 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemHC-GNN: Manifold-Constrained Hyper-Connections for Graph Neural Networks
Jan 05, 2026Graph Neural Networks (GNNs) suffer from over-smoothing in deep architectures and expressiveness bounded by the 1-Weisfeiler-Leman (1-WL) test. We adapt Manifold-Constrained Hyper-Connections (\mhc)~\citep{xie2025mhc}, recently proposed for Transformers, to graph neural networks. Our method, mHC-GNN, expands node representations across $n$ parallel streams and constrains stream-mixing matrices to the Birkhoff polytope via Sinkhorn-Knopp normalization. We prove that mHC-GNN exhibits exponentially slower over-smoothing (rate $(1-γ)^{L/n}$ vs.\ $(1-γ)^L$) and can distinguish graphs beyond 1-WL. Experiments on 10 datasets with 4 GNN architectures show consistent improvements. Depth experiments from 2 to 128 layers reveal that standard GNNs collapse to near-random performance beyond 16 layers, while mHC-GNN maintains over 74\% accuracy even at 128 layers, with improvements exceeding 50 percentage points at extreme depths. Ablations confirm that the manifold constraint is essential: removing it causes up to 82\% performance degradation. Code is available at \href{https://github.com/smlab-niser/mhc-gnn}{https://github.com/smlab-niser/mhc-gnn}
Clean-GS: Semantic Mask-Guided Pruning for 3D Gaussian Splatting
Jan 01, 20263D Gaussian Splatting produces high-quality scene reconstructions but generates hundreds of thousands of spurious Gaussians (floaters) scattered throughout the environment. These artifacts obscure objects of interest and inflate model sizes, hindering deployment in bandwidth-constrained applications. We present Clean-GS, a method for removing background clutter and floaters from 3DGS reconstructions using sparse semantic masks. Our approach combines whitelist-based spatial filtering with color-guided validation and outlier removal to achieve 60-80\% model compression while preserving object quality. Unlike existing 3DGS pruning methods that rely on global importance metrics, Clean-GS uses semantic information from as few as 3 segmentation masks (1\% of views) to identify and remove Gaussians not belonging to the target object. Our multi-stage approach consisting of (1) whitelist filtering via projection to masked regions, (2) depth-buffered color validation, and (3) neighbor-based outlier removal isolates monuments and objects from complex outdoor scenes. Experiments on Tanks and Temples show that Clean-GS reduces file sizes from 125MB to 47MB while maintaining rendering quality, making 3DGS models practical for web deployment and AR/VR applications. Our code is available at https://github.com/smlab-niser/clean-gs
Robustness in Large Language Models: A Survey of Mitigation Strategies and Evaluation Metrics
May 24, 2025Large Language Models (LLMs) have emerged as a promising cornerstone for the development of natural language processing (NLP) and artificial intelligence (AI). However, ensuring the robustness of LLMs remains a critical challenge. To address these challenges and advance the field, this survey provides a comprehensive overview of current studies in this area. First, we systematically examine the nature of robustness in LLMs, including its conceptual foundations, the importance of consistent performance across diverse inputs, and the implications of failure modes in real-world applications. Next, we analyze the sources of non-robustness, categorizing intrinsic model limitations, data-driven vulnerabilities, and external adversarial factors that compromise reliability. Following this, we review state-of-the-art mitigation strategies, and then we discuss widely adopted benchmarks, emerging metrics, and persistent gaps in assessing real-world reliability. Finally, we synthesize findings from existing surveys and interdisciplinary studies to highlight trends, unresolved issues, and pathways for future research.
Retinal Fundus Multi-Disease Image Classification using Hybrid CNN-Transformer-Ensemble Architectures
Mar 27, 2025Our research is motivated by the urgent global issue of a large population affected by retinal diseases, which are evenly distributed but underserved by specialized medical expertise, particularly in non-urban areas. Our primary objective is to bridge this healthcare gap by developing a comprehensive diagnostic system capable of accurately predicting retinal diseases solely from fundus images. However, we faced significant challenges due to limited, diverse datasets and imbalanced class distributions. To overcome these issues, we have devised innovative strategies. Our research introduces novel approaches, utilizing hybrid models combining deeper Convolutional Neural Networks (CNNs), Transformer encoders, and ensemble architectures sequentially and in parallel to classify retinal fundus images into 20 disease labels. Our overarching goal is to assess these advanced models' potential in practical applications, with a strong focus on enhancing retinal disease diagnosis accuracy across a broader spectrum of conditions. Importantly, our efforts have surpassed baseline model results, with the C-Tran ensemble model emerging as the leader, achieving a remarkable model score of 0.9166, surpassing the baseline score of 0.9. Additionally, experiments with the IEViT model showcased equally promising outcomes with improved computational efficiency. We've also demonstrated the effectiveness of dynamic patch extraction and the integration of domain knowledge in computer vision tasks. In summary, our research strives to contribute significantly to retinal disease diagnosis, addressing the critical need for accessible healthcare solutions in underserved regions while aiming for comprehensive and accurate disease prediction.
* 17 pages, 3 figures, 7 tables. Conference paper presented at the International Health Informatics Conference (IHIC 2023)
Graph Neural Networks at a Fraction
Feb 10, 2025



Graph Neural Networks (GNNs) have emerged as powerful tools for learning representations of graph-structured data. In addition to real-valued GNNs, quaternion GNNs also perform well on tasks on graph-structured data. With the aim of reducing the energy footprint, we reduce the model size while maintaining accuracy comparable to that of the original-sized GNNs. This paper introduces Quaternion Message Passing Neural Networks (QMPNNs), a framework that leverages quaternion space to compute node representations. Our approach offers a generalizable method for incorporating quaternion representations into GNN architectures at one-fourth of the original parameter count. Furthermore, we present a novel perspective on Graph Lottery Tickets, redefining their applicability within the context of GNNs and QMPNNs. We specifically aim to find the initialization lottery from the subnetwork of the GNNs that can achieve comparable performance to the original GNN upon training. Thereby reducing the trainable model parameters even further. To validate the effectiveness of our proposed QMPNN framework and LTH for both GNNs and QMPNNs, we evaluate their performance on real-world datasets across three fundamental graph-based tasks: node classification, link prediction, and graph classification.
A Survey on Robotic Prosthetics: Neuroprosthetics, Soft Actuators, and Control Strategies
Aug 03, 2024
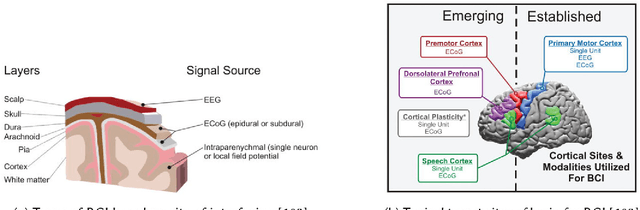

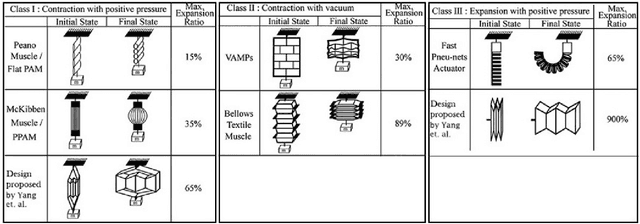
The field of robotics is a quickly evolving feat of technology that accepts contributions from various genres of science. Neuroscience, Physiology, Chemistry, Material science, Computer science, and the wide umbrella of mechatronics have all simultaneously contributed to many innovations in the prosthetic applications of robotics. This review begins with a discussion of the scope of the term robotic prosthetics and discusses the evolving domain of Neuroprosthetics. The discussion is then constrained to focus on various actuation and control strategies for robotic prosthetic limbs. This review discusses various soft robotic actuators such as EAP, SMA, FFA, etc., and the merits of such actuators over conventional hard robotic actuators. Options in control strategies for robotic prosthetics, that are in various states of research and development, are reviewed. This paper concludes the discussion with an analysis regarding the prospective direction in which this field of robotic prosthetics is evolving in terms of actuation, control, and other features relevant to artificial limbs. This paper intends to review some of the emerging research and development trends in the field of robotic prosthetics and summarize many tangents that are represented under this broad domain in an approachable manner.
Estimation of Electronic Band Gap Energy From Material Properties Using Machine Learning
Mar 08, 2024Machine learning techniques are utilized to estimate the electronic band gap energy and forecast the band gap category of materials based on experimentally quantifiable properties. The determination of band gap energy is critical for discerning various material properties, such as its metallic nature, and potential applications in electronic and optoelectronic devices. While numerical methods exist for computing band gap energy, they often entail high computational costs and have limitations in accuracy and scalability. A machine learning-driven model capable of swiftly predicting material band gap energy using easily obtainable experimental properties would offer a superior alternative to conventional density functional theory (DFT) methods. Our model does not require any preliminary DFT-based calculation or knowledge of the structure of the material. We present a scheme for improving the performance of simple regression and classification models by partitioning the dataset into multiple clusters. A new evaluation scheme for comparing the performance of ML-based models in material sciences involving both regression and classification tasks is introduced based on traditional evaluation metrics. It is shown that on this new evaluation metric, our method of clustering the dataset results in better performance.
Enhancing Neural Theorem Proving through Data Augmentation and Dynamic Sampling Method
Dec 20, 2023



Theorem proving is a fundamental task in mathematics. With the advent of large language models (LLMs) and interactive theorem provers (ITPs) like Lean, there has been growing interest in integrating LLMs and ITPs to automate theorem proving. In this approach, the LLM generates proof steps (tactics), and the ITP checks the applicability of the tactics at the current goal. The two systems work together to complete the proof. In this paper, we introduce DS-Prover, a novel dynamic sampling method for theorem proving. This method dynamically determines the number of tactics to apply to expand the current goal, taking into account the remaining time compared to the total allocated time for proving a theorem. This makes the proof search process more efficient by adjusting the balance between exploration and exploitation as time passes. We also augment the training dataset by decomposing simplification and rewrite tactics with multiple premises into tactics with single premises. This gives the model more examples to learn from and helps it to predict the tactics with premises more accurately. We perform our experiments using the Mathlib dataset of the Lean theorem prover and report the performance on two standard datasets, MiniF2F and ProofNet. Our methods achieve significant performance gains on both datasets. We achieved a state-of-the-art performance (Pass@1) of 14.2% on the ProofNet dataset and a performance of 29.8% on MiniF2F, slightly surpassing the best-reported Pass@1 of 29.6% using Lean.
IndoorGNN: A Graph Neural Network based approach for Indoor Localization using WiFi RSSI
Dec 11, 2023Indoor localization is the process of determining the location of a person or object inside a building. Potential usage of indoor localization includes navigation, personalization, safety and security, and asset tracking. Commonly used technologies for indoor localization include WiFi, Bluetooth, RFID, and Ultra-wideband. Among these, WiFi's Received Signal Strength Indicator (RSSI)-based localization is preferred because of widely available WiFi Access Points (APs). We have two main contributions. First, we develop our method, 'IndoorGNN' which involves using a Graph Neural Network (GNN) based algorithm in a supervised manner to classify a specific location into a particular region based on the RSSI values collected at that location. Most of the ML algorithms that perform this classification require a large number of labeled data points (RSSI vectors with location information). Collecting such data points is a labor-intensive and time-consuming task. To overcome this challenge, as our second contribution, we demonstrate the performance of IndoorGNN on the restricted dataset. It shows a comparable prediction accuracy to that of the complete dataset. We performed experiments on the UJIIndoorLoc and MNAV datasets, which are real-world standard indoor localization datasets. Our experiments show that IndoorGNN gives better location prediction accuracies when compared with state-of-the-art existing conventional as well as GNN-based methods for this same task. It continues to outperform these algorithms even with restricted datasets. It is noteworthy that its performance does not decrease a lot with a decrease in the number of available data points. Our method can be utilized for navigation and wayfinding in complex indoor environments, asset tracking and building management, enhancing mobile applications with location-based services, and improving safety and security during emergencies.
Perceiving University Student's Opinions from Google App Reviews
Dec 10, 2023Google app market captures the school of thought of users from every corner of the globe via ratings and text reviews, in a multilinguistic arena. The potential information from the reviews cannot be extracted manually, due to its exponential growth. So, Sentiment analysis, by machine learning and deep learning algorithms employing NLP, explicitly uncovers and interprets the emotions. This study performs the sentiment classification of the app reviews and identifies the university student's behavior towards the app market via exploratory analysis. We applied machine learning algorithms using the TP, TF, and TF IDF text representation scheme and evaluated its performance on Bagging, an ensemble learning method. We used word embedding, Glove, on the deep learning paradigms. Our model was trained on Google app reviews and tested on Student's App Reviews(SAR). The various combinations of these algorithms were compared amongst each other using F score and accuracy and inferences were highlighted graphically. SVM, amongst other classifiers, gave fruitful accuracy(93.41%), F score(89%) on bigram and TF IDF scheme. Bagging enhanced the performance of LR and NB with accuracy of 87.88% and 86.69% and F score of 86% and 78% respectively. Overall, LSTM on Glove embedding recorded the highest accuracy(95.2%) and F score(88%).
* Accepted in Concurrency and Computation Practice and Experience