 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Gets Cited: Competitive GEO in AI Answer Engines
May 25, 2026AI answer engines generate answers from retrieved pages but cite only a few sources. This makes visibility depend not just on ranking, but on being cited. We study competitive Generative Engine Optimization (GEO): when two retrieved candidates compete, what makes one more likely to be cited first? We build a controlled two-document retrieval-augmented generation (RAG) testbed that injects exactly two candidate sources into the model context and measures which source is referenced by the first citation marker in the output. Across six LLMs we execute 252,000 trials, repeated paired comparisons under one factorial program over 18 content factors. In each trial the two sources differ in exactly one factor; we use brand anonymization and counterbalanced source order to separate content effects from position bias. Mixed-effects models show that topical relevance and list position are the biggest drivers of being cited first. Including explicit price information and a recent timestamp also helps consistently. Completeness and trust cues add smaller gains, while formatting-only edits have little impact. We release a reproducible evaluation protocol and a prioritized GEO checklist for practitioners, and we exercised it in an early internal pilot at Sprinklr, where teams reported positive qualitative feedback on workflow usability.
Cognitive Weave: Synthesizing Abstracted Knowledge with a Spatio-Temporal Resonance Graph
Jun 09, 2025The emergence of capable large language model (LLM) based agents necessitates memory architectures that transcend mere data storage, enabling continuous learning, nuanced reasoning, and dynamic adaptation. Current memory systems often grapple with fundamental limitations in structural flexibility, temporal awareness, and the ability to synthesize higher-level insights from raw interaction data. This paper introduces Cognitive Weave, a novel memory framework centered around a multi-layered spatio-temporal resonance graph (STRG). This graph manages information as semantically rich insight particles (IPs), which are dynamically enriched with resonance keys, signifiers, and situational imprints via a dedicated semantic oracle interface (SOI). These IPs are interconnected through typed relational strands, forming an evolving knowledge tapestry. A key component of Cognitive Weave is the cognitive refinement process, an autonomous mechanism that includes the synthesis of insight aggregates (IAs) condensed, higher-level knowledge structures derived from identified clusters of related IPs. We present comprehensive experimental results demonstrating Cognitive Weave's marked enhancement over existing approaches in long-horizon planning tasks, evolving question-answering scenarios, and multi-session dialogue coherence. The system achieves a notable 34% average improvement in task completion rates and a 42% reduction in mean query latency when compared to state-of-the-art baselines. Furthermore, this paper explores the ethical considerations inherent in such advanced memory systems, discusses the implications for long-term memory in LLMs, and outlines promising future research trajectories.
Statistical Guarantees in Synthetic Data through Conformal Adversarial Generation
Apr 23, 2025The generation of high-quality synthetic data presents significant challenges in machine learning research, particularly regarding statistical fidelity and uncertainty quantification. Existing generative models produce compelling synthetic samples but lack rigorous statistical guarantees about their relation to the underlying data distribution, limiting their applicability in critical domains requiring robust error bounds. We address this fundamental limitation by presenting a novel framework that incorporates conformal prediction methodologies into Generative Adversarial Networks (GANs). By integrating multiple conformal prediction paradigms including Inductive Conformal Prediction (ICP), Mondrian Conformal Prediction, Cross-Conformal Prediction, and Venn-Abers Predictors, we establish distribution-free uncertainty quantification in generated samples. This approach, termed Conformalized GAN (cGAN), demonstrates enhanced calibration properties while maintaining the generative power of traditional GANs, producing synthetic data with provable statistical guarantees. We provide rigorous mathematical proofs establishing finite-sample validity guarantees and asymptotic efficiency properties, enabling the reliable application of synthetic data in high-stakes domains including healthcare, finance, and autonomous systems.
Uncertainty-Aware Hardware Trojan Detection Using Multimodal Deep Learning
Jan 23, 2024The risk of hardware Trojans being inserted at various stages of chip production has increased in a zero-trust fabless era. To counter this, various machine learning solutions have been developed for the detection of hardware Trojans. While most of the focus has been on either a statistical or deep learning approach, the limited number of Trojan-infected benchmarks affects the detection accuracy and restricts the possibility of detecting zero-day Trojans. To close the gap, we first employ generative adversarial networks to amplify our data in two alternative representation modalities, a graph and a tabular, ensuring that the dataset is distributed in a representative manner. Further, we propose a multimodal deep learning approach to detect hardware Trojans and evaluate the results from both early fusion and late fusion strategies. We also estimate the uncertainty quantification metrics of each prediction for risk-aware decision-making. The outcomes not only confirms the efficacy of our proposed hardware Trojan detection method but also opens a new door for future studies employing multimodality and uncertainty quantification to address other hardware security challenges.
* 2024 Design, Automation and Test in Europe Conference | The European Event for Electronic System Design & Test (accepted)
Enhancing Neural Theorem Proving through Data Augmentation and Dynamic Sampling Method
Dec 20, 2023



Theorem proving is a fundamental task in mathematics. With the advent of large language models (LLMs) and interactive theorem provers (ITPs) like Lean, there has been growing interest in integrating LLMs and ITPs to automate theorem proving. In this approach, the LLM generates proof steps (tactics), and the ITP checks the applicability of the tactics at the current goal. The two systems work together to complete the proof. In this paper, we introduce DS-Prover, a novel dynamic sampling method for theorem proving. This method dynamically determines the number of tactics to apply to expand the current goal, taking into account the remaining time compared to the total allocated time for proving a theorem. This makes the proof search process more efficient by adjusting the balance between exploration and exploitation as time passes. We also augment the training dataset by decomposing simplification and rewrite tactics with multiple premises into tactics with single premises. This gives the model more examples to learn from and helps it to predict the tactics with premises more accurately. We perform our experiments using the Mathlib dataset of the Lean theorem prover and report the performance on two standard datasets, MiniF2F and ProofNet. Our methods achieve significant performance gains on both datasets. We achieved a state-of-the-art performance (Pass@1) of 14.2% on the ProofNet dataset and a performance of 29.8% on MiniF2F, slightly surpassing the best-reported Pass@1 of 29.6% using Lean.
IndoorGNN: A Graph Neural Network based approach for Indoor Localization using WiFi RSSI
Dec 11, 2023Indoor localization is the process of determining the location of a person or object inside a building. Potential usage of indoor localization includes navigation, personalization, safety and security, and asset tracking. Commonly used technologies for indoor localization include WiFi, Bluetooth, RFID, and Ultra-wideband. Among these, WiFi's Received Signal Strength Indicator (RSSI)-based localization is preferred because of widely available WiFi Access Points (APs). We have two main contributions. First, we develop our method, 'IndoorGNN' which involves using a Graph Neural Network (GNN) based algorithm in a supervised manner to classify a specific location into a particular region based on the RSSI values collected at that location. Most of the ML algorithms that perform this classification require a large number of labeled data points (RSSI vectors with location information). Collecting such data points is a labor-intensive and time-consuming task. To overcome this challenge, as our second contribution, we demonstrate the performance of IndoorGNN on the restricted dataset. It shows a comparable prediction accuracy to that of the complete dataset. We performed experiments on the UJIIndoorLoc and MNAV datasets, which are real-world standard indoor localization datasets. Our experiments show that IndoorGNN gives better location prediction accuracies when compared with state-of-the-art existing conventional as well as GNN-based methods for this same task. It continues to outperform these algorithms even with restricted datasets. It is noteworthy that its performance does not decrease a lot with a decrease in the number of available data points. Our method can be utilized for navigation and wayfinding in complex indoor environments, asset tracking and building management, enhancing mobile applications with location-based services, and improving safety and security during emergencies.
Hunting Group Clues with Transformers for Social Group Activity Recognition
Jul 12, 2022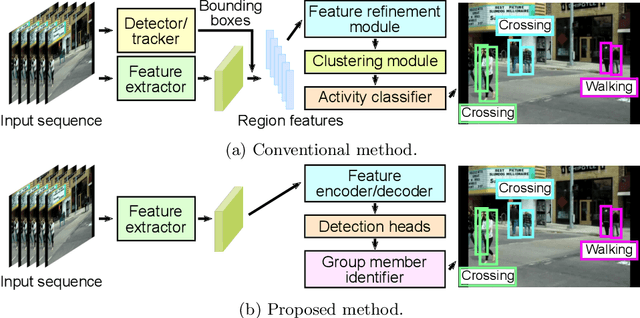
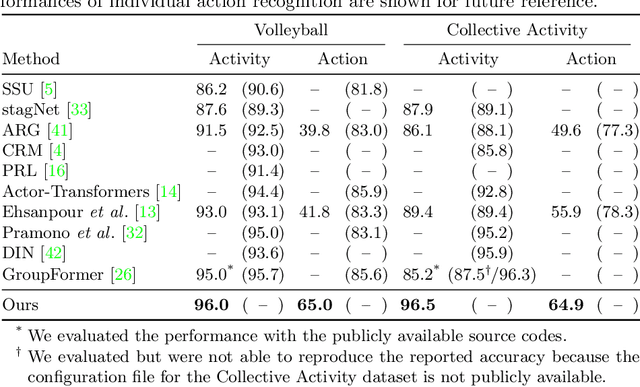
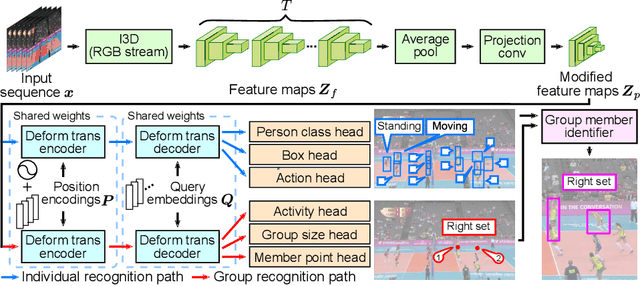
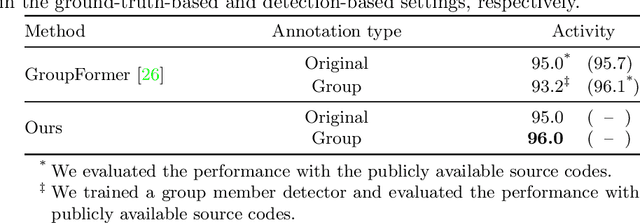
This paper presents a novel framework for social group activity recognition. As an expanded task of group activity recognition, social group activity recognition requires recognizing multiple sub-group activities and identifying group members. Most existing methods tackle both tasks by refining region features and then summarizing them into activity features. Such heuristic feature design renders the effectiveness of features susceptible to incomplete person localization and disregards the importance of scene contexts. Furthermore, region features are sub-optimal to identify group members because the features may be dominated by those of people in the regions and have different semantics. To overcome these drawbacks, we propose to leverage attention modules in transformers to generate effective social group features. Our method is designed in such a way that the attention modules identify and then aggregate features relevant to social group activities, generating an effective feature for each social group. Group member information is embedded into the features and thus accessed by feed-forward networks. The outputs of feed-forward networks represent groups so concisely that group members can be identified with simple Hungarian matching between groups and individuals. Experimental results show that our method outperforms state-of-the-art methods on the Volleyball and Collective Activity datasets.
CNN Model & Tuning for Global Road Damage Detection
Mar 17, 2021



This paper provides a report on our solution including model selection, tuning strategy and results obtained for Global Road Damage Detection Challenge. This Big Data Cup Challenge was held as a part of IEEE International Conference on Big Data 2020. We assess single and multi-stage network architectures for object detection and provide a benchmark using popular state-of-the-art open-source PyTorch frameworks like Detectron2 and Yolov5. Data preparation for provided Road Damage training dataset, captured using smartphone camera from Czech, India and Japan is discussed. We studied the effect of training on a per country basis with respect to a single generalizable model. We briefly describe the tuning strategy for the experiments conducted on two-stage Faster R-CNN with Deep Residual Network (Resnet) and Feature Pyramid Network (FPN) backbone. Additionally, we compare this to a one-stage Yolov5 model with Cross Stage Partial Network (CSPNet) backbone. We show a mean F1 score of 0.542 on Test2 and 0.536 on Test1 datasets using a multi-stage Faster R-CNN model, with Resnet-50 and Resnet-101 backbones respectively. This shows the generalizability of the Resnet-50 model when compared to its more complex counterparts. Experiments were conducted using Google Colab having K80 and a Linux PC with 1080Ti, NVIDIA consumer grade GPU. A PyTorch based Detectron2 code to preprocess, train, test and submit the Avg F1 score to is made available at https://github.com/vishwakarmarhl/rdd2020