 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunting Group Clues with Transformers for Social Group Activity Recognition
Jul 12, 2022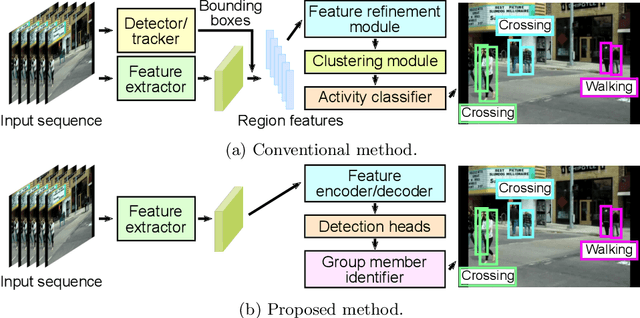
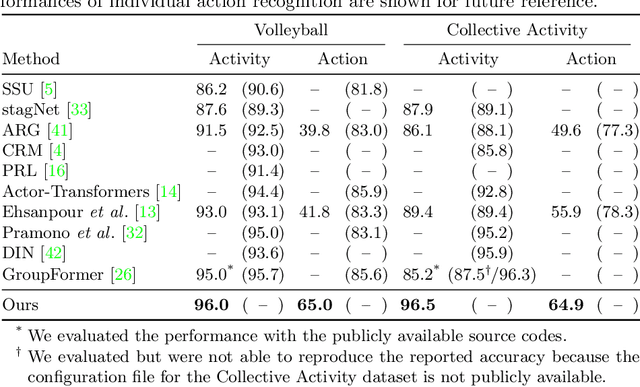
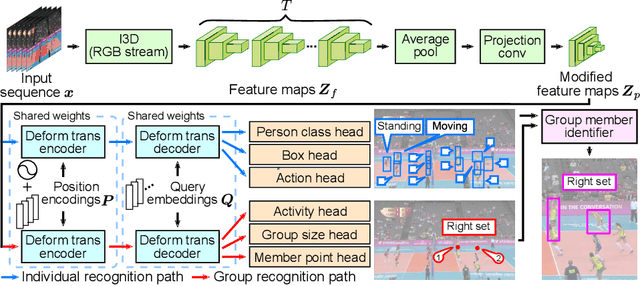
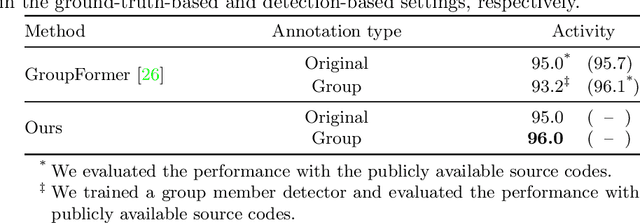
This paper presents a novel framework for social group activity recognition. As an expanded task of group activity recognition, social group activity recognition requires recognizing multiple sub-group activities and identifying group members. Most existing methods tackle both tasks by refining region features and then summarizing them into activity features. Such heuristic feature design renders the effectiveness of features susceptible to incomplete person localization and disregards the importance of scene contexts. Furthermore, region features are sub-optimal to identify group members because the features may be dominated by those of people in the regions and have different semantics. To overcome these drawbacks, we propose to leverage attention modules in transformers to generate effective social group features. Our method is designed in such a way that the attention modules identify and then aggregate features relevant to social group activities, generating an effective feature for each social group. Group member information is embedded into the features and thus accessed by feed-forward networks. The outputs of feed-forward networks represent groups so concisely that group members can be identified with simple Hungarian matching between groups and individuals. Experimental results show that our method outperforms state-of-the-art methods on the Volleyball and Collective Activity datasets.
CNN Model & Tuning for Global Road Damage Detection
Mar 17, 2021



This paper provides a report on our solution including model selection, tuning strategy and results obtained for Global Road Damage Detection Challenge. This Big Data Cup Challenge was held as a part of IEEE International Conference on Big Data 2020. We assess single and multi-stage network architectures for object detection and provide a benchmark using popular state-of-the-art open-source PyTorch frameworks like Detectron2 and Yolov5. Data preparation for provided Road Damage training dataset, captured using smartphone camera from Czech, India and Japan is discussed. We studied the effect of training on a per country basis with respect to a single generalizable model. We briefly describe the tuning strategy for the experiments conducted on two-stage Faster R-CNN with Deep Residual Network (Resnet) and Feature Pyramid Network (FPN) backbone. Additionally, we compare this to a one-stage Yolov5 model with Cross Stage Partial Network (CSPNet) backbone. We show a mean F1 score of 0.542 on Test2 and 0.536 on Test1 datasets using a multi-stage Faster R-CNN model, with Resnet-50 and Resnet-101 backbones respectively. This shows the generalizability of the Resnet-50 model when compared to its more complex counterparts. Experiments were conducted using Google Colab having K80 and a Linux PC with 1080Ti, NVIDIA consumer grade GPU. A PyTorch based Detectron2 code to preprocess, train, test and submit the Avg F1 score to is made available at https://github.com/vishwakarmarhl/rdd2020