 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMs are Good Teachers for Video Reasoning via Adaptive Test-Time Optimization
Jun 01, 2026The recent "Reasoning with Video" paradigm utilizes Video Generation Models (VGMs) to generate temporally coherent visual trajectories to complete reasoning tasks. Although state-of-the-art VGMs excel at visual quality, they often struggle to understand and follow task-specific rules, leading to logical failures across diverse reasoning scenarios. Existing efforts try to utilize Vision-Language Models (VLMs) as problem pre-solvers to produce or refine textual guidance for the VGM. However, textual descriptions fail to capture intricate spatiotemporal details, and VGMs often struggle to faithfully execute fine-grained or long-tail instructions even with a valid plan. While VLMs struggle as solvers, they possess strong perception capabilities to evaluate process-constraint satisfaction and final-goal achievement. Leveraging this strength, we introduce a paradigm shift that transitions the role of VLMs to "teachers". Specifically, a VLM teacher extracts task-specific rules to formulate differentiable rewards, guiding a VGM Reasoner via test-time online optimization of a lightweight LoRA module. This strategy enables adaptive test-time optimization and extends the reasoning capabilities beyond the VGM's intrinsic boundaries. Evaluations on symbolic (VBVR-Bench) and general-purpose (RULER-Bench) video reasoning benchmarks show that the proposed method yields a 16.7-point average performance gain, outperforming the VLM-as-Solver paradigm (+0.4 points) and Best-of-N scaling (+2.2 points) by a large margin at comparable test-time cost. These findings reveal that integrating VLMs as test-time teachers offers a promising paradigm for achieving generalizable video reasoning. Project Page: https://VLM-as-Teacher.github.io/
Video-Holmes: Can MLLM Think Like Holmes for Complex Video Reasoning?
May 27, 2025Recent advances in CoT reasoning and RL post-training have been reported to enhance video reasoning capabilities of MLLMs. This progress naturally raises a question: can these models perform complex video reasoning in a manner comparable to human experts? However, existing video benchmarks primarily evaluate visual perception and grounding abilities, with questions that can be answered based on explicit prompts or isolated visual cues. Such benchmarks do not fully capture the intricacies of real-world reasoning, where humans must actively search for, integrate, and analyze multiple clues before reaching a conclusion. To address this issue, we present Video-Holmes, a benchmark inspired by the reasoning process of Sherlock Holmes, designed to evaluate the complex video reasoning capabilities of MLLMs. Video-Holmes consists of 1,837 questions derived from 270 manually annotated suspense short films, which spans seven carefully designed tasks. Each task is constructed by first identifying key events and causal relationships within films, and then designing questions that require models to actively locate and connect multiple relevant visual clues scattered across different video segments. Our comprehensive evaluation of state-of-the-art MLLMs reveals that, while these models generally excel at visual perception, they encounter substantial difficulties with integrating information and often miss critical clues. For example, the best-performing model, Gemini-2.5-Pro, achieves an accuracy of only 45%, with most models scoring below 40%. We aim that Video-Holmes can serve as a "Holmes-test" for multimodal reasoning, motivating models to reason more like humans and emphasizing the ongoing challenges in this field. The benchmark is released in https://github.com/TencentARC/Video-Holmes.
AnimeGamer: Infinite Anime Life Simulation with Next Game State Prediction
Apr 01, 2025Recent advancements in image and video synthesis have opened up new promise in generative games. One particularly intriguing application is transforming characters from anime films into interactive, playable entities. This allows players to immerse themselves in the dynamic anime world as their favorite characters for life simulation through language instructions. Such games are defined as infinite game since they eliminate predetermined boundaries and fixed gameplay rules, where players can interact with the game world through open-ended language and experience ever-evolving storylines and environments. Recently, a pioneering approach for infinite anime life simulation employs large language models (LLMs) to translate multi-turn text dialogues into language instructions for image generation. However, it neglects historical visual context, leading to inconsistent gameplay. Furthermore, it only generates static images, failing to incorporate the dynamics necessary for an engaging gaming experience. In this work, we propose AnimeGamer, which is built upon Multimodal Large Language Models (MLLMs) to generate each game state, including dynamic animation shots that depict character movements and updates to character states, as illustrated in Figure 1. We introduce novel action-aware multimodal representations to represent animation shots, which can be decoded into high-quality video clips using a video diffusion model. By taking historical animation shot representations as context and predicting subsequent representations, AnimeGamer can generate games with contextual consistency and satisfactory dynamics. Extensive evaluations using both automated metrics and human evaluations demonstrate that AnimeGamer outperforms existing methods in various aspects of the gaming experience. Codes and checkpoints are available at https://github.com/TencentARC/AnimeGamer.
Object Isolated Attention for Consistent Story Visualization
Mar 30, 2025Open-ended story visualization is a challenging task that involves generating coherent image sequences from a given storyline. One of the main difficulties is maintaining character consistency while creating natural and contextually fitting scenes--an area where many existing methods struggle. In this paper, we propose an enhanced Transformer module that uses separate self attention and cross attention mechanisms, leveraging prior knowledge from pre-trained diffusion models to ensure logical scene creation. The isolated self attention mechanism improves character consistency by refining attention maps to reduce focus on irrelevant areas and highlight key features of the same character. Meanwhile, the isolated cross attention mechanism independently processes each character's features, avoiding feature fusion and further strengthening consistency. Notably, our method is training-free, allowing the continuous generation of new characters and storylines without re-tuning. Both qualitative and quantitative evaluations show that our approach outperforms current methods, demonstrating its effectiveness.
BD-Diff: Generative Diffusion Model for Image Deblurring on Unknown Domains with Blur-Decoupled Learning
Feb 03, 2025



Generative diffusion models trained on large-scale datasets have achieved remarkable progress in image synthesis. In favor of their ability to supplement missing details and generate aesthetically pleasing contents, recent works have applied them to image deblurring tasks via training an adapter on blurry-sharp image pairs to provide structural conditions for restoration. However, acquiring substantial amounts of realistic paired data is challenging and costly in real-world scenarios. On the other hand, relying solely on synthetic data often results in overfitting, leading to unsatisfactory performance when confronted with unseen blur patterns. To tackle this issue, we propose BD-Diff, a generative-diffusion-based model designed to enhance deblurring performance on unknown domains by decoupling structural features and blur patterns through joint training on three specially designed tasks. We employ two Q-Formers as structural representations and blur patterns extractors separately. The features extracted by them will be used for the supervised deblurring task on synthetic data and the unsupervised blur-transfer task by leveraging unpaired blurred images from the target domain simultaneously. Furthermore, we introduce a reconstruction task to make the structural features and blur patterns complementary. This blur-decoupled learning process enhances the generalization capabilities of BD-Diff when encountering unknown domain blur patterns. Experiments on real-world datasets demonstrate that BD-Diff outperforms existing state-of-the-art methods in blur removal and structural preservation in various challenging scenarios. The codes will be released in https://github.com/donahowe/BD-Diff
AutoStudio: Crafting Consistent Subjects in Multi-turn Interactive Image Generation
Jun 03, 2024As cutting-edge Text-to-Image (T2I) generation models already excel at producing remarkable single images, an even more challenging task, i.e., multi-turn interactive image generation begins to attract the attention of related research communities. This task requires models to interact with users over multiple turns to generate a coherent sequence of images. However, since users may switch subjects frequently, current efforts struggle to maintain subject consistency while generating diverse images. To address this issue, we introduce a training-free multi-agent framework called AutoStudio. AutoStudio employs three agents based on large language models (LLMs) to handle interactions, along with a stable diffusion (SD) based agent for generating high-quality images. Specifically, AutoStudio consists of (i) a subject manager to interpret interaction dialogues and manage the context of each subject, (ii) a layout generator to generate fine-grained bounding boxes to control subject locations, (iii) a supervisor to provide suggestions for layout refinements, and (iv) a drawer to complete image generation. Furthermore, we introduce a Parallel-UNet to replace the original UNet in the drawer, which employs two parallel cross-attention modules for exploiting subject-aware features. We also introduce a subject-initialized generation method to better preserve small subjects. Our AutoStudio hereby can generate a sequence of multi-subject images interactively and consistently. Extensive experiments on the public CMIGBench benchmark and human evaluations show that AutoStudio maintains multi-subject consistency across multiple turns well, and it also raises the state-of-the-art performance by 13.65% in average Frechet Inception Distance and 2.83% in average character-character similarity.
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Apr 29, 2024



Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a "Screenwriter", engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the "Rehearsal". Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the "Final Performance". With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
Pyramid Scale Network for Crowd Counting
Jul 11, 2020



Crowd counting is a challenging task in computer vision due to serious occlusions, complex background and large scale variations, etc. Multi-column architecture is widely adopted to overcome these challenges, yielding state-of-the-art performance in many public benchmarks. However, there still are two issues in such design: scale limitation and feature similarity. Further performance improvements are thus restricted. In this paper, we propose a novel crowd counting framework called Pyramid Scale Network (PSNet) to explicitly address these issues. Specifically, for scale limitation, we adopt three Pyramid Scale Module (PSM) to efficiently capture multi-scale features, which integrate a message passing mechanism and an attention mechanism into multi-column architecture. Moreover, for feature similarity, a Differential loss is introduced to make the features learned by each column in PSM appropriately different from each other. To the best of our knowledge, PSNet is the first work to explicitly address scale limitation and feature similarity in multi-column design. Extensive experiments on five benchmark datasets demonstrate the effectiveness of the proposed innovations as well as the superior performance over the state-of-the-art. Our code is publicly available at: https://github.com/JunhaoCheng/Pyramid_Scale_Network
Deep Density-aware Count Regressor
Aug 09, 2019
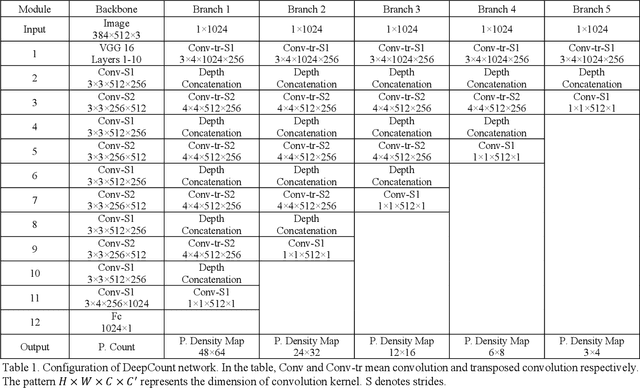
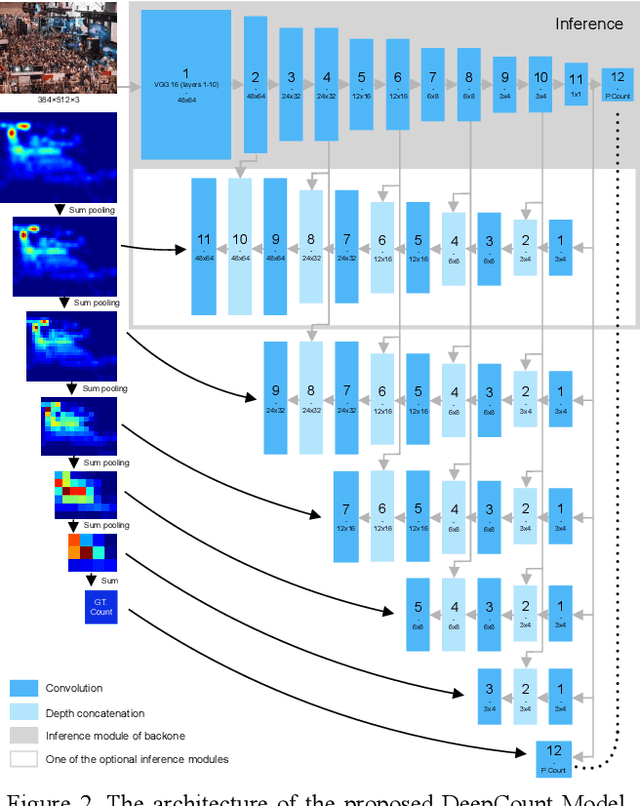
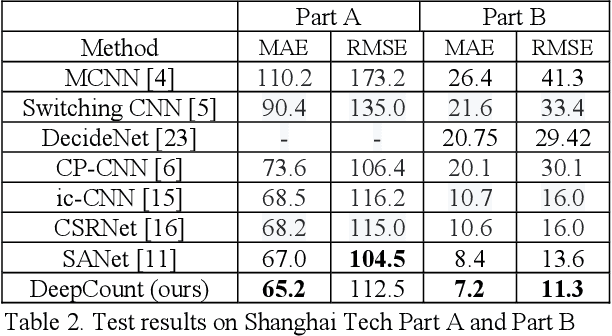
We seek to improve crowd counting as we perceive limits of currently prevalent density map estimation approach on both prediction accuracy and time efficiency. We show that a CNN regressing a global count trained with density map supervision can make more accurate prediction. We introduce multilayer gradient fusion for training a densityaware global count regressor. More specifically, on training stage, a backbone network receives gradients from multiple branches to learn the density information, whereas those branches are to be detached to accelerate inference. By taking advantages of such method, our model improves benchmark results on public datasets and exhibits itself to be a new solution to crowd counting problem in practice.