 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precise Action Spotting: Addressing Temporal Misalignment in Labels with Dynamic Label Assignment
Mar 31, 2025



Precise action spotting has attracted considerable attention due to its promising applications. While existing methods achieve substantial performance by employing well-designed model architecture, they overlook a significant challenge: the temporal misalignment inherent in ground-truth labels. This misalignment arises when frames labeled as containing events do not align accurately with the actual event times, often as a result of human annotation errors or the inherent difficulties in precisely identifying event boundaries across neighboring frames. To tackle this issue, we propose a novel dynamic label assignment strategy that allows predictions to have temporal offsets from ground-truth action times during training, ensuring consistent event spotting. Our method extends the concept of minimum-cost matching, which is utilized in the spatial domain for object detection, to the temporal domain. By calculating matching costs based on predicted action class scores and temporal offsets, our method dynamically assigns labels to the most likely predictions, even when the predicted times of these predictions deviate from ground-truth times, alleviating the negative effects of temporal misalignment in labels. We conduct extensive experiments and demonstrate that our method achieves state-of-the-art performance, particularly in conditions where events are visually distinct and temporal misalignment in labels is common.
Design and Analysis of Efficient Attention in Transformers for Social Group Activity Recognition
Apr 15, 2024Social group activity recognition is a challenging task extended from group activity recognition, where social groups must be recognized with their activities and group members. Existing methods tackle this task by leveraging region features of individuals following existing group activity recognition methods. However, the effectiveness of region features is susceptible to person localization and variable semantics of individual actions. To overcome these issues, we propose leveraging attention modules in transformers to generate social group features. In this method, multiple embeddings are used to aggregate features for a social group, each of which is assigned to a group member without duplication. Due to this non-duplicated assignment, the number of embeddings must be significant to avoid missing group members and thus renders attention in transformers ineffective. To find optimal attention designs with a large number of embeddings, we explore several design choices of queries for feature aggregation and self-attention modules in transformer decoders. Extensive experimental results show that the proposed method achieves state-of-the-art performance and verify that the proposed attention designs are highly effective on social group activity recognition.
Random Word Data Augmentation with CLIP for Zero-Shot Anomaly Detection
Aug 22, 2023This paper presents a novel method that leverages a visual-language model, CLIP, as a data source for zero-shot anomaly detection. Tremendous efforts have been put towards developing anomaly detectors due to their potential industrial applications. Considering the difficulty in acquiring various anomalous samples for training, most existing methods train models with only normal samples and measure discrepancies from the distribution of normal samples during inference, which requires training a model for each object category. The problem of this inefficient training requirement has been tackled by designing a CLIP-based anomaly detector that applies prompt-guided classification to each part of an image in a sliding window manner. However, the method still suffers from the labor of careful prompt ensembling with known object categories. To overcome the issues above, we propose leveraging CLIP as a data source for training. Our method generates text embeddings with the text encoder in CLIP with typical prompts that include words of normal and anomaly. In addition to these words, we insert several randomly generated words into prompts, which enables the encoder to generate a diverse set of normal and anomalous samples. Using the generated embeddings as training data, a feed-forward neural network learns to extract features of normal and anomaly from CLIP's embeddings, and as a result, a category-agnostic anomaly detector can be obtained without any training images. Experimental results demonstrate that our method achieves state-of-the-art performance without laborious prompt ensembling in zero-shot setups.
Hunting Group Clues with Transformers for Social Group Activity Recognition
Jul 12, 2022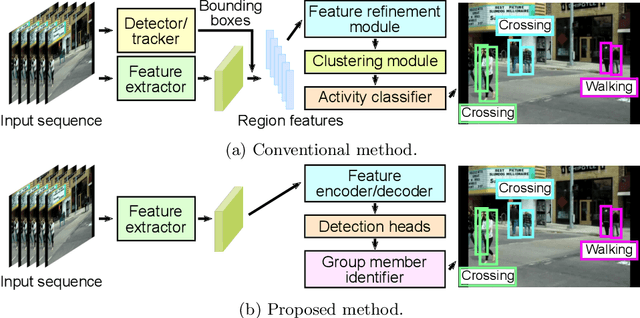
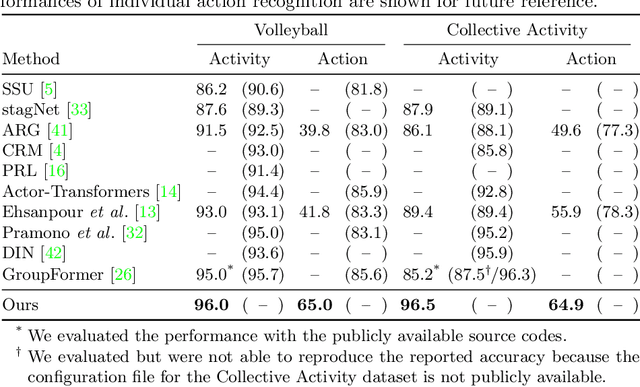
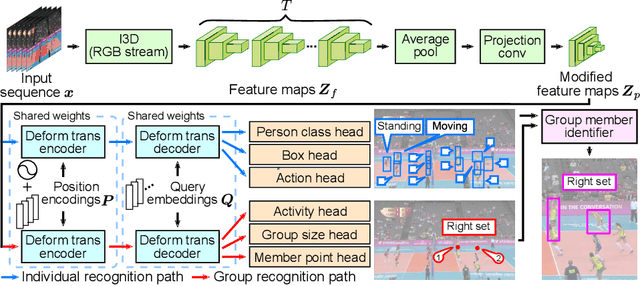
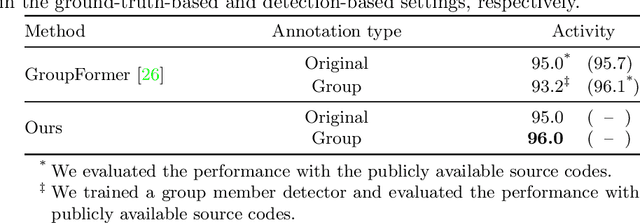
This paper presents a novel framework for social group activity recognition. As an expanded task of group activity recognition, social group activity recognition requires recognizing multiple sub-group activities and identifying group members. Most existing methods tackle both tasks by refining region features and then summarizing them into activity features. Such heuristic feature design renders the effectiveness of features susceptible to incomplete person localization and disregards the importance of scene contexts. Furthermore, region features are sub-optimal to identify group members because the features may be dominated by those of people in the regions and have different semantics. To overcome these drawbacks, we propose to leverage attention modules in transformers to generate effective social group features. Our method is designed in such a way that the attention modules identify and then aggregate features relevant to social group activities, generating an effective feature for each social group. Group member information is embedded into the features and thus accessed by feed-forward networks. The outputs of feed-forward networks represent groups so concisely that group members can be identified with simple Hungarian matching between groups and individuals. Experimental results show that our method outperforms state-of-the-art methods on the Volleyball and Collective Activity datasets.
Segmentation-Based Bounding Box Generation for Omnidirectional Pedestrian Detection
Apr 28, 2021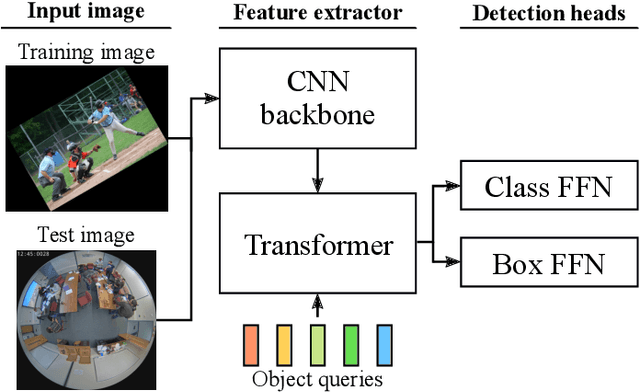
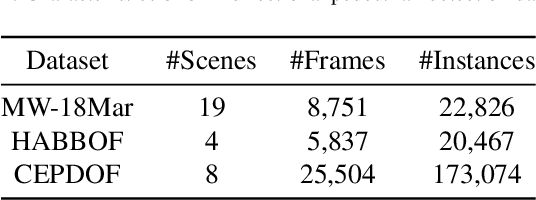
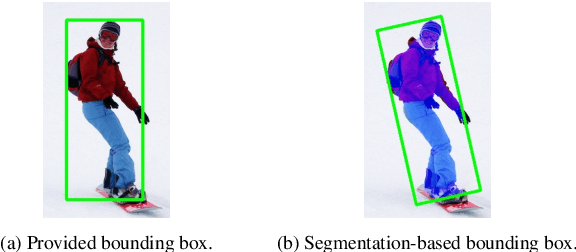
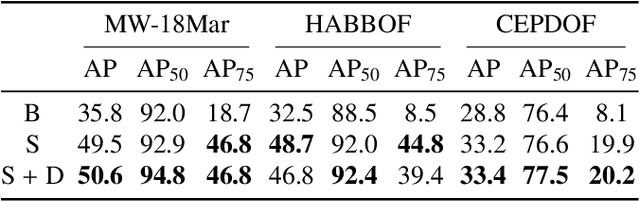
We propose a segmentation-based bounding box generation method for omnidirectional pedestrian detection, which enables detectors to tightly fit bounding boxes to pedestrians without omnidirectional images for training. Because the appearance of pedestrians in omnidirectional images may be rotated to any angle, the performance of common pedestrian detectors is likely to be substantially degraded. Existing methods mitigate this issue by transforming images during inference or training detectors with omnidirectional images. However, the first approach substantially degrades the inference speed, and the second approach requires laborious annotations. To overcome these drawbacks, we leverage an existing large-scale dataset, whose segmentation annotations can be utilized, to generate tightly fitted bounding box annotations. We also develop a pseudo-fisheye distortion augmentation method, which further enhances the performance. Extensive analysis shows that our detector successfully fits bounding boxes to pedestrians and demonstrates substantial performance improvement.
QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information
Mar 09, 2021
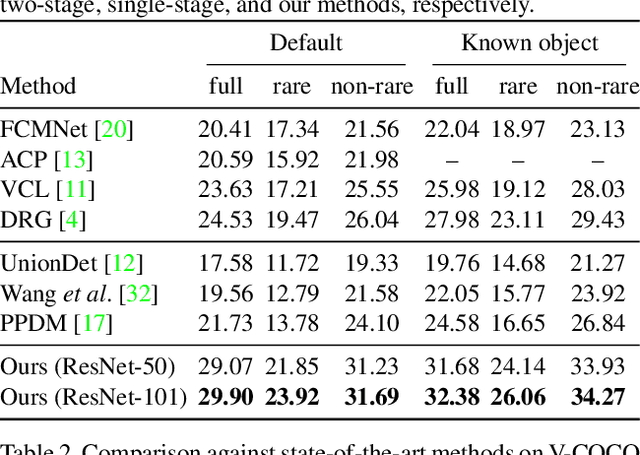
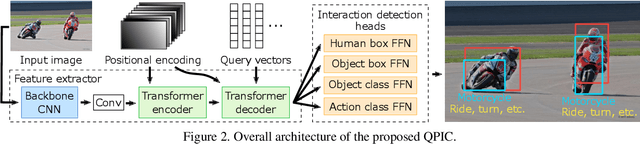

We propose a simple, intuitive yet powerful method for human-object interaction (HOI) detection. HOIs are so diverse in spatial distribution in an image that existing CNN-based methods face the following three major drawbacks; they cannot leverage image-wide features due to CNN's locality, they rely on a manually defined location-of-interest for the feature aggregation, which sometimes does not cover contextually important regions, and they cannot help but mix up the features for multiple HOI instances if they are located closely. To overcome these drawbacks, we propose a transformer-based feature extractor, in which an attention mechanism and query-based detection play key roles. The attention mechanism is effective in aggregating contextually important information image-wide, while the queries, which we design in such a way that each query captures at most one human-object pair, can avoid mixing up the features from multiple instances. This transformer-based feature extractor produces so effective embeddings that the subsequent detection heads may be fairly simple and intuitive. The extensive analysis reveals that the proposed method successfully extracts contextually important features, and thus outperforms existing methods by large margins (5.37 mAP on HICO-DET, and 5.7 mAP on V-COCO). The source codes are available at $\href{https://github.com/hitachi-rd-cv/qpic}{\text{this https URL}}$.
Augmented Hard Example Mining for Generalizable Person Re-Identification
Oct 11, 2019
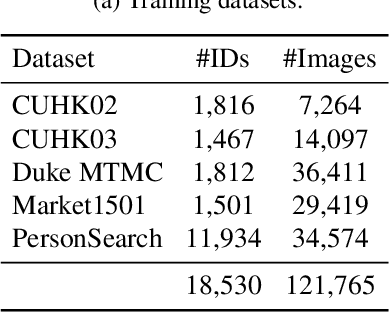
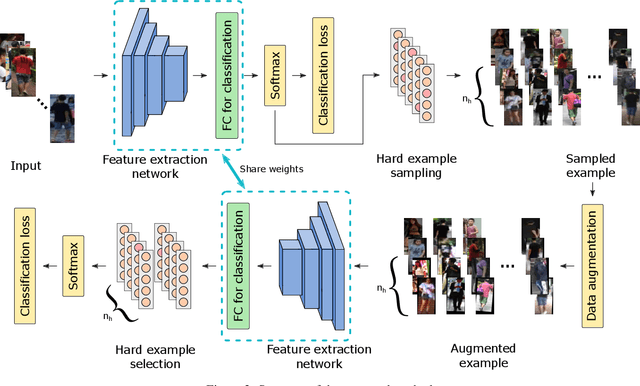
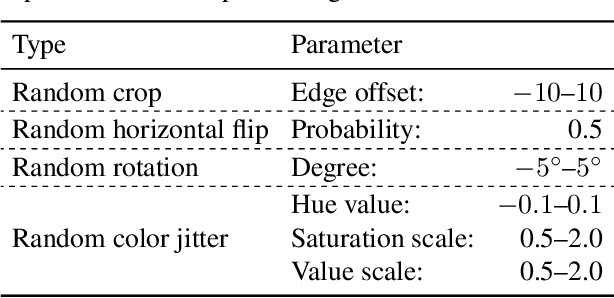
Although the performance of person re-identification (Re-ID) has been much improved by using sophisticated training methods and large-scale labelled datasets, many existing methods make the impractical assumption that information of a target domain can be utilized during training. In practice, a Re-ID system often starts running as soon as it is deployed, hence training with data from a target domain is unrealistic. To make Re-ID systems more practical, methods have been proposed that achieve high performance without information of a target domain. However, they need cumbersome tuning for training and unusual operations for testing. In this paper, we propose augmented hard example mining, which can be easily integrated to a common Re-ID training process and can utilize sophisticated models without any network modification. The method discovers hard examples on the basis of classification probabilities, and to make the examples harder, various types of augmentation are applied to the examples. Among those examples, excessively augmented ones are eliminated by a classification based selection process. Extensive analysis shows that our method successfully selects effective examples and achieves state-of-the-art performance on publicly available benchmark datasets.