 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Multi-Object Tracking in Noisy Environments
Jun 02, 2021

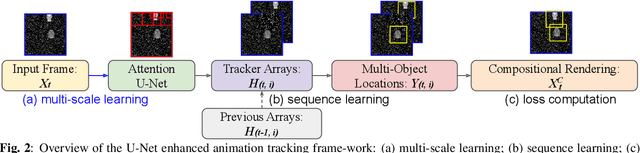
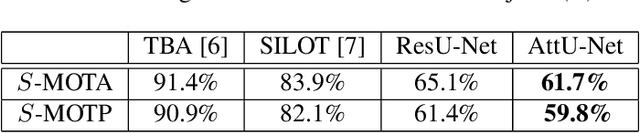
Camera movement and unpredictable environmental conditions like dust and wind induce noise into video feeds. We observe that popular unsupervised MOT methods are dependent on noise-free conditions. We show that the addition of a small amount of artificial random noise causes a sharp degradation in model performance on benchmark metrics. We resolve this problem by introducing a robust unsupervised multi-object tracking (MOT) model: AttU-Net. The proposed single-head attention model helps limit the negative impact of noise by learning visual representations at different segment scales. AttU-Net shows better unsupervised MOT tracking performance over variational inference-based state-of-the-art baselines. We evaluate our method in the MNIST and the Atari game video benchmark. We also provide two extended video datasets consisting of complex visual patterns that include Kuzushiji characters and fashion images to validate the effectiveness of the proposed method.
Cycle-Contrast for Self-Supervised Video Representation Learning
Oct 28, 2020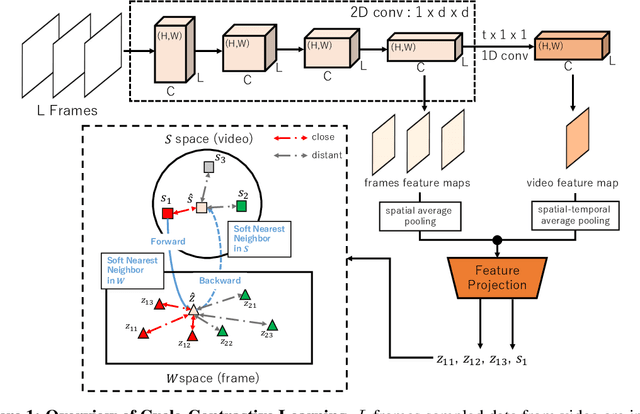
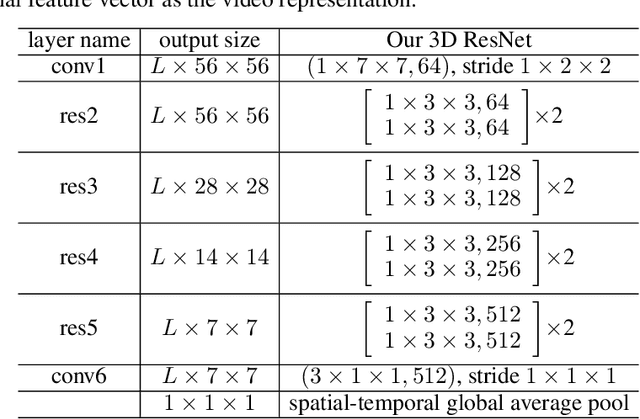

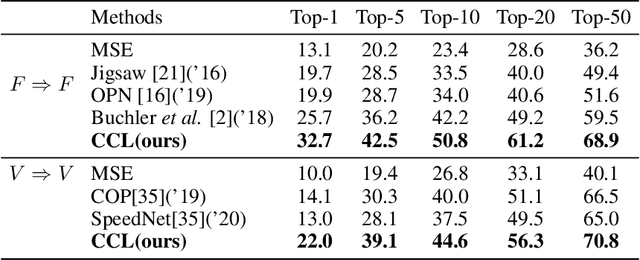
We present Cycle-Contrastive Learning (CCL), a novel self-supervised method for learning video representation. Following a nature that there is a belong and inclusion relation of video and its frames, CCL is designed to find correspondences across frames and videos considering the contrastive representation in their domains respectively. It is different from recent approaches that merely learn correspondences across frames or clips. In our method, the frame and video representations are learned from a single network based on an R3D architecture, with a shared non-linear transformation for embedding both frame and video features before the cycle-contrastive loss. We demonstrate that the video representation learned by CCL can be transferred well to downstream tasks of video understanding, outperforming previous methods in nearest neighbour retrieval and action recognition tasks on UCF101, HMDB51 and MMAct.
Augmented Hard Example Mining for Generalizable Person Re-Identification
Oct 11, 2019
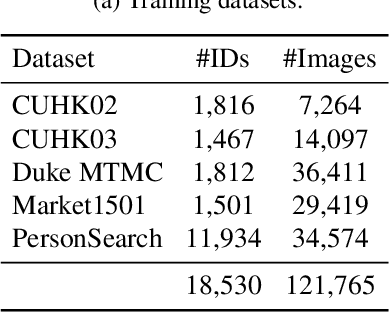
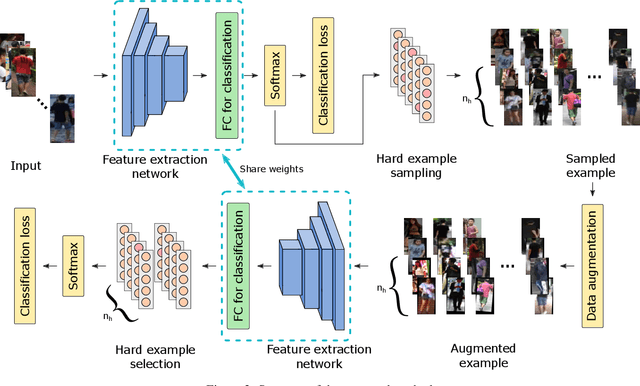
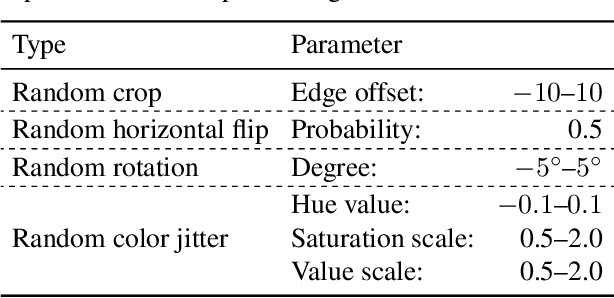
Although the performance of person re-identification (Re-ID) has been much improved by using sophisticated training methods and large-scale labelled datasets, many existing methods make the impractical assumption that information of a target domain can be utilized during training. In practice, a Re-ID system often starts running as soon as it is deployed, hence training with data from a target domain is unrealistic. To make Re-ID systems more practical, methods have been proposed that achieve high performance without information of a target domain. However, they need cumbersome tuning for training and unusual operations for testing. In this paper, we propose augmented hard example mining, which can be easily integrated to a common Re-ID training process and can utilize sophisticated models without any network modification. The method discovers hard examples on the basis of classification probabilities, and to make the examples harder, various types of augmentation are applied to the examples. Among those examples, excessively augmented ones are eliminated by a classification based selection process. Extensive analysis shows that our method successfully selects effective examples and achieves state-of-the-art performance on publicly available benchmark datasets.
Active Generative Adversarial Network for Image Classification
Jun 17, 2019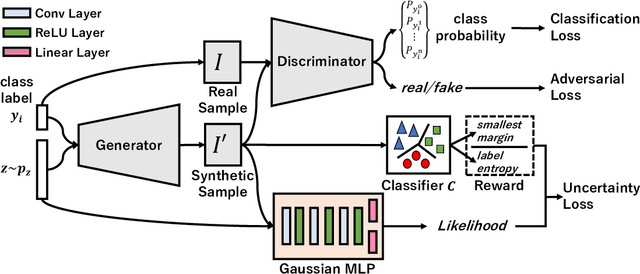
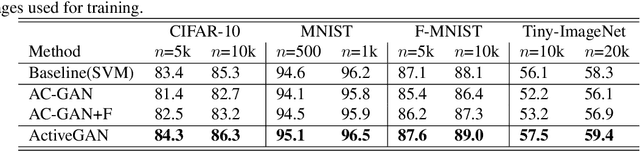


Sufficient supervised information is crucial for any machine learning models to boost performance. However, labeling data is expensive and sometimes difficult to obtain. Active learning is an approach to acquire annotations for data from a human oracle by selecting informative samples with a high probability to enhance performance. In recent emerging studies, a generative adversarial network (GAN) has been integrated with active learning to generate good candidates to be presented to the oracle. In this paper, we propose a novel model that is able to obtain labels for data in a cheaper manner without the need to query an oracle. In the model, a novel reward for each sample is devised to measure the degree of uncertainty, which is obtained from a classifier trained with existing labeled data. This reward is used to guide a conditional GAN to generate informative samples with a higher probability for a certain label. With extensive evaluations, we have confirmed the effectiveness of the model, showing that the generated samples are capable of improving the classification performance in popular image classification tasks.