 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Multi-Object Tracking in Noisy Environments
Jun 02, 2021

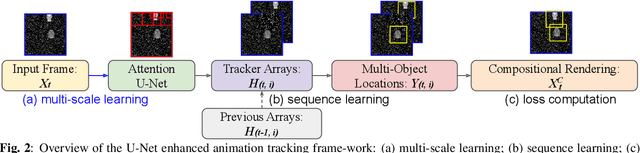
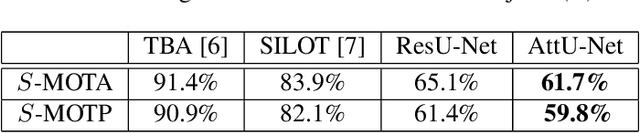
Camera movement and unpredictable environmental conditions like dust and wind induce noise into video feeds. We observe that popular unsupervised MOT methods are dependent on noise-free conditions. We show that the addition of a small amount of artificial random noise causes a sharp degradation in model performance on benchmark metrics. We resolve this problem by introducing a robust unsupervised multi-object tracking (MOT) model: AttU-Net. The proposed single-head attention model helps limit the negative impact of noise by learning visual representations at different segment scales. AttU-Net shows better unsupervised MOT tracking performance over variational inference-based state-of-the-art baselines. We evaluate our method in the MNIST and the Atari game video benchmark. We also provide two extended video datasets consisting of complex visual patterns that include Kuzushiji characters and fashion images to validate the effectiveness of the proposed method.
Controllability, Multiplexing, and Transfer Learning in Networks using Evolutionary Learning
Nov 14, 2018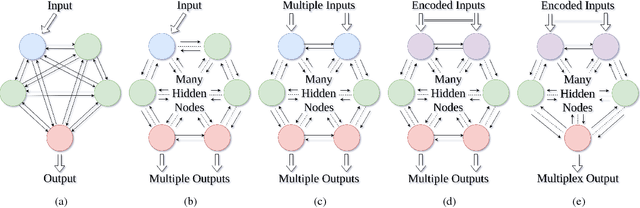
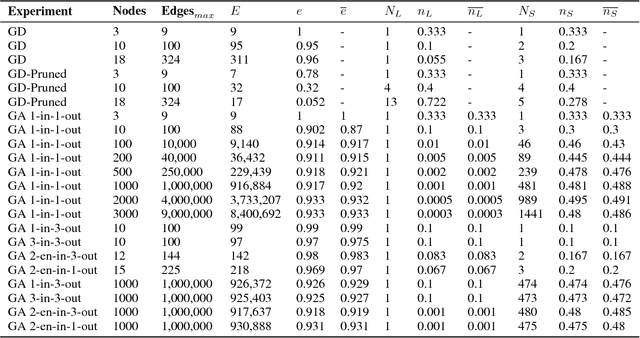
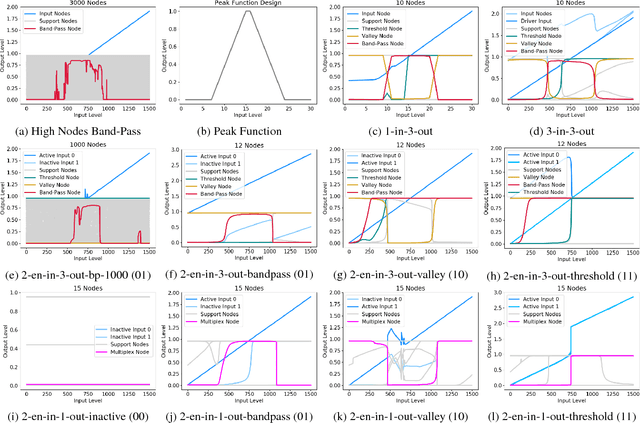
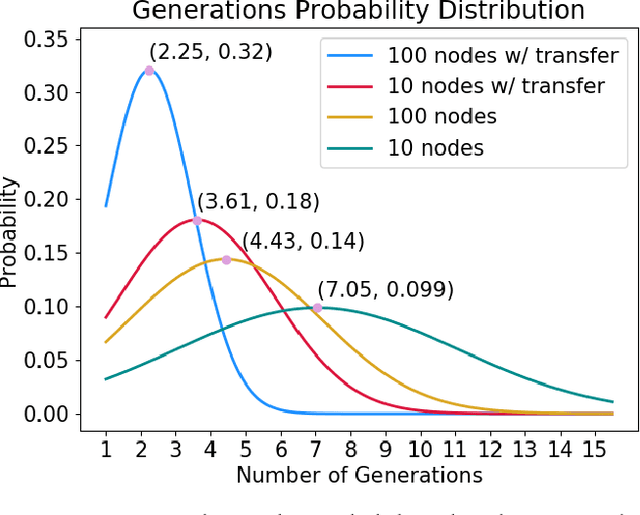
Networks are fundamental building blocks for representing data, and computations. Remarkable progress in learning in structurally defined (shallow or deep) networks has recently been achieved. Here we introduce evolutionary exploratory search and learning method of topologically flexible networks under the constraint of producing elementary computational steady-state input-output operations. Our results include; (1) the identification of networks, over four orders of magnitude, implementing computation of steady-state input-output functions, such as a band-pass filter, a threshold function, and an inverse band-pass function. Next, (2) the learned networks are technically controllable as only a small number of driver nodes are required to move the system to a new state. Furthermore, we find that the fraction of required driver nodes is constant during evolutionary learning, suggesting a stable system design. (3), our framework allows multiplexing of different computations using the same network. For example, using a binary representation of the inputs, the network can readily compute three different input-output functions. Finally, (4) the proposed evolutionary learning demonstrates transfer learning. If the system learns one function A, then learning B requires on average less number of steps as compared to learning B from tabula rasa. We conclude that the constrained evolutionary learning produces large robust controllable circuits, capable of multiplexing and transfer learning. Our study suggests that network-based computations of steady-state functions, representing either cellular modules of cell-to-cell communication networks or internal molecular circuits communicating within a cell, could be a powerful model for biologically inspired computing. This complements conceptualizations such as attractor based models, or reservoir computing.
Auto-Classification of Retinal Diseases in the Limit of Sparse Data Using a Two-Streams Machine Learning Model
Nov 01, 2018

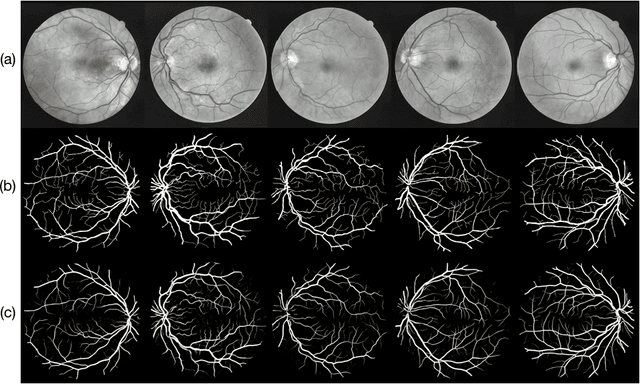
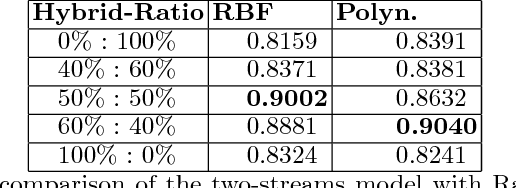
Automatic clinical diagnosis of retinal diseases has emerged as a promising approach to facilitate discovery in areas with limited access to specialists. Based on the fact that fundus structure and vascular disorders are the main characteristics of retinal diseases, we propose a novel visual-assisted diagnosis hybrid model mixing the support vector machine (SVM) and deep neural networks (DNNs). Furthermore, we present a new clinical retina dataset, called EyeNet2, for ophthalmology incorporating 52 retina diseases classes. Using EyeNet2, our model achieves 90.43\% diagnosis accuracy, and the model performance is comparable to the professional ophthalmologists.
* A extension work of a workshop paper arXiv admin note: substantial text overlap with arXiv:1806.06423
A Novel Hybrid Machine Learning Model for Auto-Classification of Retinal Diseases
Jun 17, 2018
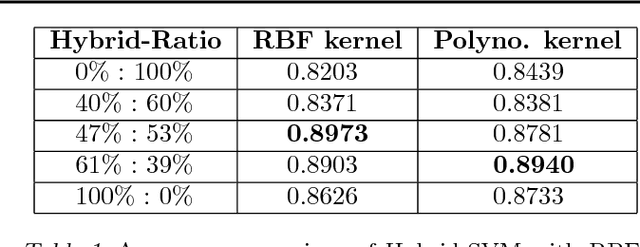
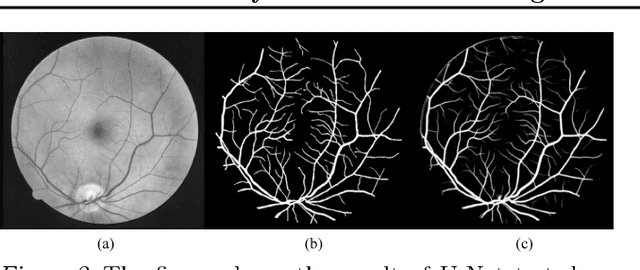
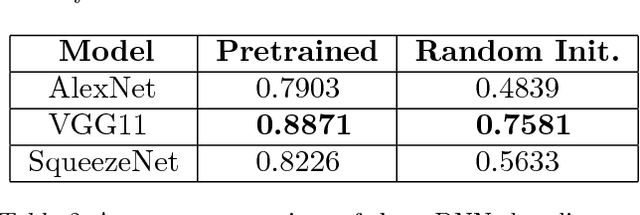
Automatic clinical diagnosis of retinal diseases has emerged as a promising approach to facilitate discovery in areas with limited access to specialists. We propose a novel visual-assisted diagnosis hybrid model based on the support vector machine (SVM) and deep neural networks (DNNs). The model incorporates complementary strengths of DNNs and SVM. Furthermore, we present a new clinical retina label collection for ophthalmology incorporating 32 retina diseases classes. Using EyeNet, our model achieves 89.73% diagnosis accuracy and the model performance is comparable to the professional ophthalmologists.
* Accepted at the Joint ICML and IJCAI Workshop on Computational Biology (ICML-IJCAI WCB) to be held in Stockholm SWEDEN, 2018. Referring to https://sites.google.com/view/wcb2018/accepted-papers?authuser=0