SSL framework that is better suited for RS images representation learning. The proposed SSL framework, Contrastive Mask Image Distillation (CMID), is capable of learning representations with both global semantic separability and local spatial perceptibility by combining contrastive learning (CL) with masked image modeling (MIM) in a self-distillation way. Furthermore, our CMID learning framework is architecture-agnostic, which is compatible with both convolutional neural networks (CNN) and vision transformers (ViT), allowing CMID to be easily adapted to a variety of deep learning (DL) applications for RS understanding. Comprehensive experiments have been carried out on four downstream tasks (i.e. scene classification, semantic segmentation, object-detection, and change detection) and the results show that models pre-trained using CMID achieve better performance than other state-of-the-art SSL methods on multiple downstream tasks. The code and pre-trained models will be made available at https://github.com/NJU-LHRS/official-CMID to facilitate SSL research and speed up the development of RS images DL applications.