 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerseCrafter: Dynamic Realistic Video World Model with 4D Geometric Control
Jan 08, 2026Video world models aim to simulate dynamic, real-world environments, yet existing methods struggle to provide unified and precise control over camera and multi-object motion, as videos inherently operate dynamics in the projected 2D image plane. To bridge this gap, we introduce VerseCrafter, a 4D-aware video world model that enables explicit and coherent control over both camera and object dynamics within a unified 4D geometric world state. Our approach is centered on a novel 4D Geometric Control representation, which encodes the world state through a static background point cloud and per-object 3D Gaussian trajectories. This representation captures not only an object's path but also its probabilistic 3D occupancy over time, offering a flexible, category-agnostic alternative to rigid bounding boxes or parametric models. These 4D controls are rendered into conditioning signals for a pretrained video diffusion model, enabling the generation of high-fidelity, view-consistent videos that precisely adhere to the specified dynamics. Unfortunately, another major challenge lies in the scarcity of large-scale training data with explicit 4D annotations. We address this by developing an automatic data engine that extracts the required 4D controls from in-the-wild videos, allowing us to train our model on a massive and diverse dataset.
Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models
Dec 23, 2025Vision-language models (VLM) excel at general understanding yet remain weak at dynamic spatial reasoning (DSR), i.e., reasoning about the evolvement of object geometry and relationship in 3D space over time, largely due to the scarcity of scalable 4D-aware training resources. To bridge this gap across aspects of dataset, benchmark and model, we introduce DSR Suite. First, we propose an automated pipeline that generates multiple-choice question-answer pairs from in-the-wild videos for DSR. By leveraging modern vision foundation models, the pipeline extracts rich geometric and motion information, including camera poses, local point clouds, object masks, orientations, and 3D trajectories. These geometric cues enable the construction of DSR-Train for learning and further human-refined DSR-Bench for evaluation. Compared with previous works, our data emphasize (i) in-the-wild video sources, (ii) object- and scene-level 3D requirements, (iii) viewpoint transformations, (iv) multi-object interactions, and (v) fine-grained, procedural answers. Beyond data, we propose a lightweight Geometry Selection Module (GSM) to seamlessly integrate geometric priors into VLMs, which condenses question semantics and extracts question-relevant knowledge from pretrained 4D reconstruction priors into a compact set of geometry tokens. This targeted extraction avoids overwhelming the model with irrelevant knowledge. Experiments show that integrating DSR-Train and GSM into Qwen2.5-VL-7B significantly enhances its dynamic spatial reasoning capability, while maintaining accuracy on general video understanding benchmarks.
TimeLens: Rethinking Video Temporal Grounding with Multimodal LLMs
Dec 16, 2025This paper does not introduce a novel method but instead establishes a straightforward, incremental, yet essential baseline for video temporal grounding (VTG), a core capability in video understanding. While multimodal large language models (MLLMs) excel at various video understanding tasks, the recipes for optimizing them for VTG remain under-explored. In this paper, we present TimeLens, a systematic investigation into building MLLMs with strong VTG ability, along two primary dimensions: data quality and algorithmic design. We first expose critical quality issues in existing VTG benchmarks and introduce TimeLens-Bench, comprising meticulously re-annotated versions of three popular benchmarks with strict quality criteria. Our analysis reveals dramatic model re-rankings compared to legacy benchmarks, confirming the unreliability of prior evaluation standards. We also address noisy training data through an automated re-annotation pipeline, yielding TimeLens-100K, a large-scale, high-quality training dataset. Building on our data foundation, we conduct in-depth explorations of algorithmic design principles, yielding a series of meaningful insights and effective yet efficient practices. These include interleaved textual encoding for time representation, a thinking-free reinforcement learning with verifiable rewards (RLVR) approach as the training paradigm, and carefully designed recipes for RLVR training. These efforts culminate in TimeLens models, a family of MLLMs with state-of-the-art VTG performance among open-source models and even surpass proprietary models such as GPT-5 and Gemini-2.5-Flash. All codes, data, and models will be released to facilitate future research.
MMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


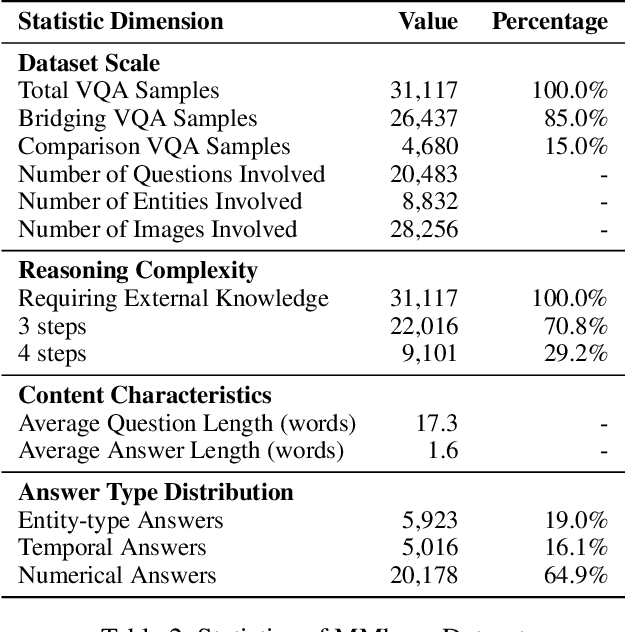
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.
ARC-Chapter: Structuring Hour-Long Videos into Navigable Chapters and Hierarchical Summaries
Nov 18, 2025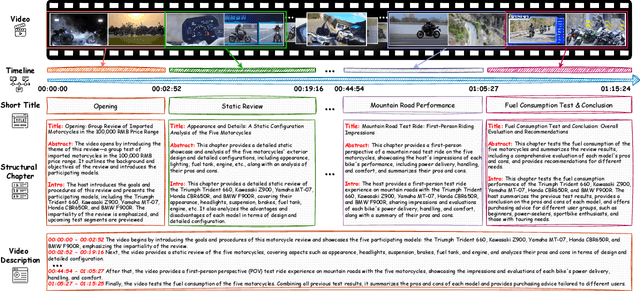
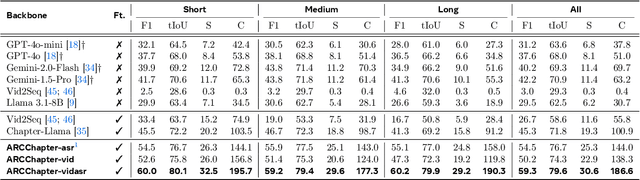
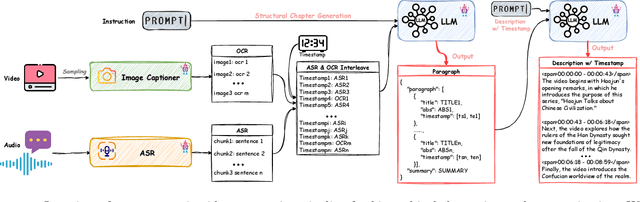
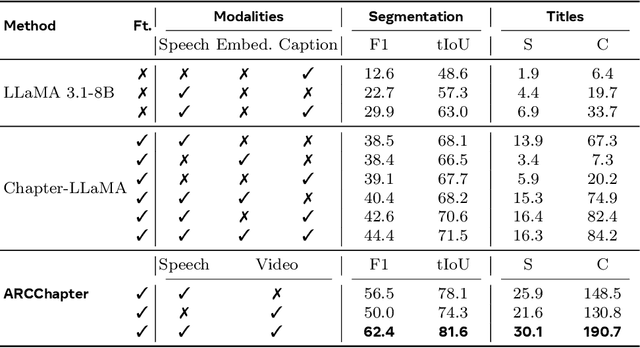
The proliferation of hour-long videos (e.g., lectures, podcasts, documentaries) has intensified demand for efficient content structuring. However, existing approaches are constrained by small-scale training with annotations that are typical short and coarse, restricting generalization to nuanced transitions in long videos. We introduce ARC-Chapter, the first large-scale video chaptering model trained on over million-level long video chapters, featuring bilingual, temporally grounded, and hierarchical chapter annotations. To achieve this goal, we curated a bilingual English-Chinese chapter dataset via a structured pipeline that unifies ASR transcripts, scene texts, visual captions into multi-level annotations, from short title to long summaries. We demonstrate clear performance improvements with data scaling, both in data volume and label intensity. Moreover, we design a new evaluation metric termed GRACE, which incorporates many-to-one segment overlaps and semantic similarity, better reflecting real-world chaptering flexibility. Extensive experiments demonstrate that ARC-Chapter establishes a new state-of-the-art by a significant margin, outperforming the previous best by 14.0% in F1 score and 11.3% in SODA score. Moreover, ARC-Chapter shows excellent transferability, improving the state-of-the-art on downstream tasks like dense video captioning on YouCook2.
AudioStory: Generating Long-Form Narrative Audio with Large Language Models
Aug 27, 2025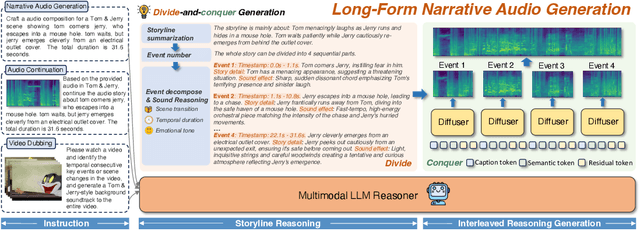
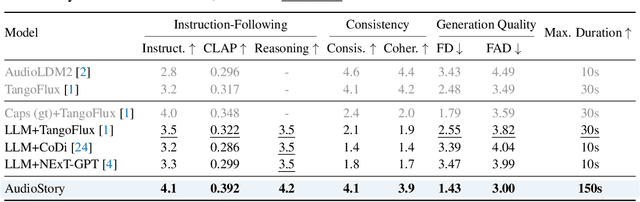
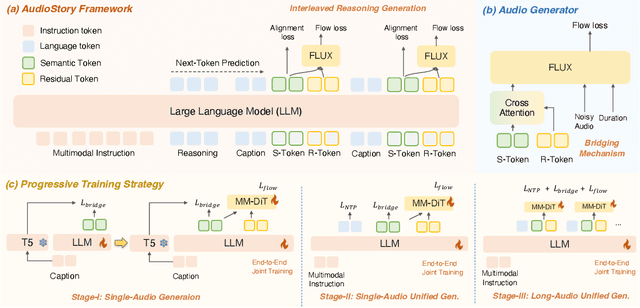

Recent advances in text-to-audio (TTA) generation excel at synthesizing short audio clips but struggle with long-form narrative audio, which requires temporal coherence and compositional reasoning. To address this gap, we propose AudioStory, a unified framework that integrates large language models (LLMs) with TTA systems to generate structured, long-form audio narratives. AudioStory possesses strong instruction-following reasoning generation capabilities. It employs LLMs to decompose complex narrative queries into temporally ordered sub-tasks with contextual cues, enabling coherent scene transitions and emotional tone consistency. AudioStory has two appealing features: (1) Decoupled bridging mechanism: AudioStory disentangles LLM-diffuser collaboration into two specialized components, i.e., a bridging query for intra-event semantic alignment and a residual query for cross-event coherence preservation. (2) End-to-end training: By unifying instruction comprehension and audio generation within a single end-to-end framework, AudioStory eliminates the need for modular training pipelines while enhancing synergy between components. Furthermore, we establish a benchmark AudioStory-10K, encompassing diverse domains such as animated soundscapes and natural sound narratives. Extensive experiments show the superiority of AudioStory on both single-audio generation and narrative audio generation, surpassing prior TTA baselines in both instruction-following ability and audio fidelity. Our code is available at https://github.com/TencentARC/AudioStory
ToonComposer: Streamlining Cartoon Production with Generative Post-Keyframing
Aug 14, 2025
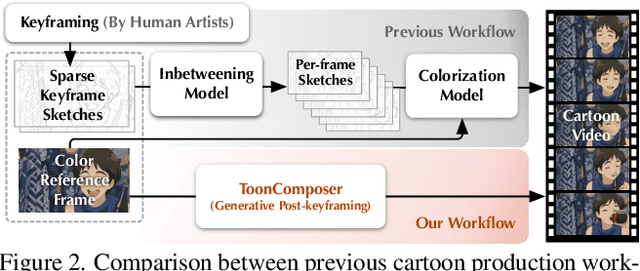
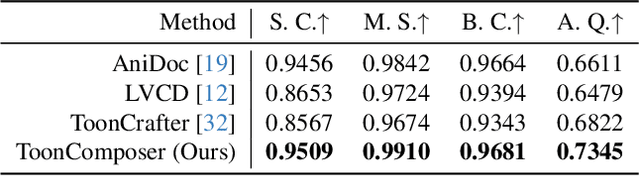
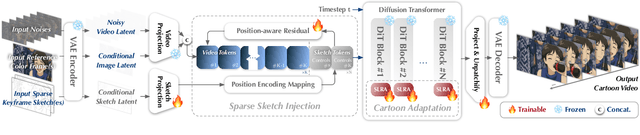
Traditional cartoon and anime production involves keyframing, inbetweening, and colorization stages, which require intensive manual effort. Despite recent advances in AI, existing methods often handle these stages separately, leading to error accumulation and artifacts. For instance, inbetweening approaches struggle with large motions, while colorization methods require dense per-frame sketches. To address this, we introduce ToonComposer, a generative model that unifies inbetweening and colorization into a single post-keyframing stage. ToonComposer employs a sparse sketch injection mechanism to provide precise control using keyframe sketches. Additionally, it uses a cartoon adaptation method with the spatial low-rank adapter to tailor a modern video foundation model to the cartoon domain while keeping its temporal prior intact. Requiring as few as a single sketch and a colored reference frame, ToonComposer excels with sparse inputs, while also supporting multiple sketches at any temporal location for more precise motion control. This dual capability reduces manual workload and improves flexibility, empowering artists in real-world scenarios. To evaluate our model, we further created PKBench, a benchmark featuring human-drawn sketches that simulate real-world use cases. Our evaluation demonstrates that ToonComposer outperforms existing methods in visual quality, motion consistency, and production efficiency, offering a superior and more flexible solution for AI-assisted cartoon production.
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
IC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
DepthSync: Diffusion Guidance-Based Depth Synchronization for Scale- and Geometry-Consistent Video Depth Estimation
Jul 02, 2025
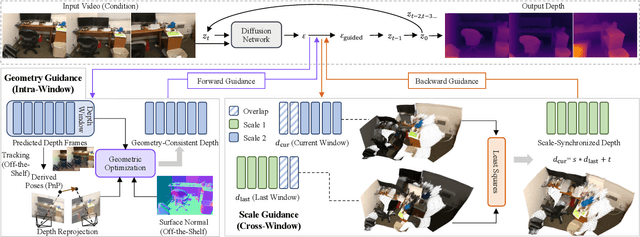

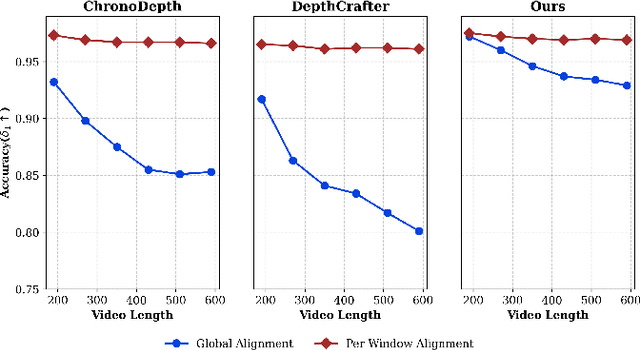
Diffusion-based video depth estimation methods have achieved remarkable success with strong generalization ability. However, predicting depth for long videos remains challenging. Existing methods typically split videos into overlapping sliding windows, leading to accumulated scale discrepancies across different windows, particularly as the number of windows increases. Additionally, these methods rely solely on 2D diffusion priors, overlooking the inherent 3D geometric structure of video depths, which results in geometrically inconsistent predictions. In this paper, we propose DepthSync, a novel, training-free framework using diffusion guidance to achieve scale- and geometry-consistent depth predictions for long videos. Specifically, we introduce scale guidance to synchronize the depth scale across windows and geometry guidance to enforce geometric alignment within windows based on the inherent 3D constraints in video depths. These two terms work synergistically, steering the denoising process toward consistent depth predictions. Experiments on various datasets validate the effectiveness of our method in producing depth estimates with improved scale and geometry consistency, particularly for long videos.