 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenEarth-Agent: From Tool Calling to Tool Creation for Open-Environment Earth Observation
Mar 23, 2026Earth Observation (EO) is essential for perceiving dynamic land surface changes, yet deploying autonomous EO in open environments is hindered by the immense diversity of multi-source data and heterogeneous tasks. While remote sensing agents have emerged to streamline EO workflows, existing tool-calling agents are confined to closed environments. They rely on pre-defined tools and are restricted to narrow scope, limiting their generalization to the diverse data and tasks. To overcome these limitations, we introduce OpenEarth-Agent, the first tool-creation agent framework tailored for open-environment EO. Rather than calling predefined tools, OpenEarth-Agent employs adaptive workflow planning and tool creation to generalize to unseen data and tasks. This adaptability is bolstered by an open-ended integration of multi-stage tools and cross-domain knowledge bases, enabling robust execution in the entire EO pipeline across multiple application domains. To comprehensively evaluate EO agents in open environments, we propose OpenEarth-Bench, a novel benchmark comprising 596 real-world, full-pipeline cases across seven application domains, explicitly designed to assess agents' adaptive planning and tool creation capabilities. Only essential pre-trained model tools are provided in this benchmark, devoid of any other predefined task-specific tools. Extensive experiments demonstrate that OpenEarth-Agent successfully masters full-pipeline EO across multiple domains in the open environment. Notably, on the cross-benchmark Earth-Bench, our tool-creating agent equipped with 6 essential pre-trained models achieves performance comparable to tool-calling agents relying on 104 specialized tools, and significantly outperforms them when provided with the complete toolset. In several cases, the created tools exhibit superior robustness to data anomalies compared to human-engineered counterparts.
Temporal-Spectral-Spatial Unified Remote Sensing Dense Prediction
May 18, 2025The proliferation of diverse remote sensing data has spurred advancements in dense prediction tasks, yet significant challenges remain in handling data heterogeneity. Remote sensing imagery exhibits substantial variability across temporal, spectral, and spatial (TSS) dimensions, complicating unified data processing. Current deep learning models for dense prediction tasks, such as semantic segmentation and change detection, are typically tailored to specific input-output configurations. Consequently, variations in data dimensionality or task requirements often lead to significant performance degradation or model incompatibility, necessitating costly retraining or fine-tuning efforts for different application scenarios. This paper introduces the Temporal-Spectral-Spatial Unified Network (TSSUN), a novel architecture designed for unified representation and modeling of remote sensing data across diverse TSS characteristics and task types. TSSUN employs a Temporal-Spectral-Spatial Unified Strategy that leverages meta-information to decouple and standardize input representations from varied temporal, spectral, and spatial configurations, and similarly unifies output structures for different dense prediction tasks and class numbers. Furthermore, a Local-Global Window Attention mechanism is proposed to efficiently capture both local contextual details and global dependencies, enhancing the model's adaptability and feature extraction capabilities. Extensive experiments on multiple datasets demonstrate that a single TSSUN model effectively adapts to heterogeneous inputs and unifies various dense prediction tasks. The proposed approach consistently achieves or surpasses state-of-the-art performance, highlighting its robustness and generalizability for complex remote sensing applications without requiring task-specific modifications.
Transforming Weather Data from Pixel to Latent Space
Mar 09, 2025The increasing impact of climate change and extreme weather events has spurred growing interest in deep learning for weather research. However, existing studies often rely on weather data in pixel space, which presents several challenges such as smooth outputs in model outputs, limited applicability to a single pressure-variable subset (PVS), and high data storage and computational costs. To address these challenges, we propose a novel Weather Latent Autoencoder (WLA) that transforms weather data from pixel space to latent space, enabling efficient weather task modeling. By decoupling weather reconstruction from downstream tasks, WLA improves the accuracy and sharpness of weather task model results. The incorporated Pressure-Variable Unified Module transforms multiple PVS into a unified representation, enhancing the adaptability of the model in multiple weather scenarios. Furthermore, weather tasks can be performed in a low-storage latent space of WLA rather than a high-storage pixel space, thus significantly reducing data storage and computational costs. Through extensive experimentation, we demonstrate its superior compression and reconstruction performance, enabling the creation of the ERA5-latent dataset with unified representations of multiple PVS from ERA5 data. The compressed full PVS in the ERA5-latent dataset reduces the original 244.34 TB of data to 0.43 TB. The downstream task further demonstrates that task models can apply to multiple PVS with low data costs in latent space and achieve superior performance compared to models in pixel space. Code, ERA5-latent data, and pre-trained models are available at https://anonymous.4open.science/r/Weather-Latent-Autoencoder-8467.
StereoCrafter: Diffusion-based Generation of Long and High-fidelity Stereoscopic 3D from Monocular Videos
Sep 11, 2024



This paper presents a novel framework for converting 2D videos to immersive stereoscopic 3D, addressing the growing demand for 3D content in immersive experience. Leveraging foundation models as priors, our approach overcomes the limitations of traditional methods and boosts the performance to ensure the high-fidelity generation required by the display devices. The proposed system consists of two main steps: depth-based video splatting for warping and extracting occlusion mask, and stereo video inpainting. We utilize pre-trained stable video diffusion as the backbone and introduce a fine-tuning protocol for the stereo video inpainting task. To handle input video with varying lengths and resolutions, we explore auto-regressive strategies and tiled processing. Finally, a sophisticated data processing pipeline has been developed to reconstruct a large-scale and high-quality dataset to support our training. Our framework demonstrates significant improvements in 2D-to-3D video conversion, offering a practical solution for creating immersive content for 3D devices like Apple Vision Pro and 3D displays. In summary, this work contributes to the field by presenting an effective method for generating high-quality stereoscopic videos from monocular input, potentially transforming how we experience digital media.
DepthCrafter: Generating Consistent Long Depth Sequences for Open-world Videos
Sep 03, 2024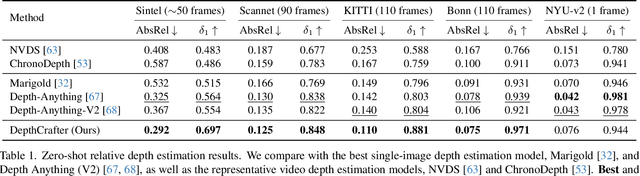
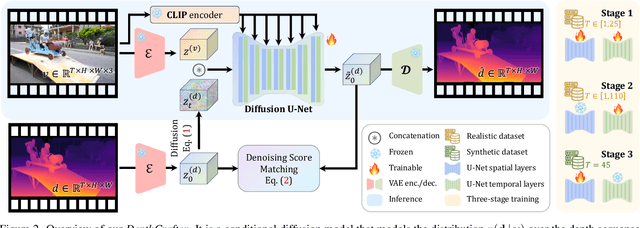
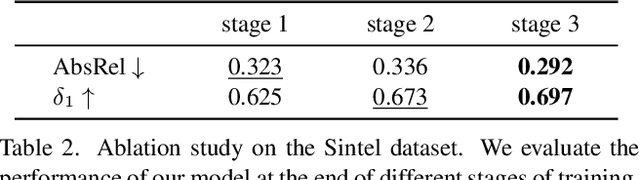
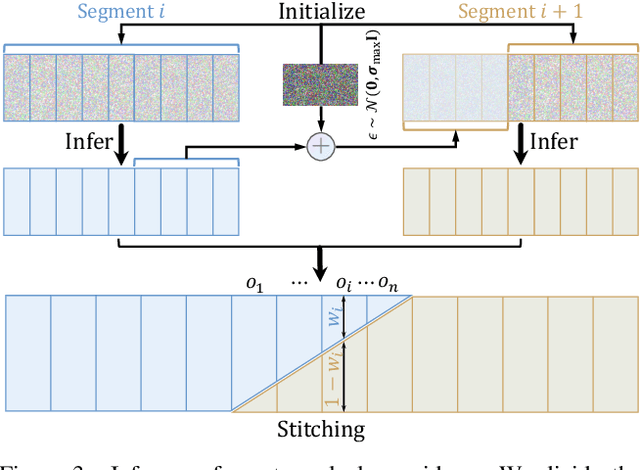
Despite significant advancements in monocular depth estimation for static images, estimating video depth in the open world remains challenging, since open-world videos are extremely diverse in content, motion, camera movement, and length. We present DepthCrafter, an innovative method for generating temporally consistent long depth sequences with intricate details for open-world videos, without requiring any supplementary information such as camera poses or optical flow. DepthCrafter achieves generalization ability to open-world videos by training a video-to-depth model from a pre-trained image-to-video diffusion model, through our meticulously designed three-stage training strategy with the compiled paired video-depth datasets. Our training approach enables the model to generate depth sequences with variable lengths at one time, up to 110 frames, and harvest both precise depth details and rich content diversity from realistic and synthetic datasets. We also propose an inference strategy that processes extremely long videos through segment-wise estimation and seamless stitching. Comprehensive evaluations on multiple datasets reveal that DepthCrafter achieves state-of-the-art performance in open-world video depth estimation under zero-shot settings. Furthermore, DepthCrafter facilitates various downstream applications, including depth-based visual effects and conditional video generation.
VegeDiff: Latent Diffusion Model for Geospatial Vegetation Forecasting
Jul 17, 2024In the context of global climate change and frequent extreme weather events, forecasting future geospatial vegetation states under these conditions is of significant importance. The vegetation change process is influenced by the complex interplay between dynamic meteorological variables and static environmental variables, leading to high levels of uncertainty. Existing deterministic methods are inadequate in addressing this uncertainty and fail to accurately model the impact of these variables on vegetation, resulting in blurry and inaccurate forecasting results. To address these issues, we propose VegeDiff for the geospatial vegetation forecasting task. To our best knowledge, VegeDiff is the first to employ a diffusion model to probabilistically capture the uncertainties in vegetation change processes, enabling the generation of clear and accurate future vegetation states. VegeDiff also separately models the global impact of dynamic meteorological variables and the local effects of static environmental variables, thus accurately modeling the impact of these variables. Extensive experiments on geospatial vegetation forecasting tasks demonstrate the effectiveness of VegeDiff. By capturing the uncertainties in vegetation changes and modeling the complex influence of relevant variables, VegeDiff outperforms existing deterministic methods, providing clear and accurate forecasting results of future vegetation states. Interestingly, we demonstrate the potential of VegeDiff in applications of forecasting future vegetation states from multiple aspects and exploring the impact of meteorological variables on vegetation dynamics. The code of this work will be available at https://github.com/walking-shadow/ Official_VegeDiff.
CV-VAE: A Compatible Video VAE for Latent Generative Video Models
May 30, 2024Spatio-temporal compression of videos, utilizing networks such as Variational Autoencoders (VAE), plays a crucial role in OpenAI's SORA and numerous other video generative models. For instance, many LLM-like video models learn the distribution of discrete tokens derived from 3D VAEs within the VQVAE framework, while most diffusion-based video models capture the distribution of continuous latent extracted by 2D VAEs without quantization. The temporal compression is simply realized by uniform frame sampling which results in unsmooth motion between consecutive frames. Currently, there lacks of a commonly used continuous video (3D) VAE for latent diffusion-based video models in the research community. Moreover, since current diffusion-based approaches are often implemented using pre-trained text-to-image (T2I) models, directly training a video VAE without considering the compatibility with existing T2I models will result in a latent space gap between them, which will take huge computational resources for training to bridge the gap even with the T2I models as initialization. To address this issue, we propose a method for training a video VAE of latent video models, namely CV-VAE, whose latent space is compatible with that of a given image VAE, e.g., image VAE of Stable Diffusion (SD). The compatibility is achieved by the proposed novel latent space regularization, which involves formulating a regularization loss using the image VAE. Benefiting from the latent space compatibility, video models can be trained seamlessly from pre-trained T2I or video models in a truly spatio-temporally compressed latent space, rather than simply sampling video frames at equal intervals. With our CV-VAE, existing video models can generate four times more frames with minimal finetuning. Extensive experiments are conducted to demonstrate the effectiveness of the proposed video VAE.
SEED-Data-Edit Technical Report: A Hybrid Dataset for Instructional Image Editing
May 07, 2024In this technical report, we introduce SEED-Data-Edit: a unique hybrid dataset for instruction-guided image editing, which aims to facilitate image manipulation using open-form language. SEED-Data-Edit is composed of three distinct types of data: (1) High-quality editing data produced by an automated pipeline, ensuring a substantial volume of diverse image editing pairs. (2) Real-world scenario data collected from the internet, which captures the intricacies of user intentions for promoting the practical application of image editing in the real world. (3) High-precision multi-turn editing data annotated by humans, which involves multiple rounds of edits for simulating iterative editing processes. The combination of these diverse data sources makes SEED-Data-Edit a comprehensive and versatile dataset for training language-guided image editing model. We fine-tune a pretrained Multimodal Large Language Model (MLLM) that unifies comprehension and generation with SEED-Data-Edit. The instruction tuned model demonstrates promising results, indicating the potential and effectiveness of SEED-Data-Edit in advancing the field of instructional image editing. The datasets are released in https://huggingface.co/datasets/AILab-CVC/SEED-Data-Edit.
SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation
Apr 22, 2024The rapid evolution of multimodal foundation model has demonstrated significant progresses in vision-language understanding and generation, e.g., our previous work SEED-LLaMA. However, there remains a gap between its capability and the real-world applicability, primarily due to the model's limited capacity to effectively respond to various user instructions and interact with diverse visual data. In this work, we focus on bridging this gap through integrating two enhanced features: (1) comprehending images of arbitrary sizes and ratios, and (2) enabling multi-granularity image generation. We present a unified and versatile foundation model, namely, SEED-X, which is able to model multi-granularity visual semantics for comprehension and generation tasks. Besides the competitive results on public benchmarks, SEED-X demonstrates its effectiveness in handling real-world applications across various domains after instruction tuning. We hope that our work will inspire future research into what can be achieved by versatile multimodal foundation models in real-world applications. The models, codes, and datasets will be released in https://github.com/AILab-CVC/SEED-X.
RS-Mamba for Large Remote Sensing Image Dense Prediction
Apr 10, 2024
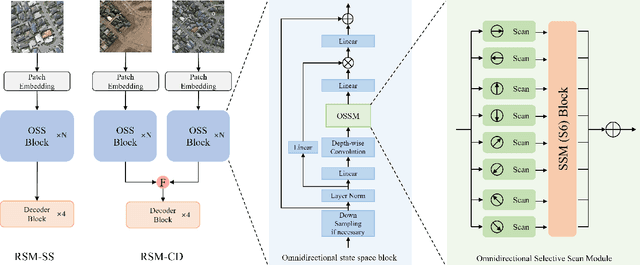
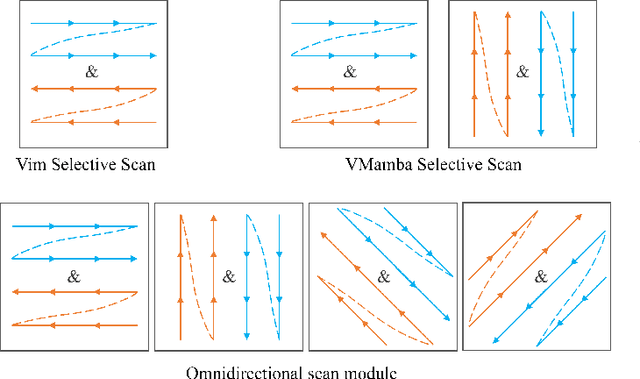
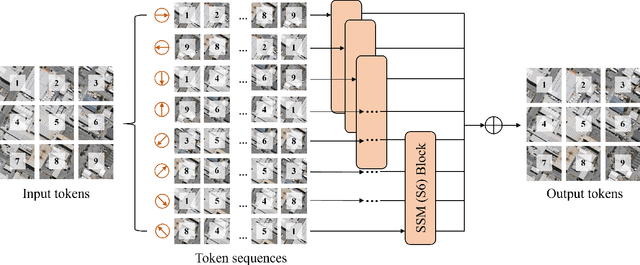
Context modeling is critical for remote sensing image dense prediction tasks. Nowadays, the growing size of very-high-resolution (VHR) remote sensing images poses challenges in effectively modeling context. While transformer-based models possess global modeling capabilities, they encounter computational challenges when applied to large VHR images due to their quadratic complexity. The conventional practice of cropping large images into smaller patches results in a notable loss of contextual information. To address these issues, we propose the Remote Sensing Mamba (RSM) for dense prediction tasks in large VHR remote sensing images. RSM is specifically designed to capture the global context of remote sensing images with linear complexity, facilitating the effective processing of large VHR images. Considering that the land covers in remote sensing images are distributed in arbitrary spatial directions due to characteristics of remote sensing over-head imaging, the RSM incorporates an omnidirectional selective scan module to globally model the context of images in multiple directions, capturing large spatial features from various directions. Extensive experiments on semantic segmentation and change detection tasks across various land covers demonstrate the effectiveness of the proposed RSM. We designed simple yet effective models based on RSM, achieving state-of-the-art performance on dense prediction tasks in VHR remote sensing images without fancy training strategies. Leveraging the linear complexity and global modeling capabilities, RSM achieves better efficiency and accuracy than transformer-based models on large remote sensing images. Interestingly, we also demonstrated that our model generally performs better with a larger image size on dense prediction tasks. Our code is available at https://github.com/walking-shadow/Official_Remote_Sensing_Mamba.