 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Accurate Skeleton-Based Two-Person Interaction Recognition Using Inter- and Intra-body Graphs
Jul 26, 2022
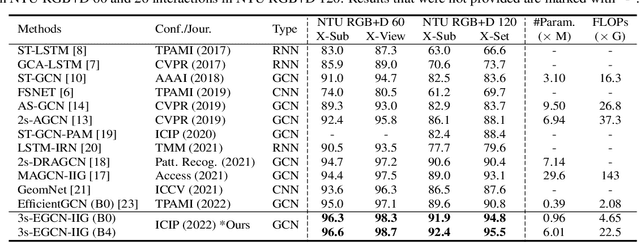

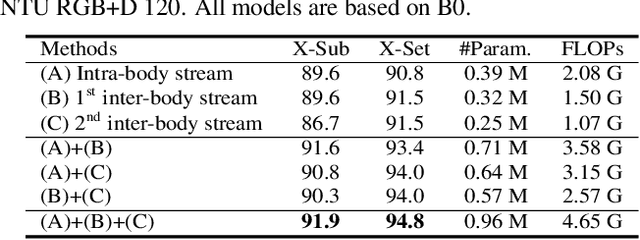
Skeleton-based two-person interaction recognition has been gaining increasing attention as advancements are made in pose estimation and graph convolutional networks. Although the accuracy has been gradually improving, the increasing computational complexity makes it more impractical for a real-world environment. There is still room for accuracy improvement as the conventional methods do not fully represent the relationship between inter-body joints. In this paper, we propose a lightweight model for accurately recognizing two-person interactions. In addition to the architecture, which incorporates middle fusion, we introduce a factorized convolution technique to reduce the weight parameters of the model. We also introduce a network stream that accounts for relative distance changes between inter-body joints to improve accuracy. Experiments using two large-scale datasets, NTU RGB+D 60 and 120, show that our method simultaneously achieved the highest accuracy and relatively low computational complexity compared with the conventional methods.
Robust Unsupervised Multi-Object Tracking in Noisy Environments
Jun 02, 2021

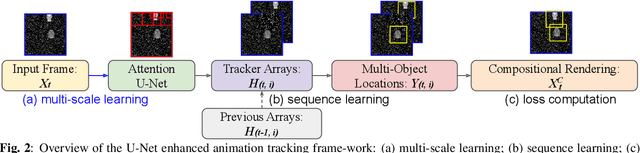
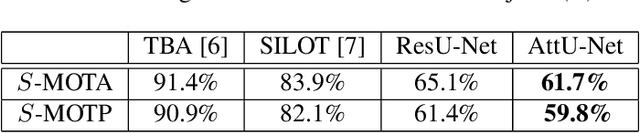
Camera movement and unpredictable environmental conditions like dust and wind induce noise into video feeds. We observe that popular unsupervised MOT methods are dependent on noise-free conditions. We show that the addition of a small amount of artificial random noise causes a sharp degradation in model performance on benchmark metrics. We resolve this problem by introducing a robust unsupervised multi-object tracking (MOT) model: AttU-Net. The proposed single-head attention model helps limit the negative impact of noise by learning visual representations at different segment scales. AttU-Net shows better unsupervised MOT tracking performance over variational inference-based state-of-the-art baselines. We evaluate our method in the MNIST and the Atari game video benchmark. We also provide two extended video datasets consisting of complex visual patterns that include Kuzushiji characters and fashion images to validate the effectiveness of the proposed method.
Segmentation-Based Bounding Box Generation for Omnidirectional Pedestrian Detection
Apr 28, 2021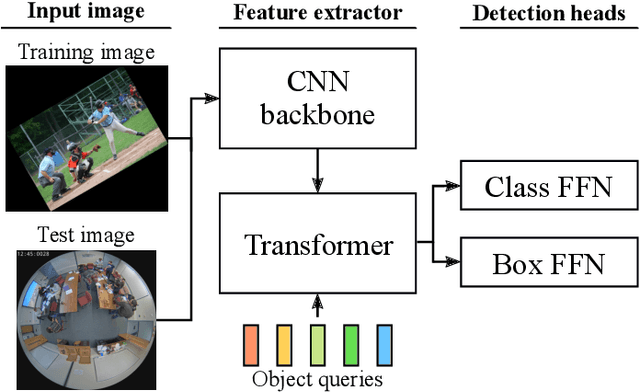
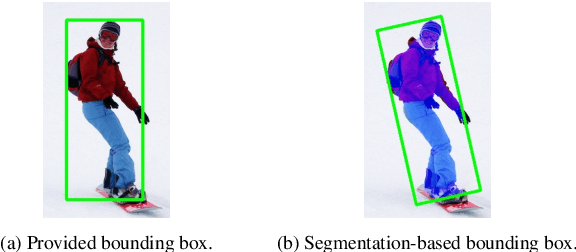
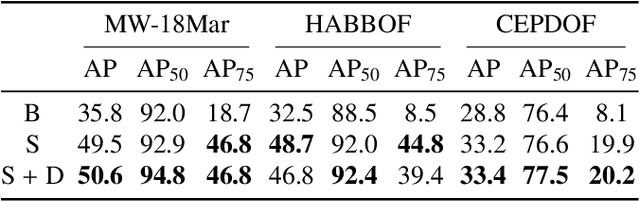
We propose a segmentation-based bounding box generation method for omnidirectional pedestrian detection, which enables detectors to tightly fit bounding boxes to pedestrians without omnidirectional images for training. Because the appearance of pedestrians in omnidirectional images may be rotated to any angle, the performance of common pedestrian detectors is likely to be substantially degraded. Existing methods mitigate this issue by transforming images during inference or training detectors with omnidirectional images. However, the first approach substantially degrades the inference speed, and the second approach requires laborious annotations. To overcome these drawbacks, we leverage an existing large-scale dataset, whose segmentation annotations can be utilized, to generate tightly fitted bounding box annotations. We also develop a pseudo-fisheye distortion augmentation method, which further enhances the performance. Extensive analysis shows that our detector successfully fits bounding boxes to pedestrians and demonstrates substantial performance improvement.
QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information
Mar 09, 2021
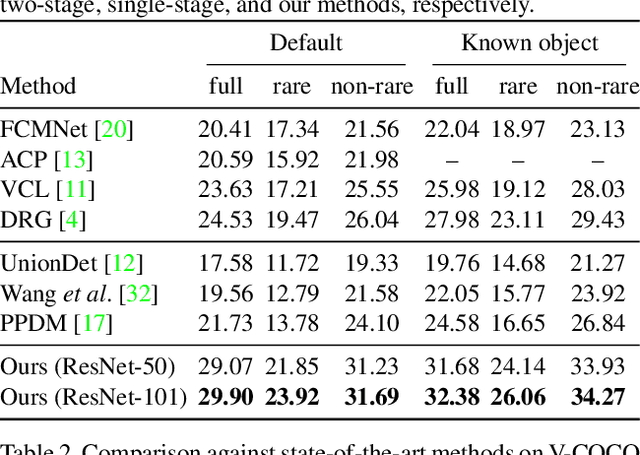
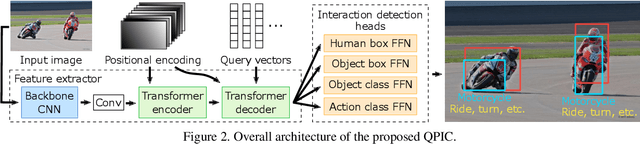

We propose a simple, intuitive yet powerful method for human-object interaction (HOI) detection. HOIs are so diverse in spatial distribution in an image that existing CNN-based methods face the following three major drawbacks; they cannot leverage image-wide features due to CNN's locality, they rely on a manually defined location-of-interest for the feature aggregation, which sometimes does not cover contextually important regions, and they cannot help but mix up the features for multiple HOI instances if they are located closely. To overcome these drawbacks, we propose a transformer-based feature extractor, in which an attention mechanism and query-based detection play key roles. The attention mechanism is effective in aggregating contextually important information image-wide, while the queries, which we design in such a way that each query captures at most one human-object pair, can avoid mixing up the features from multiple instances. This transformer-based feature extractor produces so effective embeddings that the subsequent detection heads may be fairly simple and intuitive. The extensive analysis reveals that the proposed method successfully extracts contextually important features, and thus outperforms existing methods by large margins (5.37 mAP on HICO-DET, and 5.7 mAP on V-COCO). The source codes are available at $\href{https://github.com/hitachi-rd-cv/qpic}{\text{this https URL}}$.
Cycle-Contrast for Self-Supervised Video Representation Learning
Oct 28, 2020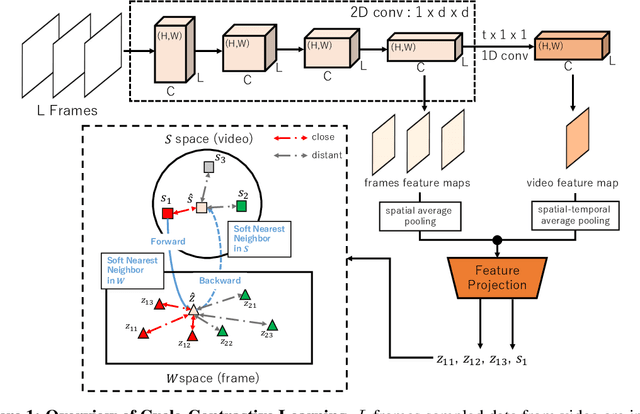
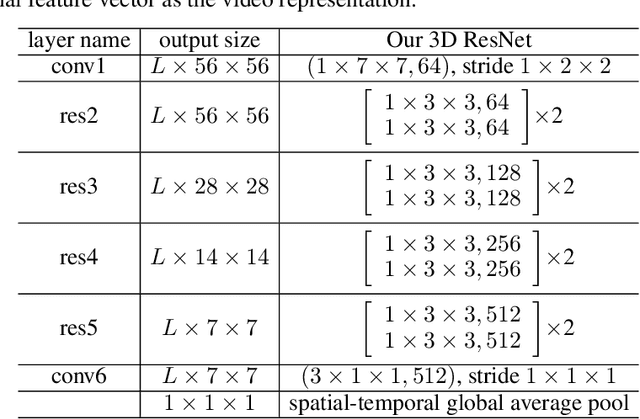

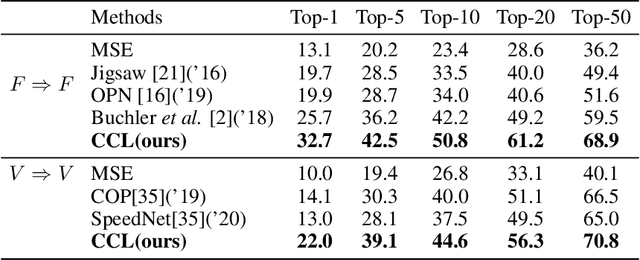
We present Cycle-Contrastive Learning (CCL), a novel self-supervised method for learning video representation. Following a nature that there is a belong and inclusion relation of video and its frames, CCL is designed to find correspondences across frames and videos considering the contrastive representation in their domains respectively. It is different from recent approaches that merely learn correspondences across frames or clips. In our method, the frame and video representations are learned from a single network based on an R3D architecture, with a shared non-linear transformation for embedding both frame and video features before the cycle-contrastive loss. We demonstrate that the video representation learned by CCL can be transferred well to downstream tasks of video understanding, outperforming previous methods in nearest neighbour retrieval and action recognition tasks on UCF101, HMDB51 and MMAct.