 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRVSL: Robust Vehicle Similarity Learning in Real Hazy Scenes Based on Semi-supervised Learning
Sep 18, 2022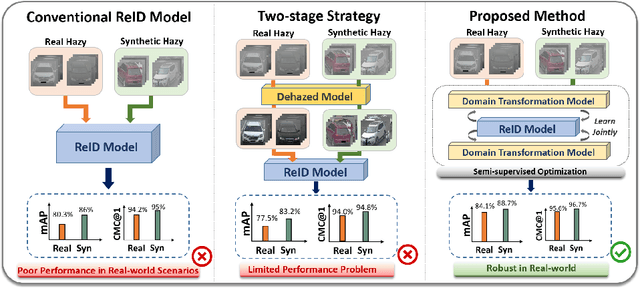

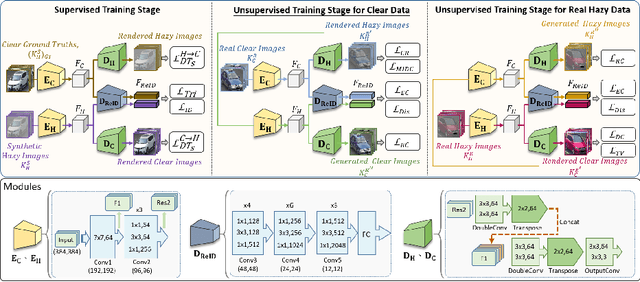

Recently, vehicle similarity learning, also called re-identification (ReID), has attracted significant attention in computer vision. Several algorithms have been developed and obtained considerable success. However, most existing methods have unpleasant performance in the hazy scenario due to poor visibility. Though some strategies are possible to resolve this problem, they still have room to be improved due to the limited performance in real-world scenarios and the lack of real-world clear ground truth. Thus, to resolve this problem, inspired by CycleGAN, we construct a training paradigm called \textbf{RVSL} which integrates ReID and domain transformation techniques. The network is trained on semi-supervised fashion and does not require to employ the ID labels and the corresponding clear ground truths to learn hazy vehicle ReID mission in the real-world haze scenes. To further constrain the unsupervised learning process effectively, several losses are developed. Experimental results on synthetic and real-world datasets indicate that the proposed method can achieve state-of-the-art performance on hazy vehicle ReID problems. It is worth mentioning that although the proposed method is trained without real-world label information, it can achieve competitive performance compared to existing supervised methods trained on complete label information.
LAFFNet: A Lightweight Adaptive Feature Fusion Network for Underwater Image Enhancement
May 05, 2021
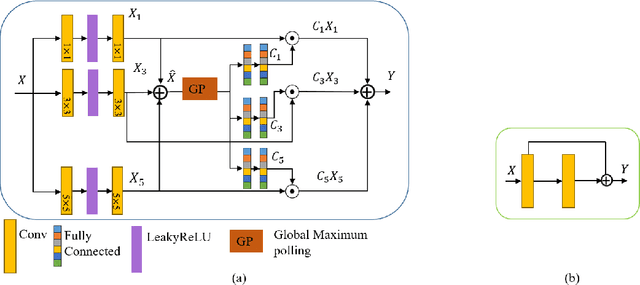
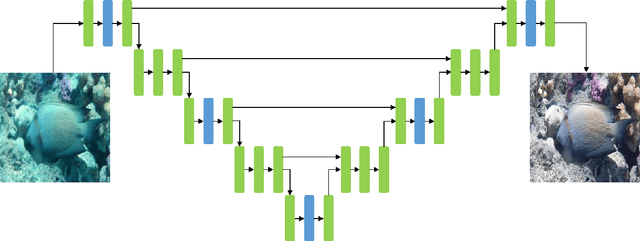

Underwater image enhancement is an important low-level computer vision task for autonomous underwater vehicles and remotely operated vehicles to explore and understand the underwater environments. Recently, deep convolutional neural networks (CNNs) have been successfully used in many computer vision problems, and so does underwater image enhancement. There are many deep-learning-based methods with impressive performance for underwater image enhancement, but their memory and model parameter costs are hindrances in practical application. To address this issue, we propose a lightweight adaptive feature fusion network (LAFFNet). The model is the encoder-decoder model with multiple adaptive feature fusion (AAF) modules. AAF subsumes multiple branches with different kernel sizes to generate multi-scale feature maps. Furthermore, channel attention is used to merge these feature maps adaptively. Our method reduces the number of parameters from 2.5M to 0.15M (around 94% reduction) but outperforms state-of-the-art algorithms by extensive experiments. Furthermore, we demonstrate our LAFFNet effectively improves high-level vision tasks like salience object detection and single image depth estimation.
Multi-modal Bifurcated Network for Depth Guided Image Relighting
May 05, 2021

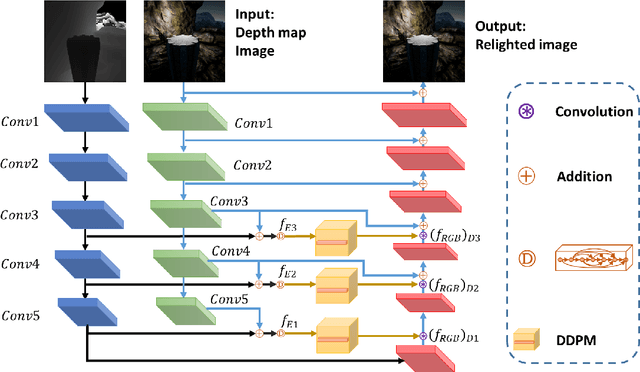
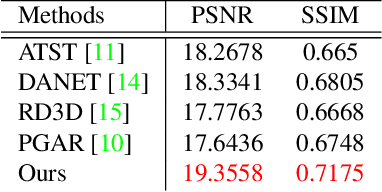
Image relighting aims to recalibrate the illumination setting in an image. In this paper, we propose a deep learning-based method called multi-modal bifurcated network (MBNet) for depth guided image relighting. That is, given an image and the corresponding depth maps, a new image with the given illuminant angle and color temperature is generated by our network. This model extracts the image and the depth features by the bifurcated network in the encoder. To use the two features effectively, we adopt the dynamic dilated pyramid modules in the decoder. Moreover, to increase the variety of training data, we propose a novel data process pipeline to increase the number of the training data. Experiments conducted on the VIDIT dataset show that the proposed solution obtains the \textbf{1}$^{st}$ place in terms of SSIM and PMS in the NTIRE 2021 Depth Guide One-to-one Relighting Challenge.
S3Net: A Single Stream Structure for Depth Guided Image Relighting
May 05, 2021

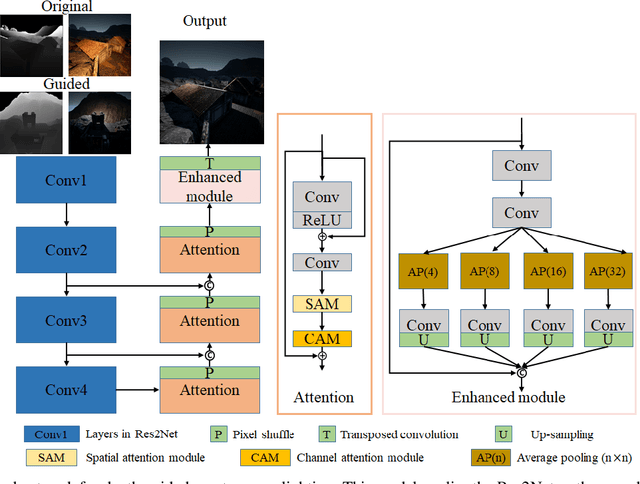
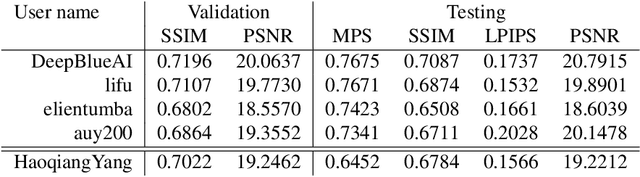
Depth guided any-to-any image relighting aims to generate a relit image from the original image and corresponding depth maps to match the illumination setting of the given guided image and its depth map. To the best of our knowledge, this task is a new challenge that has not been addressed in the previous literature. To address this issue, we propose a deep learning-based neural Single Stream Structure network called S3Net for depth guided image relighting. This network is an encoder-decoder model. We concatenate all images and corresponding depth maps as the input and feed them into the model. The decoder part contains the attention module and the enhanced module to focus on the relighting-related regions in the guided images. Experiments performed on challenging benchmark show that the proposed model achieves the 3 rd highest SSIM in the NTIRE 2021 Depth Guided Any-to-any Relighting Challenge.
Wavelet Channel Attention Module with a Fusion Network for Single Image Deraining
Jul 17, 2020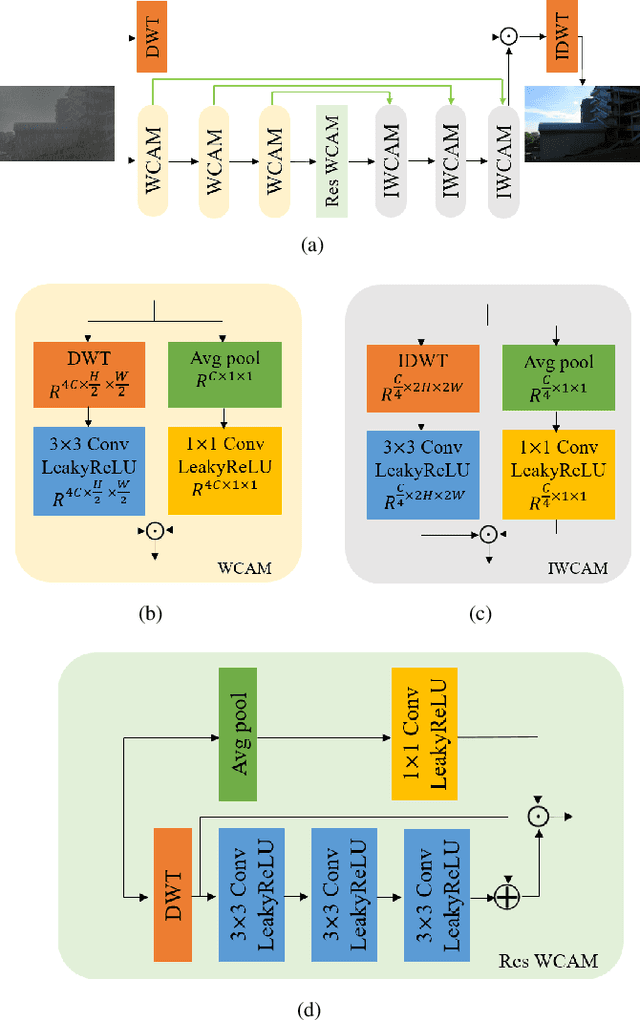
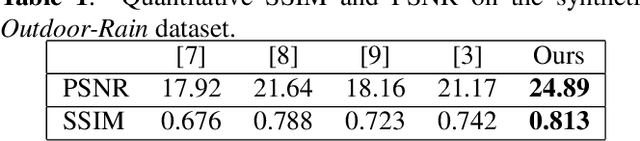


Single image deraining is a crucial problem because rain severely degenerates the visibility of images and affects the performance of computer vision tasks like outdoor surveillance systems and intelligent vehicles. In this paper, we propose the new convolutional neural network (CNN) called the wavelet channel attention module with a fusion network. Wavelet transform and the inverse wavelet transform are substituted for down-sampling and up-sampling so feature maps from the wavelet transform and convolutions contain different frequencies and scales. Furthermore, feature maps are integrated by channel attention. Our proposed network learns confidence maps of four sub-band images derived from the wavelet transform of the original images. Finally, the clear image can be well restored via the wavelet reconstruction and fusion of the low-frequency part and high-frequency parts. Several experimental results on synthetic and real images present that the proposed algorithm outperforms state-of-the-art methods.
Y-net: Multi-scale feature aggregation network with wavelet structure similarity loss function for single image dehazing
Mar 31, 2020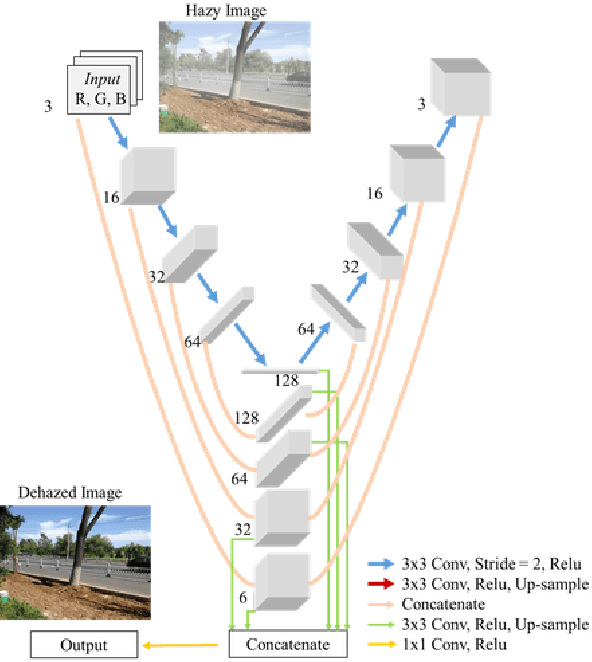
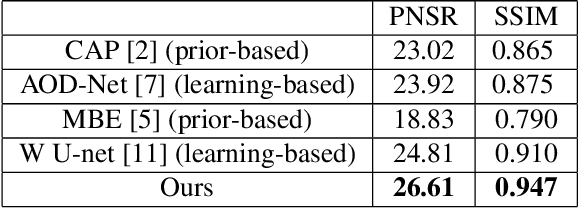
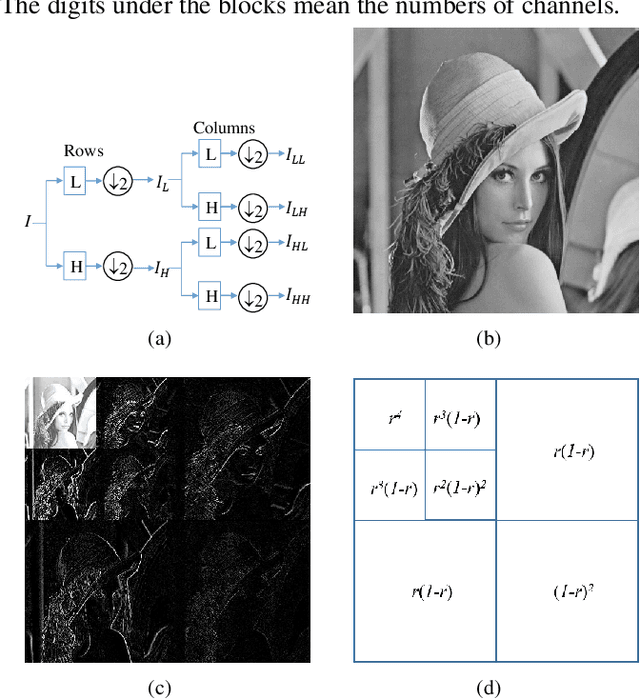
Single image dehazing is the ill-posed two-dimensional signal reconstruction problem. Recently, deep convolutional neural networks (CNN) have been successfully used in many computer vision problems. In this paper, we propose a Y-net that is named for its structure. This network reconstructs clear images by aggregating multi-scale features maps. Additionally, we propose a Wavelet Structure SIMilarity (W-SSIM) loss function in the training step. In the proposed loss function, discrete wavelet transforms are applied repeatedly to divide the image into differently sized patches with different frequencies and scales. The proposed loss function is the accumulation of SSIM loss of various patches with respective ratios. Extensive experimental results demonstrate that the proposed Y-net with the W-SSIM loss function restores high-quality clear images and outperforms state-of-the-art algorithms. Code and models are available at https://github.com/dectrfov/Y-net.
Synthesizing New Retinal Symptom Images by Multiple Generative Models
Feb 11, 2019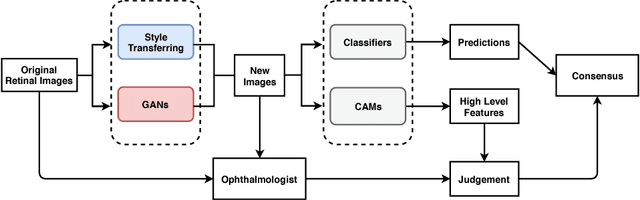
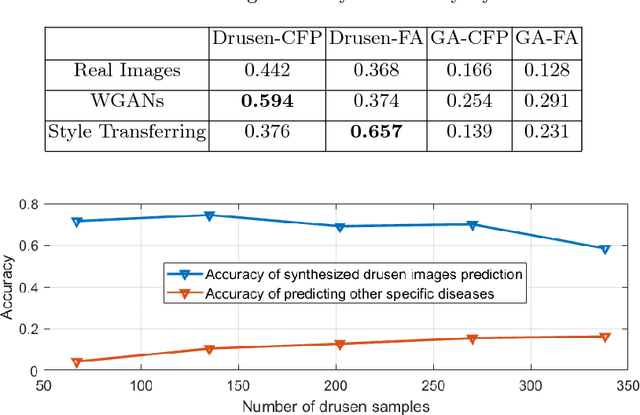
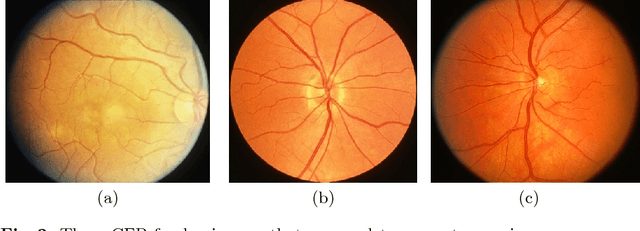
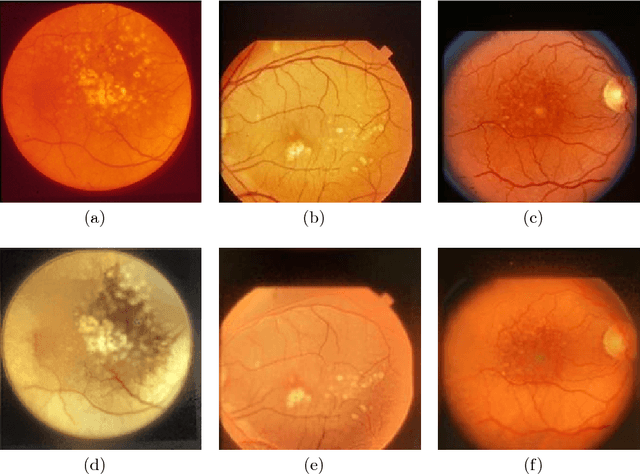
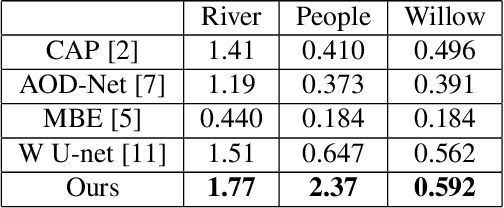
Age-Related Macular Degeneration (AMD) is an asymptomatic retinal disease which may result in loss of vision. There is limited access to high-quality relevant retinal images and poor understanding of the features defining sub-classes of this disease. Motivated by recent advances in machine learning we specifically explore the potential of generative modeling, using Generative Adversarial Networks (GANs) and style transferring, to facilitate clinical diagnosis and disease understanding by feature extraction. We design an analytic pipeline which first generates synthetic retinal images from clinical images; a subsequent verification step is applied. In the synthesizing step we merge GANs (DCGANs and WGANs architectures) and style transferring for the image generation, whereas the verified step controls the accuracy of the generated images. We find that the generated images contain sufficient pathological details to facilitate ophthalmologists' task of disease classification and in discovery of disease relevant features. In particular, our system predicts the drusen and geographic atrophy sub-classes of AMD. Furthermore, the performance using CFP images for GANs outperforms the classification based on using only the original clinical dataset. Our results are evaluated using existing classifier of retinal diseases and class activated maps, supporting the predictive power of the synthetic images and their utility for feature extraction. Our code examples are available online.
Auto-Classification of Retinal Diseases in the Limit of Sparse Data Using a Two-Streams Machine Learning Model
Nov 01, 2018

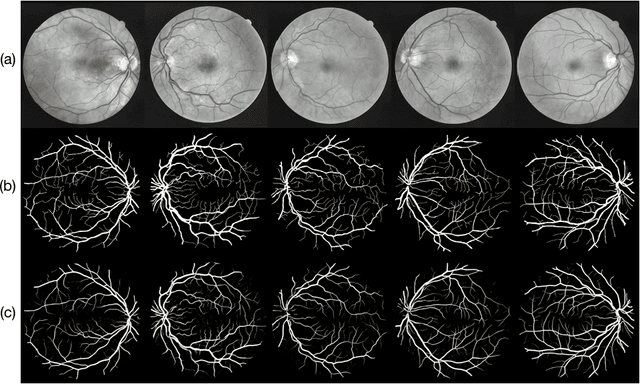
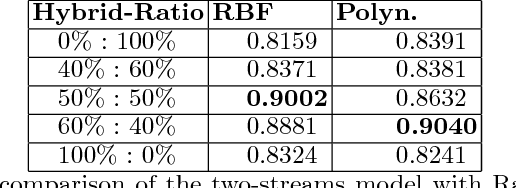
Automatic clinical diagnosis of retinal diseases has emerged as a promising approach to facilitate discovery in areas with limited access to specialists. Based on the fact that fundus structure and vascular disorders are the main characteristics of retinal diseases, we propose a novel visual-assisted diagnosis hybrid model mixing the support vector machine (SVM) and deep neural networks (DNNs). Furthermore, we present a new clinical retina dataset, called EyeNet2, for ophthalmology incorporating 52 retina diseases classes. Using EyeNet2, our model achieves 90.43\% diagnosis accuracy, and the model performance is comparable to the professional ophthalmologists.
* A extension work of a workshop paper arXiv admin note: substantial text overlap with arXiv:1806.06423