 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Multi-Object Tracking in Noisy Environments
Paper and Code


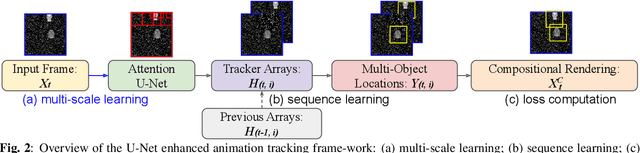
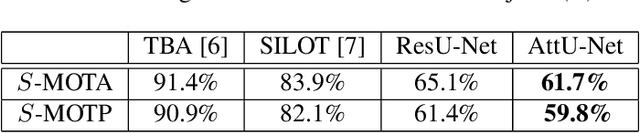
Camera movement and unpredictable environmental conditions like dust and wind induce noise into video feeds. We observe that popular unsupervised MOT methods are dependent on noise-free conditions. We show that the addition of a small amount of artificial random noise causes a sharp degradation in model performance on benchmark metrics. We resolve this problem by introducing a robust unsupervised multi-object tracking (MOT) model: AttU-Net. The proposed single-head attention model helps limit the negative impact of noise by learning visual representations at different segment scales. AttU-Net shows better unsupervised MOT tracking performance over variational inference-based state-of-the-art baselines. We evaluate our method in the MNIST and the Atari game video benchmark. We also provide two extended video datasets consisting of complex visual patterns that include Kuzushiji characters and fashion images to validate the effectiveness of the proposed method.