 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing Image Super-Resolution for Imbalanced Textures: A Texture-Aware Diffusion Framework
Apr 15, 2026Generative diffusion priors have recently achieved state-of-the-art performance in natural image super-resolution, demonstrating a powerful capability to synthesize photorealistic details. However, their direct application to remote sensing image super-resolution (RSISR) reveals significant shortcomings. Unlike natural images, remote sensing images exhibit a unique texture distribution where ground objects are globally stochastic yet locally clustered, leading to highly imbalanced textures. This imbalance severely hinders the model's spatial perception. To address this, we propose TexADiff, a novel framework that begins by estimating a Relative Texture Density Map (RTDM) to represent the texture distribution. TexADiff then leverages this RTDM in three synergistic ways: as an explicit spatial conditioning to guide the diffusion process, as a loss modulation term to prioritize texture-rich regions, and as a dynamic adapter for the sampling schedule. These modifications are designed to endow the model with explicit texture-aware capabilities. Experiments demonstrate that TexADiff achieves superior or competitive quantitative metrics. Furthermore, qualitative results show that our model generates faithful high-frequency details while effectively suppressing texture hallucinations. This improved reconstruction quality also results in significant gains in downstream task performance. The source code of our method can be found at https://github.com/ZezFuture/TexAdiff.
OpenEarth-Agent: From Tool Calling to Tool Creation for Open-Environment Earth Observation
Mar 23, 2026Earth Observation (EO) is essential for perceiving dynamic land surface changes, yet deploying autonomous EO in open environments is hindered by the immense diversity of multi-source data and heterogeneous tasks. While remote sensing agents have emerged to streamline EO workflows, existing tool-calling agents are confined to closed environments. They rely on pre-defined tools and are restricted to narrow scope, limiting their generalization to the diverse data and tasks. To overcome these limitations, we introduce OpenEarth-Agent, the first tool-creation agent framework tailored for open-environment EO. Rather than calling predefined tools, OpenEarth-Agent employs adaptive workflow planning and tool creation to generalize to unseen data and tasks. This adaptability is bolstered by an open-ended integration of multi-stage tools and cross-domain knowledge bases, enabling robust execution in the entire EO pipeline across multiple application domains. To comprehensively evaluate EO agents in open environments, we propose OpenEarth-Bench, a novel benchmark comprising 596 real-world, full-pipeline cases across seven application domains, explicitly designed to assess agents' adaptive planning and tool creation capabilities. Only essential pre-trained model tools are provided in this benchmark, devoid of any other predefined task-specific tools. Extensive experiments demonstrate that OpenEarth-Agent successfully masters full-pipeline EO across multiple domains in the open environment. Notably, on the cross-benchmark Earth-Bench, our tool-creating agent equipped with 6 essential pre-trained models achieves performance comparable to tool-calling agents relying on 104 specialized tools, and significantly outperforms them when provided with the complete toolset. In several cases, the created tools exhibit superior robustness to data anomalies compared to human-engineered counterparts.
FarSLIP: Discovering Effective CLIP Adaptation for Fine-Grained Remote Sensing Understanding
Nov 18, 2025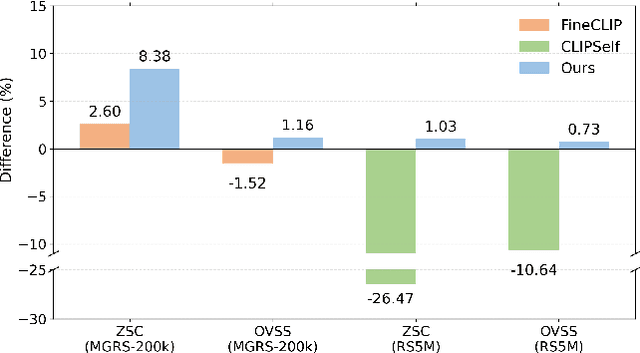
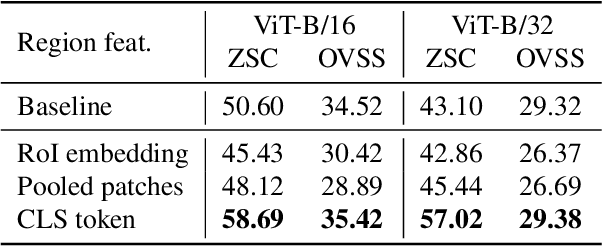
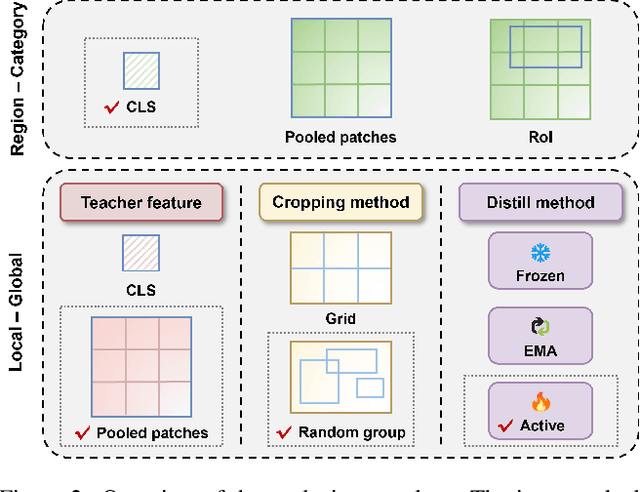
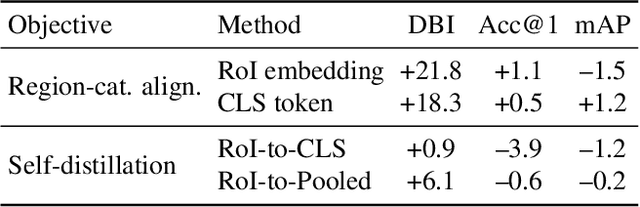
As CLIP's global alignment limits its ability to capture fine-grained details, recent efforts have focused on enhancing its region-text alignment. However, current remote sensing (RS)-specific CLIP variants still inherit this limited spatial awareness. We identify two key limitations behind this: (1) current RS image-text datasets generate global captions from object-level labels, leaving the original object-level supervision underutilized; (2) despite the success of region-text alignment methods in general domain, their direct application to RS data often leads to performance degradation. To address these, we construct the first multi-granularity RS image-text dataset, MGRS-200k, featuring rich object-level textual supervision for RS region-category alignment. We further investigate existing fine-grained CLIP tuning strategies and find that current explicit region-text alignment methods, whether in a direct or indirect way, underperform due to severe degradation of CLIP's semantic coherence. Building on these, we propose FarSLIP, a Fine-grained Aligned RS Language-Image Pretraining framework. Rather than the commonly used patch-to-CLS self-distillation, FarSLIP employs patch-to-patch distillation to align local and global visual cues, which improves feature discriminability while preserving semantic coherence. Additionally, to effectively utilize region-text supervision, it employs simple CLS token-based region-category alignment rather than explicit patch-level alignment, further enhancing spatial awareness. FarSLIP features improved fine-grained vision-language alignment in RS domain and sets a new state of the art not only on RS open-vocabulary semantic segmentation, but also on image-level tasks such as zero-shot classification and image-text retrieval. Our dataset, code, and models are available at https://github.com/NJU-LHRS/FarSLIP.
Temporal-Spectral-Spatial Unified Remote Sensing Dense Prediction
May 18, 2025The proliferation of diverse remote sensing data has spurred advancements in dense prediction tasks, yet significant challenges remain in handling data heterogeneity. Remote sensing imagery exhibits substantial variability across temporal, spectral, and spatial (TSS) dimensions, complicating unified data processing. Current deep learning models for dense prediction tasks, such as semantic segmentation and change detection, are typically tailored to specific input-output configurations. Consequently, variations in data dimensionality or task requirements often lead to significant performance degradation or model incompatibility, necessitating costly retraining or fine-tuning efforts for different application scenarios. This paper introduces the Temporal-Spectral-Spatial Unified Network (TSSUN), a novel architecture designed for unified representation and modeling of remote sensing data across diverse TSS characteristics and task types. TSSUN employs a Temporal-Spectral-Spatial Unified Strategy that leverages meta-information to decouple and standardize input representations from varied temporal, spectral, and spatial configurations, and similarly unifies output structures for different dense prediction tasks and class numbers. Furthermore, a Local-Global Window Attention mechanism is proposed to efficiently capture both local contextual details and global dependencies, enhancing the model's adaptability and feature extraction capabilities. Extensive experiments on multiple datasets demonstrate that a single TSSUN model effectively adapts to heterogeneous inputs and unifies various dense prediction tasks. The proposed approach consistently achieves or surpasses state-of-the-art performance, highlighting its robustness and generalizability for complex remote sensing applications without requiring task-specific modifications.
Transforming Weather Data from Pixel to Latent Space
Mar 09, 2025The increasing impact of climate change and extreme weather events has spurred growing interest in deep learning for weather research. However, existing studies often rely on weather data in pixel space, which presents several challenges such as smooth outputs in model outputs, limited applicability to a single pressure-variable subset (PVS), and high data storage and computational costs. To address these challenges, we propose a novel Weather Latent Autoencoder (WLA) that transforms weather data from pixel space to latent space, enabling efficient weather task modeling. By decoupling weather reconstruction from downstream tasks, WLA improves the accuracy and sharpness of weather task model results. The incorporated Pressure-Variable Unified Module transforms multiple PVS into a unified representation, enhancing the adaptability of the model in multiple weather scenarios. Furthermore, weather tasks can be performed in a low-storage latent space of WLA rather than a high-storage pixel space, thus significantly reducing data storage and computational costs. Through extensive experimentation, we demonstrate its superior compression and reconstruction performance, enabling the creation of the ERA5-latent dataset with unified representations of multiple PVS from ERA5 data. The compressed full PVS in the ERA5-latent dataset reduces the original 244.34 TB of data to 0.43 TB. The downstream task further demonstrates that task models can apply to multiple PVS with low data costs in latent space and achieve superior performance compared to models in pixel space. Code, ERA5-latent data, and pre-trained models are available at https://anonymous.4open.science/r/Weather-Latent-Autoencoder-8467.
LHRS-Bot-Nova: Improved Multimodal Large Language Model for Remote Sensing Vision-Language Interpretation
Nov 14, 2024

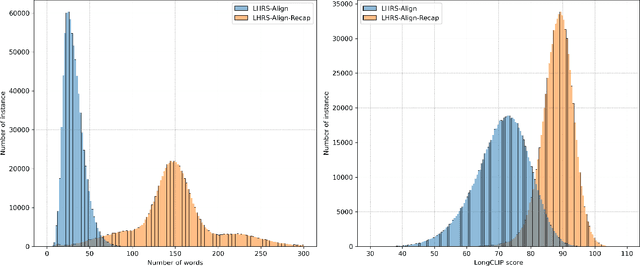

Automatically and rapidly understanding Earth's surface is fundamental to our grasp of the living environment and informed decision-making. This underscores the need for a unified system with comprehensive capabilities in analyzing Earth's surface to address a wide range of human needs. The emergence of multimodal large language models (MLLMs) has great potential in boosting the efficiency and convenience of intelligent Earth observation. These models can engage in human-like conversations, serve as unified platforms for understanding images, follow diverse instructions, and provide insightful feedbacks. In this study, we introduce LHRS-Bot-Nova, an MLLM specialized in understanding remote sensing (RS) images, designed to expertly perform a wide range of RS understanding tasks aligned with human instructions. LHRS-Bot-Nova features an enhanced vision encoder and a novel bridge layer, enabling efficient visual compression and better language-vision alignment. To further enhance RS-oriented vision-language alignment, we propose a large-scale RS image-caption dataset, generated through feature-guided image recaptioning. Additionally, we introduce an instruction dataset specifically designed to improve spatial recognition abilities. Extensive experiments demonstrate superior performance of LHRS-Bot-Nova across various RS image understanding tasks. We also evaluate different MLLM performances in complex RS perception and instruction following using a complicated multi-choice question evaluation benchmark, providing a reliable guide for future model selection and improvement. Data, code, and models will be available at https://github.com/NJU-LHRS/LHRS-Bot.
VegeDiff: Latent Diffusion Model for Geospatial Vegetation Forecasting
Jul 17, 2024In the context of global climate change and frequent extreme weather events, forecasting future geospatial vegetation states under these conditions is of significant importance. The vegetation change process is influenced by the complex interplay between dynamic meteorological variables and static environmental variables, leading to high levels of uncertainty. Existing deterministic methods are inadequate in addressing this uncertainty and fail to accurately model the impact of these variables on vegetation, resulting in blurry and inaccurate forecasting results. To address these issues, we propose VegeDiff for the geospatial vegetation forecasting task. To our best knowledge, VegeDiff is the first to employ a diffusion model to probabilistically capture the uncertainties in vegetation change processes, enabling the generation of clear and accurate future vegetation states. VegeDiff also separately models the global impact of dynamic meteorological variables and the local effects of static environmental variables, thus accurately modeling the impact of these variables. Extensive experiments on geospatial vegetation forecasting tasks demonstrate the effectiveness of VegeDiff. By capturing the uncertainties in vegetation changes and modeling the complex influence of relevant variables, VegeDiff outperforms existing deterministic methods, providing clear and accurate forecasting results of future vegetation states. Interestingly, we demonstrate the potential of VegeDiff in applications of forecasting future vegetation states from multiple aspects and exploring the impact of meteorological variables on vegetation dynamics. The code of this work will be available at https://github.com/walking-shadow/ Official_VegeDiff.
RS-Mamba for Large Remote Sensing Image Dense Prediction
Apr 10, 2024
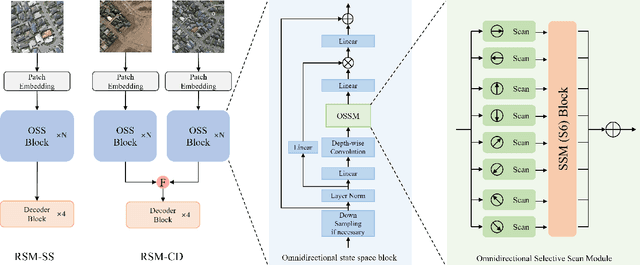
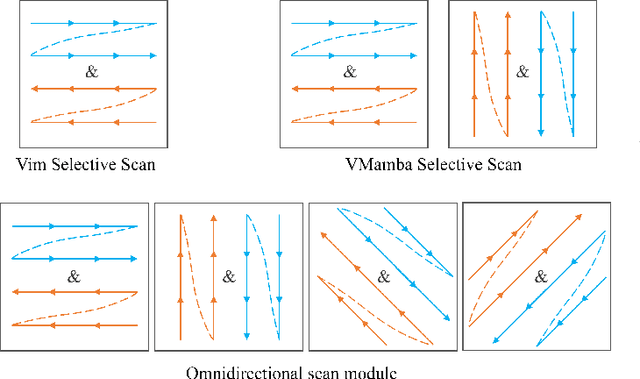
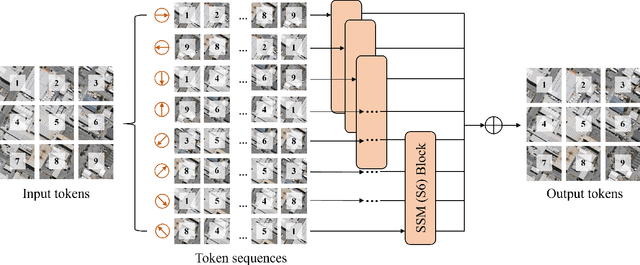
Context modeling is critical for remote sensing image dense prediction tasks. Nowadays, the growing size of very-high-resolution (VHR) remote sensing images poses challenges in effectively modeling context. While transformer-based models possess global modeling capabilities, they encounter computational challenges when applied to large VHR images due to their quadratic complexity. The conventional practice of cropping large images into smaller patches results in a notable loss of contextual information. To address these issues, we propose the Remote Sensing Mamba (RSM) for dense prediction tasks in large VHR remote sensing images. RSM is specifically designed to capture the global context of remote sensing images with linear complexity, facilitating the effective processing of large VHR images. Considering that the land covers in remote sensing images are distributed in arbitrary spatial directions due to characteristics of remote sensing over-head imaging, the RSM incorporates an omnidirectional selective scan module to globally model the context of images in multiple directions, capturing large spatial features from various directions. Extensive experiments on semantic segmentation and change detection tasks across various land covers demonstrate the effectiveness of the proposed RSM. We designed simple yet effective models based on RSM, achieving state-of-the-art performance on dense prediction tasks in VHR remote sensing images without fancy training strategies. Leveraging the linear complexity and global modeling capabilities, RSM achieves better efficiency and accuracy than transformer-based models on large remote sensing images. Interestingly, we also demonstrated that our model generally performs better with a larger image size on dense prediction tasks. Our code is available at https://github.com/walking-shadow/Official_Remote_Sensing_Mamba.
LHRS-Bot: Empowering Remote Sensing with VGI-Enhanced Large Multimodal Language Model
Feb 07, 2024
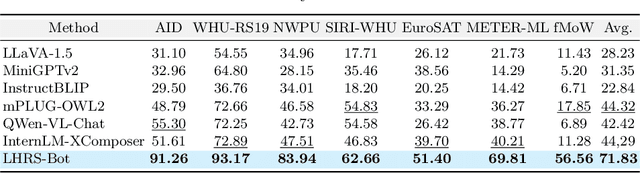


The revolutionary capabilities of large language models (LLMs) have paved the way for multimodal large language models (MLLMs) and fostered diverse applications across various specialized domains. In the remote sensing (RS) field, however, the diverse geographical landscapes and varied objects in RS imagery are not adequately considered in recent MLLM endeavors. To bridge this gap, we construct a large-scale RS image-text dataset, LHRS-Align, and an informative RS-specific instruction dataset, LHRS-Instruct, leveraging the extensive volunteered geographic information (VGI) and globally available RS images. Building on this foundation, we introduce LHRS-Bot, an MLLM tailored for RS image understanding through a novel multi-level vision-language alignment strategy and a curriculum learning method. Comprehensive experiments demonstrate that LHRS-Bot exhibits a profound understanding of RS images and the ability to perform nuanced reasoning within the RS domain.
Exchanging Dual Encoder-Decoder: A New Strategy for Change Detection with Semantic Guidance and Spatial Localization
Nov 19, 2023



Change detection is a critical task in earth observation applications. Recently, deep learning-based methods have shown promising performance and are quickly adopted in change detection. However, the widely used multiple encoder and single decoder (MESD) as well as dual encoder-decoder (DED) architectures still struggle to effectively handle change detection well. The former has problems of bitemporal feature interference in the feature-level fusion, while the latter is inapplicable to intraclass change detection and multiview building change detection. To solve these problems, we propose a new strategy with an exchanging dual encoder-decoder structure for binary change detection with semantic guidance and spatial localization. The proposed strategy solves the problems of bitemporal feature inference in MESD by fusing bitemporal features in the decision level and the inapplicability in DED by determining changed areas using bitemporal semantic features. We build a binary change detection model based on this strategy, and then validate and compare it with 18 state-of-the-art change detection methods on six datasets in three scenarios, including intraclass change detection datasets (CDD, SYSU), single-view building change detection datasets (WHU, LEVIR-CD, LEVIR-CD+) and a multiview building change detection dataset (NJDS). The experimental results demonstrate that our model achieves superior performance with high efficiency and outperforms all benchmark methods with F1-scores of 97.77%, 83.07%, 94.86%, 92.33%, 91.39%, 74.35% on CDD, SYSU, WHU, LEVIR-CD, LEVIR- CD+, and NJDS datasets, respectively. The code of this work will be available at https://github.com/NJU-LHRS/official-SGSLN.