 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustVisRAG: Causality-Aware Vision-Based Retrieval-Augmented Generation under Visual Degradations
Feb 25, 2026Vision-based Retrieval-Augmented Generation (VisRAG) leverages vision-language models (VLMs) to jointly retrieve relevant visual documents and generate grounded answers based on multimodal evidence. However, existing VisRAG models degrade in performance when visual inputs suffer from distortions such as blur, noise, low light, or shadow, where semantic and degradation factors become entangled within pretrained visual encoders, leading to errors in both retrieval and generation stages. To address this limitation, we introduce RobustVisRAG, a causality-guided dual-path framework that improves VisRAG robustness while preserving efficiency and zero-shot generalization. RobustVisRAG uses a non-causal path to capture degradation signals through unidirectional attention and a causal path to learn purified semantics guided by these signals. Together with the proposed Non-Causal Distortion Modeling and Causal Semantic Alignment objectives, the framework enforces a clear separation between semantics and degradations, enabling stable retrieval and generation under challenging visual conditions. To evaluate robustness under realistic conditions, we introduce the Distortion-VisRAG dataset, a large-scale benchmark containing both synthetic and real-world degraded documents across seven domains, with 12 synthetic and 5 real distortion types that comprehensively reflect practical visual degradations. Experimental results show that RobustVisRAG improves retrieval, generation, and end-to-end performance by 7.35%, 6.35%, and 12.40%, respectively, on real-world degradations, while maintaining comparable accuracy on clean inputs.
Learning Representations of Satellite Images with Evaluations on Synoptic Weather Events
Aug 08, 2025This study applied representation learning algorithms to satellite images and evaluated the learned latent spaces with classifications of various weather events. The algorithms investigated include the classical linear transformation, i.e., principal component analysis (PCA), state-of-the-art deep learning method, i.e., convolutional autoencoder (CAE), and a residual network pre-trained with large image datasets (PT). The experiment results indicated that the latent space learned by CAE consistently showed higher threat scores for all classification tasks. The classifications with PCA yielded high hit rates but also high false-alarm rates. In addition, the PT performed exceptionally well at recognizing tropical cyclones but was inferior in other tasks. Further experiments suggested that representations learned from higher-resolution datasets are superior in all classification tasks for deep-learning algorithms, i.e., CAE and PT. We also found that smaller latent space sizes had minor impact on the classification task's hit rate. Still, a latent space dimension smaller than 128 caused a significantly higher false alarm rate. Though the CAE can learn latent spaces effectively and efficiently, the interpretation of the learned representation lacks direct connections to physical attributions. Therefore, developing a physics-informed version of CAE can be a promising outlook for the current work.
DiffVQA: Video Quality Assessment Using Diffusion Feature Extractor
May 06, 2025Video Quality Assessment (VQA) aims to evaluate video quality based on perceptual distortions and human preferences. Despite the promising performance of existing methods using Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), they often struggle to align closely with human perceptions, particularly in diverse real-world scenarios. This challenge is exacerbated by the limited scale and diversity of available datasets. To address this limitation, we introduce a novel VQA framework, DiffVQA, which harnesses the robust generalization capabilities of diffusion models pre-trained on extensive datasets. Our framework adapts these models to reconstruct identical input frames through a control module. The adapted diffusion model is then used to extract semantic and distortion features from a resizing branch and a cropping branch, respectively. To enhance the model's ability to handle long-term temporal dynamics, a parallel Mamba module is introduced, which extracts temporal coherence augmented features that are merged with the diffusion features to predict the final score. Experiments across multiple datasets demonstrate DiffVQA's superior performance on intra-dataset evaluations and its exceptional generalization across datasets. These results confirm that leveraging a diffusion model as a feature extractor can offer enhanced VQA performance compared to CNN and ViT backbones.
BD-Diff: Generative Diffusion Model for Image Deblurring on Unknown Domains with Blur-Decoupled Learning
Feb 03, 2025



Generative diffusion models trained on large-scale datasets have achieved remarkable progress in image synthesis. In favor of their ability to supplement missing details and generate aesthetically pleasing contents, recent works have applied them to image deblurring tasks via training an adapter on blurry-sharp image pairs to provide structural conditions for restoration. However, acquiring substantial amounts of realistic paired data is challenging and costly in real-world scenarios. On the other hand, relying solely on synthetic data often results in overfitting, leading to unsatisfactory performance when confronted with unseen blur patterns. To tackle this issue, we propose BD-Diff, a generative-diffusion-based model designed to enhance deblurring performance on unknown domains by decoupling structural features and blur patterns through joint training on three specially designed tasks. We employ two Q-Formers as structural representations and blur patterns extractors separately. The features extracted by them will be used for the supervised deblurring task on synthetic data and the unsupervised blur-transfer task by leveraging unpaired blurred images from the target domain simultaneously. Furthermore, we introduce a reconstruction task to make the structural features and blur patterns complementary. This blur-decoupled learning process enhances the generalization capabilities of BD-Diff when encountering unknown domain blur patterns. Experiments on real-world datasets demonstrate that BD-Diff outperforms existing state-of-the-art methods in blur removal and structural preservation in various challenging scenarios. The codes will be released in https://github.com/donahowe/BD-Diff
RobustSAM: Segment Anything Robustly on Degraded Images
Jun 13, 2024Segment Anything Model (SAM) has emerged as a transformative approach in image segmentation, acclaimed for its robust zero-shot segmentation capabilities and flexible prompting system. Nonetheless, its performance is challenged by images with degraded quality. Addressing this limitation, we propose the Robust Segment Anything Model (RobustSAM), which enhances SAM's performance on low-quality images while preserving its promptability and zero-shot generalization. Our method leverages the pre-trained SAM model with only marginal parameter increments and computational requirements. The additional parameters of RobustSAM can be optimized within 30 hours on eight GPUs, demonstrating its feasibility and practicality for typical research laboratories. We also introduce the Robust-Seg dataset, a collection of 688K image-mask pairs with different degradations designed to train and evaluate our model optimally. Extensive experiments across various segmentation tasks and datasets confirm RobustSAM's superior performance, especially under zero-shot conditions, underscoring its potential for extensive real-world application. Additionally, our method has been shown to effectively improve the performance of SAM-based downstream tasks such as single image dehazing and deblurring.
DSL-FIQA: Assessing Facial Image Quality via Dual-Set Degradation Learning and Landmark-Guided Transformer
Jun 13, 2024Generic Face Image Quality Assessment (GFIQA) evaluates the perceptual quality of facial images, which is crucial in improving image restoration algorithms and selecting high-quality face images for downstream tasks. We present a novel transformer-based method for GFIQA, which is aided by two unique mechanisms. First, a Dual-Set Degradation Representation Learning (DSL) mechanism uses facial images with both synthetic and real degradations to decouple degradation from content, ensuring generalizability to real-world scenarios. This self-supervised method learns degradation features on a global scale, providing a robust alternative to conventional methods that use local patch information in degradation learning. Second, our transformer leverages facial landmarks to emphasize visually salient parts of a face image in evaluating its perceptual quality. We also introduce a balanced and diverse Comprehensive Generic Face IQA (CGFIQA-40k) dataset of 40K images carefully designed to overcome the biases, in particular the imbalances in skin tone and gender representation, in existing datasets. Extensive analysis and evaluation demonstrate the robustness of our method, marking a significant improvement over prior methods.
Improving Point-based Crowd Counting and Localization Based on Auxiliary Point Guidance
May 17, 2024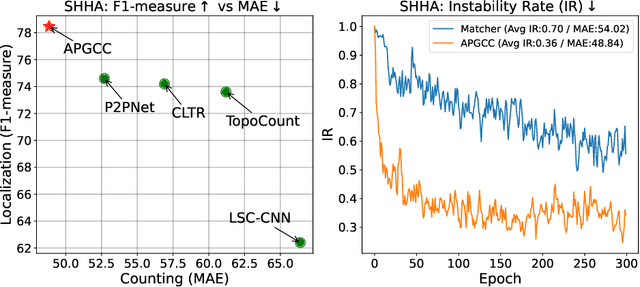
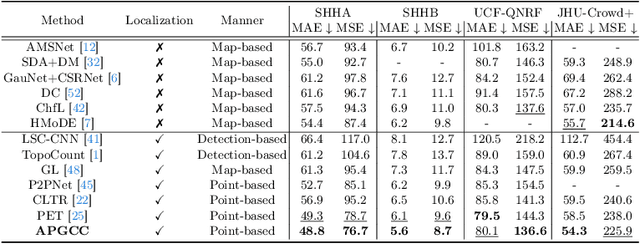
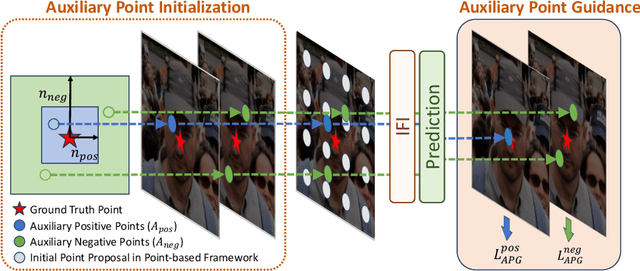
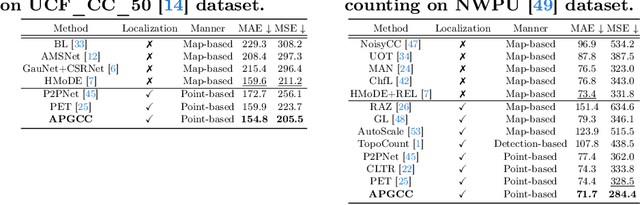
Crowd counting and localization have become increasingly important in computer vision due to their wide-ranging applications. While point-based strategies have been widely used in crowd counting methods, they face a significant challenge, i.e., the lack of an effective learning strategy to guide the matching process. This deficiency leads to instability in matching point proposals to target points, adversely affecting overall performance. To address this issue, we introduce an effective approach to stabilize the proposal-target matching in point-based methods. We propose Auxiliary Point Guidance (APG) to provide clear and effective guidance for proposal selection and optimization, addressing the core issue of matching uncertainty. Additionally, we develop Implicit Feature Interpolation (IFI) to enable adaptive feature extraction in diverse crowd scenarios, further enhancing the model's robustness and accuracy. Extensive experiments demonstrate the effectiveness of our approach, showing significant improvements in crowd counting and localization performance, particularly under challenging conditions. The source codes and trained models will be made publicly available.
Counting Crowds in Bad Weather
Jun 02, 2023Crowd counting has recently attracted significant attention in the field of computer vision due to its wide applications to image understanding. Numerous methods have been proposed and achieved state-of-the-art performance for real-world tasks. However, existing approaches do not perform well under adverse weather such as haze, rain, and snow since the visual appearances of crowds in such scenes are drastically different from those images in clear weather of typical datasets. In this paper, we propose a method for robust crowd counting in adverse weather scenarios. Instead of using a two-stage approach that involves image restoration and crowd counting modules, our model learns effective features and adaptive queries to account for large appearance variations. With these weather queries, the proposed model can learn the weather information according to the degradation of the input image and optimize with the crowd counting module simultaneously. Experimental results show that the proposed algorithm is effective in counting crowds under different weather types on benchmark datasets. The source code and trained models will be made available to the public.
DehazeNeRF: Multiple Image Haze Removal and 3D Shape Reconstruction using Neural Radiance Fields
Mar 20, 2023



Neural radiance fields (NeRFs) have demonstrated state-of-the-art performance for 3D computer vision tasks, including novel view synthesis and 3D shape reconstruction. However, these methods fail in adverse weather conditions. To address this challenge, we introduce DehazeNeRF as a framework that robustly operates in hazy conditions. DehazeNeRF extends the volume rendering equation by adding physically realistic terms that model atmospheric scattering. By parameterizing these terms using suitable networks that match the physical properties, we introduce effective inductive biases, which, together with the proposed regularizations, allow DehazeNeRF to demonstrate successful multi-view haze removal, novel view synthesis, and 3D shape reconstruction where existing approaches fail.
RVSL: Robust Vehicle Similarity Learning in Real Hazy Scenes Based on Semi-supervised Learning
Sep 18, 2022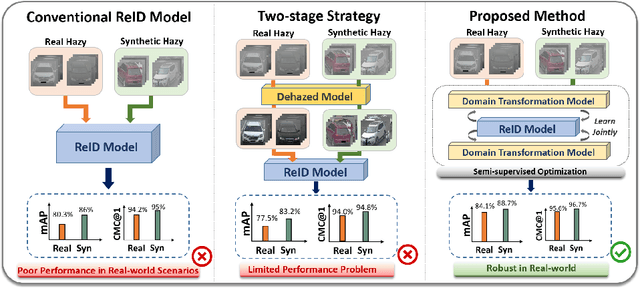

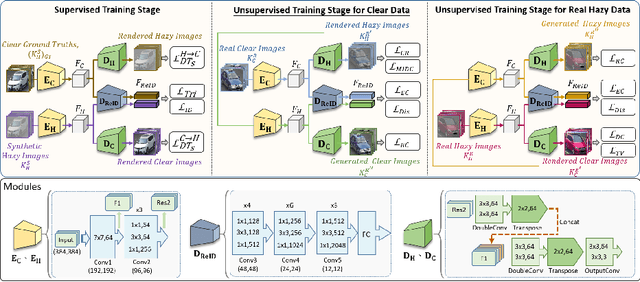

Recently, vehicle similarity learning, also called re-identification (ReID), has attracted significant attention in computer vision. Several algorithms have been developed and obtained considerable success. However, most existing methods have unpleasant performance in the hazy scenario due to poor visibility. Though some strategies are possible to resolve this problem, they still have room to be improved due to the limited performance in real-world scenarios and the lack of real-world clear ground truth. Thus, to resolve this problem, inspired by CycleGAN, we construct a training paradigm called \textbf{RVSL} which integrates ReID and domain transformation techniques. The network is trained on semi-supervised fashion and does not require to employ the ID labels and the corresponding clear ground truths to learn hazy vehicle ReID mission in the real-world haze scenes. To further constrain the unsupervised learning process effectively, several losses are developed. Experimental results on synthetic and real-world datasets indicate that the proposed method can achieve state-of-the-art performance on hazy vehicle ReID problems. It is worth mentioning that although the proposed method is trained without real-world label information, it can achieve competitive performance compared to existing supervised methods trained on complete label information.